2017年に、時系列データの学術的な性質に関するブログを投稿しました。今回のブログでは、2017年のブログに引き続き、時系列データベースとその中に保存されているデータについて実践的に紹介します。
Googleトレンドチャートを見ると、データストレージシステムの進歩と近年のビッグデータ革命により、時系列データベースへの関心が再び高まっていることが推測できます。
時系列データとは何か?
時系列データは、時間情報(タイムスタンプ)が記録されたデータまたはその時点で発生したイベントに対応する一連の値です。 データの間隔は、定期的な間隔と変動する間隔どちらに設定することもできます。 たとえば、温度記録は設定された時間、毎分または毎時間に記録され、株価は取引が完了するたびに記録されます。

時系列データは通常、ログまたは「追加専用」であり、レコードは、有効期限が切れた場合の削除を除き、めったに更新されません。 Webサーバーのログの値を更新することはなく、ほとんどの時系列データコレクションについても同様です。
必要なレイテンシーに応じて、個々のレコードを一度に1つずつ挿入できますが、多くの場合、一括で挿入されます。 Kafkaなどのメッセージングシステムは、個別のレコードを一括で挿入するためにキューに入れたり、クライアントアプリケーションを一定期間に1回挿入するようにキャッシュを構成したりすることができます。
時系列データベースとは何か?
簡潔に言うと、時系列データベースは時系列データの保存とクエリに特化したデータベースです。他のリレーショナルデータベースやNoSQLデータベースに格納してクエリを実行することは可能ですが、時系列データベースには、次のような優れた時間関連の機能があります。
どのようなアプリケーションで時系列データを使用するか?
ほぼすべてのデータが時系列データになり得ると言えます。 たとえば、購入したい製品の現在の価格だけを気にすることもできますが、その製品の過去の価格を確認して、セールになるまで待つべきかどうかを判断することもできます。したがって、通常はドキュメント指向のデータベースに格納される製品情報は、時系列データベースに格納するのにも部分的に適していると言えるでしょう。
Internet of Things
IoT(Internet of Things)は、センサーデータを記録する何百万ものデバイスを持つ時系列データのユーザーの間で最も話題になっていると言えるかもしれません。 典型的な例として、温度や、ドアのロックやロック解除などの環境イベントの生成などがあります。 膨大な量のデータが記録されるため、時系列データベースを使用して、着信データを効率的に保存、処理、分析することが不可欠です。GridDBのKey-Containerデータモデルは、各デバイスの時系列データが個別のコンテナーに保存されるIoTワークロードで特にうまく機能します。
金融取引
金融の勘定元帳は、時系列で貸方・借方、および残高を追跡するという点で元祖の時系列データベースであると言えるかもしれません。領収書または販売履歴にはすべてメトリックがあります。株式取引も時系列データモデルによく適合しており、最新の値と過去のすべての取引価格とボリュームのいずれもが重要な意味を持ちます。

アプリケーションモニタリング
サーバーログは、時系列データの最も単純明白な例の1つですが、使用されるアプリケーションモニタリングの種類は様々です。 モバイルアプリケーションによってアップロードされたテレメトリは時系列データベースに保存できるため、開発者は使用パターンを調べてアプリケーションを改善できます。サーバーメトリックを監視して、ピークとトラフの使用状況を確認し、システム管理者が容量が十分であるか確認するだけでなく、異常がないか調べることもできます。
時系列データをどのように使用するか?
ここまでに、なぜ時系列データベースが重要であるかの理由と、どのような時系列データが使われるかについて説明してきました。ここでは時系列データをどのように使用するかについて説明します。
時系列アプリケーションの例
ここまでで、時系列データがみなさんが当初想像していたよりも重要なものであることがお分かりいただけたでしょうか。IoTの新興産業は全体的に時系列データに依存しています。そのため、車両管理システムを構築したり、あるいは次世代スマートシティを計画するにあたり、時系列データとその管理が、すべてを適切かつ効率的に実行するための重要な要素になるでしょう。
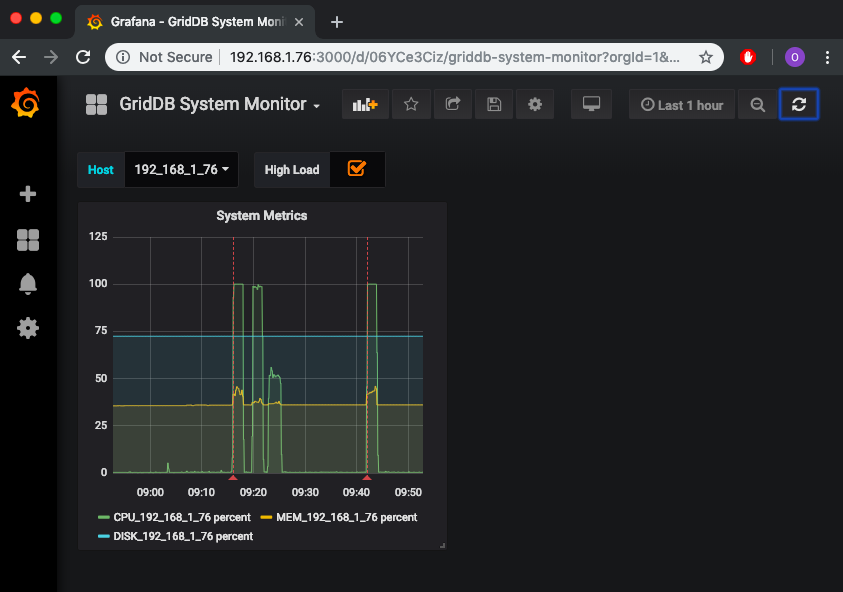
上記のような新興産業のアプリケーションでは、最新のロギング・分析アプリケーションもますます複雑になり、データを大量に消費するようになりました。たとえば、Grafanaは、優秀であり、時系列データベースの基盤の上に構築されています。プロジェクトページをチェックして、GridDBがGrafanaとどのように連携するかを確認してください。今すぐGridDBを使い始めて、アプリケーションでより速く、そして増え続ける時系列データでより大きく成長するのがいかに簡単かを見てください。
ブログの内容について疑問や質問がある場合は Q&A サイトである Stack Overflow に質問を投稿しましょう。 GridDB 開発者やエンジニアから速やかな回答が得られるようにするためにも "griddb" タグをつけることをお忘れなく。 https://stackoverflow.com/questions/ask?tags=griddb
