
脳卒中は、脳からの血流および脳への血流が途絶えることによって起こる重篤な脳血管障害です。脳が正しく機能するための酸素と栄養を受け取ることができなくなります。逆に、脳は死んだ細胞のような老廃物をすべて排出することができません。数分後には、脳細胞が死滅し始めるので、脳は危機的な状況に陥ってしまうのです。
米国脳卒中協会 (American Stroke Association) は、脳卒中は米国における死亡および身体障害の原因の第5位であることを示しています。この為、脳卒中は重篤な疾患とされ、医療分野だけでなく、データサイエンスや機械学習の研究でも盛んに研究が行われています。本稿では、PythonとGridDBを用いて、患者の記録が与えられた脳卒中疾患を予測する機械学習モデルを提案します。
環境の設定
この記事で紹介するソリューションを実現するため、まずは紹介するコードを正しく実行するためにマシンに正しい環境を設定することから始めます。ここでは、環境に設定する必要がある要件をいくつか紹介します。
-
Windows 10 : メインOSとしてWindows10を使用しています。
-
GridDB : 機械学習モデルで使用するデータを格納するメインデータベースとして、GridDBを使用しています。
-
Python 3.9 : PythonとAnaconda Navigatorのおかげで、分離された作業環境を展開することができます。
-
Jupyter Notebook : Pythonセルを実行するためのメインコンピューティングプラットフォームとして使用されています。
-
Microsoft Visual C++ 14.0 もしくはそれ以降のバージョン : GridDBがJupyter Notebook上でコマンドを実行するために使用するJPype1が必要です。
-
最後に、Jupyter Notebookで使用するために必要なライブラリがあればインストールします。私たちの場合、
JPype1,scikit-plot,imblearnが不足しています。以下は、Jupyterのターミナルで、pipコマンドを使用して、不足しているライブラリをインストールする方法です。
pip install imblearn
pip install scikit-plot
pip install JayDeBeApi JPype1==0.6.3
pip install pywaffle環境のインストールと設定が完了したら、早速データセットにアクセスしてみましょう。
データセットの紹介
この記事で使用するデータセットには、5110件の患者のレコードが含まれています。各患者は12の列を持ち、それぞれが具体的な属性を参照しています。これらの属性のほとんどは、医療記録や臨床試験の結果に対応しています。 主な属性としては、高血圧、心臓病、血中平均グルコース値、BMI(Body Mass Index)などがあります。これらの最初の属性から分かるように、このデータセットは、患者が脳卒中疾患に罹患する可能性に関する関連データを提供しています。グルコースレベルとBMIが高く、心臓病や高血圧に罹患している患者は、脳卒中に罹患する可能性が高いことは容易に理解できます。実際、脳卒中もこのデータセットの属性であり、各医療記録において、患者が脳卒中疾患に罹患しているかどうかを示しています。
データセットは Kaggle から入手したもので、ダウンロードが可能です。以下の表は、この記事で使用したデータセットの抜粋です。

必要なライブラリのインポート
今回は、複数のPythonライブラリを使用するため、その使用方法について整理してみます。
- 線形代数やデータ処理のためのライブラリ
import numpy as np
import pandas as pd- グラフ描画用ライブラリ
import matplotlib.pyplot as plt
import matplotlib.ticker as mtick
import matplotlib.gridspec as grid_spec
import seaborn as sns
from imblearn.over_sampling import SMOTE
import scikitplot as skplt- モデル構築のためのライブラリ
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler,LabelEncoder
from sklearn.model_selection import train_test_split,cross_val_score
from sklearn.metrics import classification_report, confusion_matrix
from sklearn.metrics import accuracy_score, recall_score, roc_auc_score, precision_score, f1_score- さまざまなアルゴリズムでモデルを評価するためのライブラリ
from sklearn.linear_model import LinearRegression,LogisticRegression
from sklearn.tree import DecisionTreeRegressor,DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier- Jupyter NotebookでGridDBからデータを読み込むためのライブラリ
import jaydebeapi必要なライブラリのインポートに成功したら、まずはデータセットの読み込みを行います。
データセットの読み込み
データセットをロードするために、次の段落でより詳細に説明される2つのオプションがあります。
本記事では、すでにGridDBコンテナを設計し、データをロードしています。データを書き込む場合は、「GridDB上でPandasのデータフレームを使用する」 の記事が役に立ちます。
ただし、今回はPandasを使ってGridDBからデータを読み込むのではなく、Jupyter NotebookからGridDBのJDBCコネクタを使って直接この操作を実現します。「Querying IoT dataset in Jupyter Notebook」 という記事が参考になると思います。以下は、これを実現するためのコードです。
def query_sensor(curs, table):
curs.execute("select count(*) from "+table)
return curs.fetchall()[0][0]
conn = jaydebeapi.connect("com.toshiba.mwcloud.gs.sql.Driver", "jdbc:gs://239.0.0.1:41999/defaultCluster", ["admin", "admin"], "gridstore-jdbc-4.6.0.jar")
curs = conn.cursor()
curs.execute("select * from \"#tables\"")
tables = []
data = []
for table in curs.fetchall():
try:
if table[1].split("_")[1].startswith("M"):
tables.append(table[1])
data.append(query_sensor(curs, table[1]))
except:
passまた、KaggleからダウンロードしたCSVファイルを使ってデータセットを読み込むこともできます。このファイルをJupyterプロジェクトのルートディレクトリに配置することで、使用できるようになるはずです。
df = pd.read_csv('healthcare-dataset-stroke-data.csv')今回は、変数 df で提供されるデータで話を進めましょう。
探索的データ解析
機械学習モデルの構築を進める前に、まずデータの不整合を発見するための探索的データ解析と、データセット全体の可視化から始める必要があります。
まず、データセットにNULL値があるかどうかをチェックします。これは次のようなコードで実現します。
df.isnull().sum()このセルから以下の結果が出力され、BMI 属性に 201 個の欠損値があることがわかります。
id 0
gender 0
age 0
hypertension 0
heart_disease 0
ever_married 0
work_type 0
Residence_type 0
avg_glucose_level 0
bmi 201
smoking_status 0
stroke 0
dtype: int64この場合、単純に欠損値を削除することもできますが、 Kaggle notebook に記載されている方法で、欠損エントリのBMI値を予測するために決定木を使用します。これは以下のコードで実現します。
DT_bmi_pipe = Pipeline( steps=[
('scale',StandardScaler()),
('lr',DecisionTreeRegressor(random_state=42))
])
X = df[['age','gender','bmi']].copy()
X.gender = X.gender.replace({'Male':0,'Female':1,'Other':-1}).astype(np.uint8)
Missing = X[X.bmi.isna()]
X = X[~X.bmi.isna()]
Y = X.pop('bmi')
DT_bmi_pipe.fit(X,Y)
predicted_bmi = pd.Series(DT_bmi_pipe.predict(Missing[['age','gender']]),index=Missing.index)
df.loc[Missing.index,'bmi'] = predicted_bmiこれで、すべての欠損値を置き換えたので、データの可視化に移ることができます。最初のグラフは、年齢、平均グルコース・レベル、BMIの3つの重要な属性の数値変数の分布を提供します。このプロットは、頻繁に起こる年齢範囲、グルコースレベル、BMIを検出することができ、データの明確な最初の可視化を提供します。このプロットを生成するために使用したコードは、この記事の 公開リポジトリ のノートブックに添付されています。
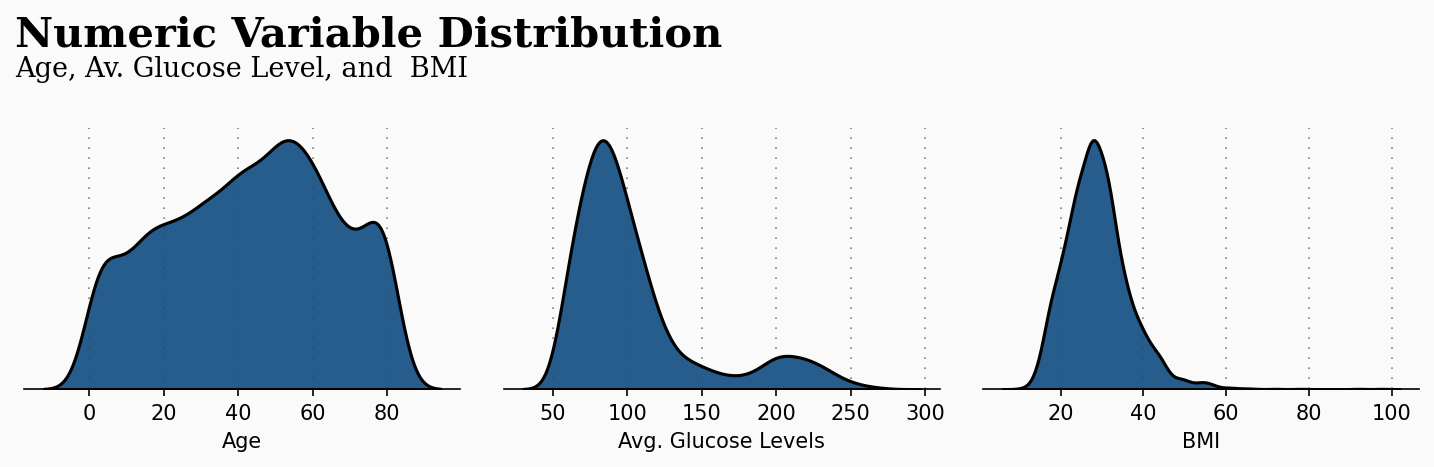
このプロットは、今回の研究に適用すると、より重要な意味を持ちます。次のプロットは、前の数値属性と脳卒中になったかどうかの患者の状態との関係を作るものです。このプロットは我々に大きな洞察を与えてくれます。
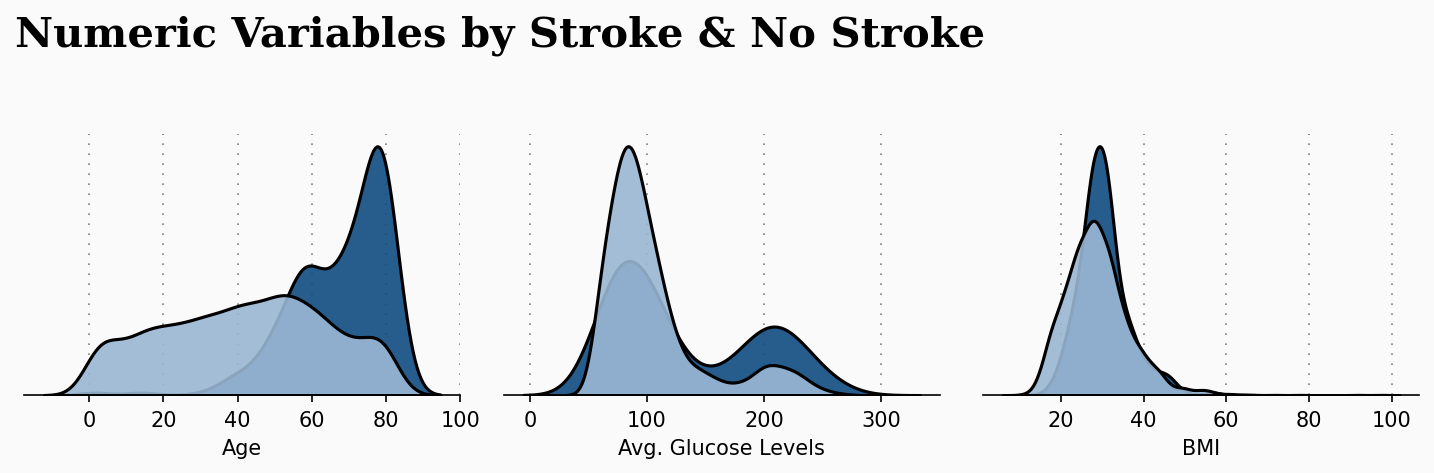
脳卒中発作のリスクを高めるには、年齢が決定的な要因になるようです。年齢が高いほど、脳卒中にかかる可能性が高くなることが観察されます。
機械学習モデル
このセクションでは、機械学習モデルを設計し、準備します。この目的のために、我々はデータセットに存在するカテゴリ変数を符号化することから始めましょう。これらは、性別、居住形態、仕事の種類を含みます。この作業は以下のコードで実現します。
df['gender'] = df['gender'].replace({'Male':0,'Female':1,'Other':-1}).astype(np.uint8)
df['Residence_type'] = df['Residence_type'].replace({'Rural':0,'Urban':1}).astype(np.uint8)
df['work_type'] = df['work_type'].replace({'Private':0,'Self-employed':1,'Govt_job':2,'children':-1,'Never_worked':-2}).astype(np.uint8)さて、データセットの準備ができたので、次はデータをトレーニングデータとテストデータに分割していきます。また、正しく予測を行うために、データセットに stoke 属性が存在しないことを確認する必要があります。これは以下のコードで実現できます。
X = df[['gender','age','hypertension','heart_disease','work_type','avg_glucose_level','bmi']]y = df['stroke']
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, train_size=0.3, random_state=42)この記事で紹介したデータセットは、バランスが良くありません。我々は、データセットが偏っていることを検出したので、この問題を解決するためにSMOTE (Synthetic Minority Over-sampling Technique) を選択しました。以下のコードでは、SMOTEオーバーサンプリングをデータセットに適用し、バランスの取れたデータセットに仕上げています。
oversample = SMOTE()
X_train_resh, y_train_resh = oversample.fit_resample(X_train, y_train.ravel())モデル評価
この時点で、私たちのモデルを評価する準備が整いました。この例では、前のセクションで設計されたモデルを評価するために、ランダムフォレスト・アルゴリズムを使用します。実際には、ロジスティック回帰のような他の分類モデルも使用できますが、ランダムフォレストが最も高い精度を得ることができることに気付きました。まず、以下のコードにより、パイプラインでデータをスケーリングし、分割するところから始めます。
rf_pipeline = Pipeline(steps = [('scale',StandardScaler()),('RF',RandomForestClassifier(random_state=42))])アルゴリズムを実行するために、10倍クロスバリデーションを使用します。
print('Random Forest mean :',cross_val_score(rf_pipeline,X_train_resh,y_train_resh,cv=10,scoring='f1').mean())前の行は、次のような結果を出力します。
Random Forest mean: 0.9342717632419655このように、ランダムフォレストモデルは、脳卒中の患者記録を予測する際に、93%の精度を達成することが出来ました。
結論
医学的な研究と機械学習やデータサイエンスの研究を組み合わせることで、さまざまな病気に対してこれまでにない洞察を得ることができます。今回は、人間の脳の正しい働きに影響を与える重篤な病気である脳卒中疾患に罹患した医療患者の可能性を予測するために、機械学習モデルを使用することを検討しました。
参考
- https://www.stroke.org/en/
- https://github.com/almahdibakkali96/Stroke-Prediction-using-Machine-Learning-Python-and-GridDB-
- https://www.kaggle.com/code/joshuaswords/predicting-a-stroke-shap-lime-explainer-eli5
- https://www.kaggle.com/code/thomaskonstantin/analyzing-and-modeling-stroke-data/notebook
ブログの内容について疑問や質問がある場合は Q&A サイトである Stack Overflow に質問を投稿しましょう。 GridDB 開発者やエンジニアから速やかな回答が得られるようにするためにも "griddb" タグをつけることをお忘れなく。 https://stackoverflow.com/questions/ask?tags=griddb