このチュートリアルでは、Pythonを使ってGridDBに格納された時系列データを解析する方法を説明します。チュートリアルの概要は以下の通りです。
- SQLとPandasを使ってデータセットを読み込む
- NULLや欠損値などに対応するためにデータの前処理を行う
- データに対する分類を構築する
前提条件
このチュートリアルでは、GridDB、Python3、および関連するライブラリが事前にインストールされていることを前提としています。以下のパッケージがインストールされていない場合は、チュートリアルを進める前にインストールしてください。1. GridDB 2. Python 3 3. GridDB Python Client 4. NumPy 5. Pandas 6. Matplotlib 7. Scikit-learn 8. Lightgbm 9. Seaborn
以下のチュートリアルは、Jupyter notebooks (Anaconda Navigator)で行われます。これらのパッケージは、conda install package_nameを使って、あなたの環境に直接インストールすることができます。あるいは、コマンドプロンプト、ターミナルで pip install package_name と入力してください。
必要なライブラリをインポートする
必要なパッケージのインストールが完了したら、次に以下のライブラリをインポートしてください。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.preprocessing import *
from sklearn.model_selection import *
from sklearn.metrics import *
import os
from datetime import datetime
import time
from lightgbm import LGBMRegressor
import seaborn as sns
from sklearn import metricsAPP_PATH = os.getcwd()
APP_PATH'C:\Users\SHRIPRIYA\Desktop\AW Group\GridDB'
データセットを読み込む
このチュートリアルで使用している時系列データセットは、Kaggleでオープンソース化されています。zipフォルダには、トレーニング用とテスト用の2つのファイルが入っています。しかし、テストデータセットにはラベルが含まれていないため、モデルの性能を検証することができません。そのため、今回はトレーニング用のファイルを全体のデータセットとして使用し、後にトレーニング用とテスト用に分けて使用します。
学習ファイルは約48000行(またはインスタンス)で、4つの列(または属性)すなわちID, DateTime, Junction, and Vehiclesがあります。Vehicle列は従属変数(または応答変数)で、DateTime and Junctionは独立変数(または説明変数)です。
SQLを使う
Pythonスクリプトやコンソールで以下のような文を入力することで、GridDB からデータを取得することができます。GridDBのpythonクライアントを使う利点は、結果として得られるデータ型がpandasのdataframeであることです。これにより、データ操作が非常に簡単になります。
statement = ('SELECT * FROM train_ml_iot')
dataset = pd.read_sql_query(statement, cont)
出力は以下のようになります。
データセットの概要を知る
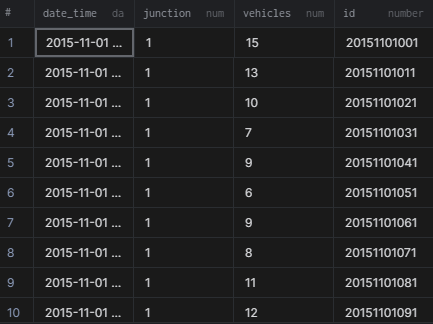
さて、データセットを読み込んだところで、いよいよその中身を見てみましょう。headコマンドを使って、最初の5行を表示することができます。もっと多くの行を表示したい場合は、関数の引数に数字を入力します。例えば、dataset.head(15)とすると、最初の15行を表示することができます。他にも、tailコマンドを使って最後の5行を表示する方法もあります。
dataset.head()| DateTime | Junction | Vehicles | ID | |
|---|---|---|---|---|
| 0 | 2015-11-01 00:00:00 | 1 | 15 | 20151101001 |
| 1 | 2015-11-01 01:00:00 | 1 | 13 | 20151101011 |
| 2 | 2015-11-01 02:00:00 | 1 | 10 | 20151101021 |
| 3 | 2015-11-01 03:00:00 | 1 | 7 | 20151101031 |
| 4 | 2015-11-01 04:00:00 | 1 | 9 | 20151101041 |
len(dataset)48120
describe()コマンドは数値データを扱うときに便利です。基本的には、min, max, averageなど、データの全体的な概要を表示します。この情報を利用して、各属性の範囲や尺度を知ることができます。このレベルからは何の異常も見られません。また、属性のスケールもそれほど違いはありません。つまり、このデータセットでは、特徴量のスケーリングのステップを省略することができます。
dataset.describe()| Junction | Vehicles | ID | |
|---|---|---|---|
| count | 48120.000000 | 48120.000000 | 4.812000e+04 |
| mean | 2.180549 | 22.791334 | 2.016330e+10 |
| std | 0.966955 | 20.750063 | 5.944854e+06 |
| min | 1.000000 | 1.000000 | 2.015110e+10 |
| 25% | 1.000000 | 9.000000 | 2.016042e+10 |
| 50% | 2.000000 | 15.000000 | 2.016093e+10 |
| 75% | 3.000000 | 29.000000 | 2.017023e+10 |
| max | 4.000000 | 180.000000 | 2.017063e+10 |
データの前処理を行う
前述したように、DateTime and Junctionの2つの属性は独立変数であり、結果変数であるVehiclesに寄与しています。したがって、ID属性を維持する必要はないと思われますので、これは削除して良いでしょう。
dataset.drop(["ID"],axis = 1,inplace=True)冗長なデータは不要なので、これも捨ててしまいましょう。
dataset.drop_duplicates(keep="first", inplace=True)
len(dataset)48120
幸いなことに、このデータセットには重複がありませんでしたが、冗長性がないかどうかをチェックする習慣をつけておくと良いでしょう。特に数値データを扱う際には、NULL値への対処も重要です。NULL値があると、数学的な操作がしづらくなり、エラーになることもあります。そのため、NULL値をダミーデータに置き換えるか、その行を削除します。まずは、データにNULL値が含まれていないかどうかを確認してみましょう。
dataset.isnull().sum()DateTime 0
Junction 0
Vehicles 0
dtype: int64
dataset.dtypesDateTime object
Junction int64
Vehicles int64
dtype: object
DateTime属性はデータ型がobjectです。まず、pandasの関数であるto_datetimeを呼び出して、この属性を実際のフォーマットに変換します。これにより、year, month, dayなどの情報を直接抽出することができます。
dataset['DateTime'] = pd.to_datetime(dataset['DateTime'])時間が適切なフォーマットに変換されたので、次の属性を抽出してみましょう 。Weekday, Year, Month, Day, Time, Week, and Quater
dataset['Weekday'] = [date.weekday() for date in dataset.DateTime]
dataset['Year'] = [date.year for date in dataset.DateTime]
dataset['Month'] = [date.month for date in dataset.DateTime]
dataset['Day'] = [date.day for date in dataset.DateTime]
dataset['Time'] = [((date.hour*60+(date.minute))*60)+date.second for date in dataset.DateTime]
dataset['Week'] = [date.week for date in dataset.DateTime]
dataset['Quarter'] = [date.quarter for date in dataset.DateTime]更新されたデータセットは以下のようになります。
dataset.head()| DateTime | Junction | Vehicles | Weekday | Year | Month | Day | Time | Week | Quarter | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2015-11-01 00:00:00 | 1 | 15 | 6 | 2015 | 11 | 1 | 0 | 44 | 4 |
| 1 | 2015-11-01 01:00:00 | 1 | 13 | 6 | 2015 | 11 | 1 | 3600 | 44 | 4 |
| 2 | 2015-11-01 02:00:00 | 1 | 10 | 6 | 2015 | 11 | 1 | 7200 | 44 | 4 |
| 3 | 2015-11-01 03:00:00 | 1 | 7 | 6 | 2015 | 11 | 1 | 10800 | 44 | 4 |
| 4 | 2015-11-01 04:00:00 | 1 | 9 | 6 | 2015 | 11 | 1 | 14400 | 44 | 4 |
dataset.keys()Index(['DateTime', 'Junction', 'Vehicles', 'Weekday', 'Year', 'Month', 'Day',
'Time', 'Week', 'Quarter'],
dtype='object')
トレンドを可視化する
扱っているデータにどのようなパターンがあるかを見てみましょう。
data = dataset.Vehicles
binwidth = 1
plt.hist(data, bins=range(min(data), max(data) + binwidth, binwidth), log=False)
plt.title("Gaussian Histogram")
plt.xlabel("Traffic")
plt.ylabel("Number of times")
plt.show()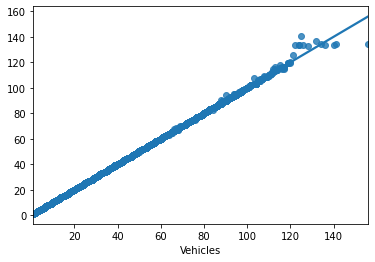
あるタイムスタンプを設定すると、トラフィックが (20,30) の間に位置することが多いことがわかります。
モデル構築のためにデータセットを準備する
datetounix 関数は、DateTime 属性を unixtime に変換します。unix timestampは、Unixエポックからの経過時間の合計(秒単位)を示す単なる数値です。その定義が示す通り、unix timestamp はタイムゾーンに依存しないため、モデル構築の際によく使用されます。
def datetounix(df):
unixtime = []
# Running a loop for converting Date to seconds
for date in df['DateTime']:
unixtime.append(time.mktime(date.timetuple()))
# Replacing Date with unixtime list
df['DateTime'] = unixtime
return(df)dataset_features = datetounix(dataset)dataset_features| DateTime | Junction | Vehicles | Weekday | Year | Month | Day | Time | Week | Quarter | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1.446316e+09 | 1 | 15 | 6 | 2015 | 11 | 1 | 0 | 44 | 4 |
| 1 | 1.446320e+09 | 1 | 13 | 6 | 2015 | 11 | 1 | 3600 | 44 | 4 |
| 2 | 1.446323e+09 | 1 | 10 | 6 | 2015 | 11 | 1 | 7200 | 44 | 4 |
| 3 | 1.446327e+09 | 1 | 7 | 6 | 2015 | 11 | 1 | 10800 | 44 | 4 |
| 4 | 1.446331e+09 | 1 | 9 | 6 | 2015 | 11 | 1 | 14400 | 44 | 4 |
| … | … | … | … | … | … | … | … | … | … | … |
| 48115 | 1.498829e+09 | 4 | 11 | 4 | 2017 | 6 | 30 | 68400 | 26 | 2 |
| 48116 | 1.498833e+09 | 4 | 30 | 4 | 2017 | 6 | 30 | 72000 | 26 | 2 |
| 48117 | 1.498837e+09 | 4 | 16 | 4 | 2017 | 6 | 30 | 75600 | 26 | 2 |
| 48118 | 1.498840e+09 | 4 | 22 | 4 | 2017 | 6 | 30 | 79200 | 26 | 2 |
| 48119 | 1.498844e+09 | 4 | 12 | 4 | 2017 | 6 | 30 | 82800 | 26 | 2 |
48120 rows × 10 columns
X = dataset_features Junction, Weekday, and Dayは離散的なデータで、連続的な値ではなくクラスになっています。そのため、分類する前に、このデータをエンコードする必要があります。そのためには、これらのデータを str に変換します。そして、エンコードされたデータを取得するために、get_dummies関数を呼び出します。
X['Junction'] = X['Junction'].astype('str')
X['Weekday'] = X['Weekday'].astype('str')
X['Day'] = X[ 'Day' ].astype('str')X = pd.get_dummies(X)print("X.shape : ", X.shape)
display(X.columns)X.shape : (48120, 49)
Index(['DateTime', 'Vehicles', 'Year', 'Month', 'Time', 'Week', 'Quarter',
'Junction_1', 'Junction_2', 'Junction_3', 'Junction_4', 'Weekday_0',
'Weekday_1', 'Weekday_2', 'Weekday_3', 'Weekday_4', 'Weekday_5',
'Weekday_6', 'Day_1', 'Day_10', 'Day_11', 'Day_12', 'Day_13', 'Day_14',
'Day_15', 'Day_16', 'Day_17', 'Day_18', 'Day_19', 'Day_2', 'Day_20',
'Day_21', 'Day_22', 'Day_23', 'Day_24', 'Day_25', 'Day_26', 'Day_27',
'Day_28', 'Day_29', 'Day_3', 'Day_30', 'Day_31', 'Day_4', 'Day_5',
'Day_6', 'Day_7', 'Day_8', 'Day_9'],
dtype='object')
X.head()| DateTime | Vehicles | Year | Month | Time | Week | Quarter | Junction_1 | Junction_2 | Junction_3 | … | Day_29 | Day_3 | Day_30 | Day_31 | Day_4 | Day_5 | Day_6 | Day_7 | Day_8 | Day_9 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1.446316e+09 | 15 | 2015 | 11 | 0 | 44 | 4 | 1 | 0 | 0 | … | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 1.446320e+09 | 13 | 2015 | 11 | 3600 | 44 | 4 | 1 | 0 | 0 | … | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 2 | 1.446323e+09 | 10 | 2015 | 11 | 7200 | 44 | 4 | 1 | 0 | 0 | … | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 3 | 1.446327e+09 | 7 | 2015 | 11 | 10800 | 44 | 4 | 1 | 0 | 0 | … | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 4 | 1.446331e+09 | 9 | 2015 | 11 | 14400 | 44 | 4 | 1 | 0 | 0 | … | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
5 rows × 49 columns
分類を定義する
ここでは、勾配ブースティングモデルであるLGBMRegressorを使用します。モデルのアーキテクチャやパラメータの詳細については、こちらを参照してください。
clf = LGBMRegressor(boosting_type='gbdt',
max_depth=6,
learning_rate=0.25,
n_estimators=80,
min_split_gain=0.7,
reg_alpha=0.00001,
random_state = 16
)
データセットを分割する
データセットをトレーニングとテストに70:30の比率で分割します。ここでは従来の比率を使いましたが、この比率は都合に合わせてカスタマイズすることもできます。
Y = dataset['Vehicles'].to_frame()
dataset = dataset.drop(['Vehicles'], axis=1)
X_train, X_test, y_train, y_test = train_test_split(X, Y, test_size=0.3, random_state=101)モデルを評価する
このモデルがテストデータでどのように機能するかを見てみましょう。
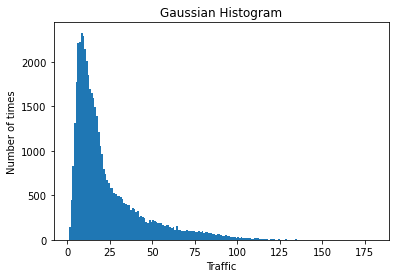
clf = clf.fit(X_train, y_train)predictions = clf.predict(X_test)print("RMSE", np.sqrt(metrics.mean_squared_error(y_test, predictions)))RMSE 0.309624242642493
sns.regplot(y_test,predictions)<matplotlib.axes._subplots.AxesSubplot at 0x138722cdcd0>
まとめ
このモデルの結果、RMSEは0.309となり、かなり良好な結果となりました。さまざまな評価指標を試してみてはいかがでしょうか。プロットの結果のラインは、データインスタンスに正確に合致しているようです。したがって、このモデルがうまく機能していることが確認できました。
メトリクスとスコアリングについての詳細は、scikit-learn公式サイトを参照してください。Happy Coding!
If you have any questions about the blog, please create a Stack Overflow post here https://stackoverflow.com/questions/ask?tags=griddb .
Make sure that you use the “griddb” tag so our engineers can quickly reply to your questions.