データセットについて
BRFSSとは、Behavioural Risk Factor Surveillance System(行動危険因子サーベイランスシステム)の略です。BRFSSの目的は、米国に住む非入院の成人(18歳以上)の行動危険因子を評価することにあります。これらの健康情報を収集するために、米国内の50の州が、世帯から無作為に成人を抽出して電話による調査を実施しています。
これらの情報から、無作為抽出が行われていると言えます。したがって、このサンプルから得られた結論は、より多くの関連する集団に一般化することができます。
しかし、調査を行っている以上、ボランティアに参加するかどうかは大人にもよるので、割り当てが完全に無作為であると断言することはできません。したがって、このデータをもとに2つのパラメータの間に因果関係を設定することは適切ではありません。
データセットに含まれるパラメータは全部で330個あります。これらのパラメータは、年齢、身体的健康状態、精神的健康状態、服薬状況などを記録しています。データセットに含まれるインスタンスの総数は491,775です。
ここでは、Kaggleからダウンロードできる2013年の公開データセットを使用します。このサイトでは、2015年のより新しいバージョンのデータセットもCSVとJSON形式で提供されていますが、このチュートリアルはどのようなデータセットにも拡張可能です。
環境設定
以下のチュートリアルは、Windows 10のRStudio(Rバージョン4.0.2)で行われています。ただし、どのOSを使用しても構文は同じです。
必要なパッケージのインストールとロード
install.packages("dplyr")
install.packages("ggplot2")
library(dplyr)
library(ggplot2)
データセットの読み込み
データセットはRの作業ディレクトリと同じディレクトリにある必要があり,そうでない場合はエラーメッセージが出力されます。
load("brfss2013.RData")
.RDataは、特にRに属するデータセットの拡張子です。
トラブルシューティング
以下のコマンドを使って、作業ディレクトリを確認することができます。
getwd()
作業ディレクトリとデータセットの場所が異なる場合は、以下のコマンドで作業ディレクトリを設定してください。あるいは、データセットを上記の出力場所に移動してください。
setwd(dir)
dirは任意のパスを指定する文字列です。パスの設定方法については、こちらをご覧ください。
簡単な代替手段 – GridDB
前述のデータセットは600MB近くあります。これは大したことではないと思われるかもしれませんが、このような膨大な量のデータをRCloudにアップロードしても、結果的には良い結果にはなりません。むしろ、サーバーはこのデータセットのアップロードに多くの時間を要し、最終的にはタイムアウトしてしまいます。この情報は重要です。なぜなら、私たちが行ったチュートリアルは、あなたのローカルシステムを使って行う必要があるからです。これでは拡張性の余地がありません。特に、複数の人と共同作業をすることが多い組織で働いている場合には、この問題が発生します。
この問題を解決するために、拡張性が高く、データに最適なソリューションであるGridDBを用意しました。GridDBは、高い拡張性と信頼性を持ち、比較的高速にデータを保存できるツールです。また、Java、C、Pythonなど、多くのプログラミング言語をサポートしています。
Python-GridDBクライアントの設定については、こちらのクイックチュートリアルをご覧ください。また、IoTやビッグデータ向けに最適化されたこのオープンソース・データベースを手動でダウンロードすることもできます。
フィルタリングと可視化
このチュートリアルの最も重要な研究課題は、人の一般的な健康状態の分布を視覚化し、それが人の婚姻状況によって変化するかどうかを調べることです。この研究課題は、このデータセットの2つのパラメータに焦点を当てます。一般的な健康状態のパラメータ(データセットではgenhlthと表記)と婚姻状況(データセットではmaritalと表記)です。
一般的な健康状態は、「優れている」(Excellent)、「非常に良い」(Very good)、「良い」(Good)、「普通」(Fair)、「悪い」(Poor)の5つのカテゴリーに分類されますが、一部のエントリーでは、この情報が得られない場合があります(
同様に、婚姻状況についても、次のような値が考えられます。「既婚」(Married)、「離婚」(Divorced)、「未亡人」(Widowed)、「別居」(Separated)、「未婚」(Never married)、または「未婚のカップル」(A member of an unmarried couple)です。ここでも、参加者の中には回答しなかった人がいるかもしれないので、それらの項目には
まず、「一般的な健康状態」に該当する人の分布はどうなっているか見てみましょう。
brfss2013 %>%
group_by(genhlth) %>%
summarise(count = n())
次のような出力が得られます。
## # A tibble: 6 x 2 ## genhlth count #### 1 Excellent 85482 ## 2 Very good 159076 ## 3 Good 150555 ## 4 Fair 66726 ## 5 Poor 27951 ## 6 1985
1985人の方が質問に答えていないことがわかります。したがって、このようなエントリーはフィルタリングして除外します。
brfss2013 %>%
filter(genhlth != "NA") %>%
group_by(genhlth) %>%
summarise(count = n())
出力は以下のようになるはずです。
## # A tibble: 5 x 2 ## genhlth count #### 1 Excellent 85482 ## 2 Very good 159076 ## 3 Good 150555 ## 4 Fair 66726 ## 5 Poor 27951
では、もう一つの注目すべきパラメータを見てみましょう。婚姻状況についてです。ここでも、欠落しているエントリーを除外します。
brfss2013 %>%
filter(marital!="NA") %>%
group_by(marital) %>%
summarise(count = n())
## # A tibble: 6 x 2 ## marital count #### 1 Married 253329 ## 2 Divorced 70376 ## 3 Widowed 65745 ## 4 Separated 10662 ## 5 Never married 75070 ## 6 A member of an unmarried couple 13173
すべての可能な組み合わせを可視化するためには、これらの2つのパラメータに基づいてデータを集計する必要があります。この目的のために、dplyrライブラリは関数countを提供しています。この関数を使って、健康に優れた人を数えたり、婚姻状況を比較したりします。
agg = count(brfss2013, genhlth, marital) %>%
filter(genhlth!="NA", marital!="NA")
aggにどのようなデータが保存されているかを確認してみましょう。
head(agg) --> ## genhlth marital n ## 1 Excellent Married 49682 ## 2 Excellent Divorced 10049 ## 3 Excellent Widowed 7007 ## 4 Excellent Separated 1221 ## 5 Excellent Never married 14419 ## 6 Excellent A member of an unmarried couple 2364
さて、数がわかったところで、既婚男性/女性の健康に対する割合を見てみましょう。
ggplot(agg %>%
filter(marital=="Married")) + geom_bar(aes(x = genhlth, y = n), stat = "identity")
上記のコマンドでは、次のような出力が得られます。
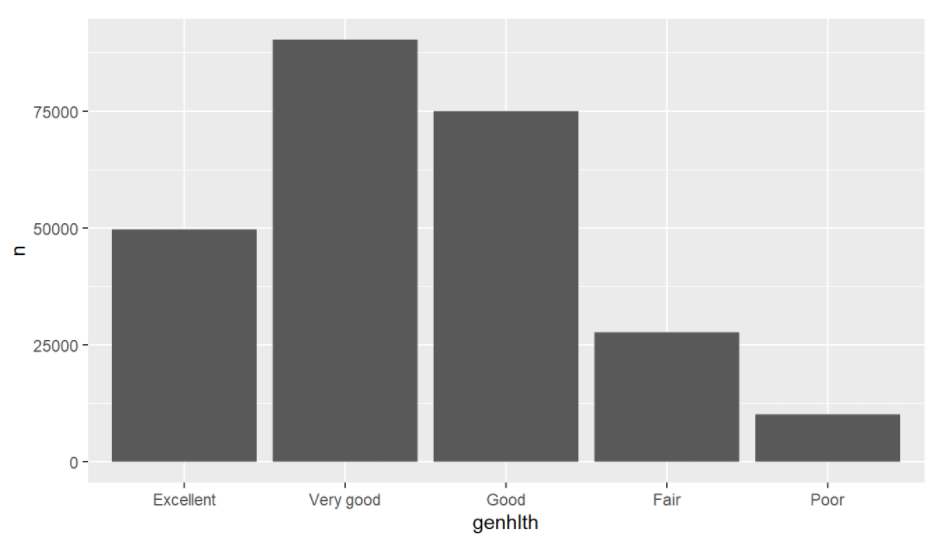
同様に、既婚者以外の婚姻状況の人の割合も可視化できます。さあ、このシンプルなコードを使って、素敵なプロットを描いてみてください。
結論
このチュートリアルでは、R言語を使って公開されているBRFSSデータセットを分析しました。巨大なデータセットをローカルシステムで使用することの限界と、簡単ではるかに速い代替手段について説明しました。
続いて、Rで欠落した情報をフィルタリングする方法を見て、その後、ggplotライブラリを使って、2つのパラメータに基づいて棒グラフをプロットしました。
ブログの内容について疑問や質問がある場合は Q&A サイトである Stack Overflow に質問を投稿しましょう。 GridDB 開発者やエンジニアから速やかな回答が得られるようにするためにも "griddb" タグをつけることをお忘れなく。 https://stackoverflow.com/questions/ask?tags=griddb