はじめに
データは洞察の源です。この洞察を引き出すには、データを分析し、理解する必要があります。しかし、数値で分析することは困難です。データから洞察を抽出する最も簡単な方法は、データの可視化です。
データの可視化とは、データを図やグラフを使って表現することです。こうすることで、技術者でないユーザーでもデータを理解しやすくなります。
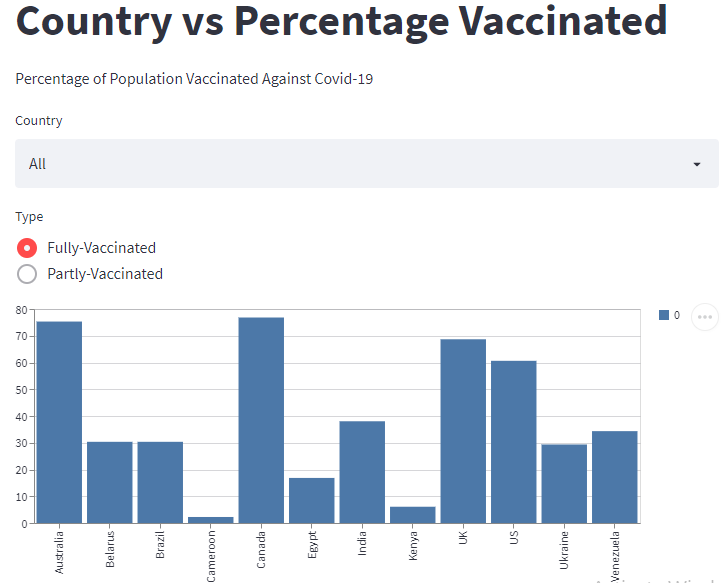
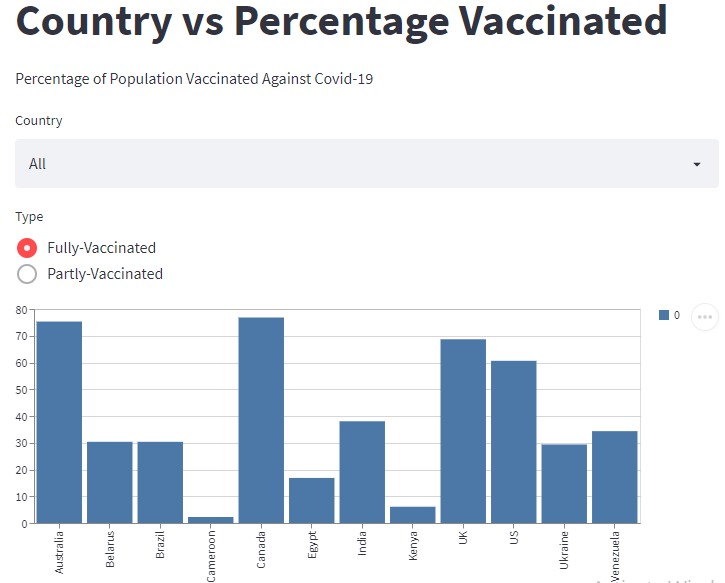
今回は、GridDBとStreamlitを使って、データを可視化する方法を説明します。可視化するデータは、12の異なる国におけるCovid-19に対する完全および部分的なワクチン接種を受けた人口の割合です。
必要条件
この記事で紹介する内容は、Streamlit、GridDB、およびそのPythonクライアントがインストールされていることを前提とします。
GridDBのインストールは、公式ドキュメントを参照し、インストール手順にしたがってください。
Streamlitのインストールは、Pythonのpipパッケージマネージャを使用して、以下のコマンドを実行してください。
pip3 install streamlit --userデータの取り込み
まず、GridDBサーバにデータをロードする必要があります。CSVファイルから直接読み込むことも可能ですが、GridDBのハイブリッドインメモリアーキテクチャを活用することで、アプリケーションの高速化を図ることができます。また、必要なデータをデータフレームにロードすることで、クエリのパフォーマンスを向上させることができます。
まず、使用するライブラリをインポートしましょう。
import pandas as pd
import griddb_python as griddb次に、使用する GridDB コンテナを初期化します。
factory = griddb.StoreFactory.get_instance()
# Initialize the GridDB container
try:
gridstore = factory.get_store(host=host_name, port=your_port,
cluster_name=cluster_name, username=your_username,
password=your_password)
info = griddb.ContainerInfo("Vaccination_Data",
[["country", griddb.Type.STRING],["fully-vaccinated",griddb.Type.FLOAT]], ["partly-vaccinated",griddb.Type.FLOAT]],
griddb.ContainerType.COLLECTION, True)
cont = gridstore.put_container(info) 上記の認証情報は、GridDB のインストール時に指定したものに置き換えてください。
コンテナには、country, fully-vaccinated, partly-vaccinated という 3 つのカラムがあります。
データは vaccination.csv という名前の CSV ファイルに保存されています。これをGridDBコンテナにロードしてみます。
data = pd.read_csv("vaccination.csv")
#Load data
for x in range(len(data)):
ret = cont.put(data.iloc[x, :])
print("Data loaded successfully")
except griddb.GSException as ex:
for x in range(e.get_error_stack_size()):
print("[", x, "]")
print(ex.get_error_code(x))
print(ex.get_location(x))
print(ex.get_message(x))データを取得する
それでは、GridDBからデータを取得してみましょう。そのためのSQLクエリを記述します。
sql_statement = ('SELECT * FROM Vaccination_Data')
output = pd.read_sql_query(sql_statement, cont)Pandas の read_sql_query 関数は、取得したデータを dataframe オブジェクトに変換します。
ダッシュボードを作成する
データの準備ができたので、それを使って可視化してみましょう。まず、Streamlit ライブラリをインポートします。
import streamlit as stダッシュボードには、タイトルと説明を付けることができます。それぞれ、 st.title と st.write を使用します。
st.title('Country vs Percentage Vaccinated')
st.write('Percentage of Population Vaccinated Against Covid-19')次に、ダッシュボードにセレクトボックスを追加してみましょう。セレクトボックスは、ユーザーが国を選択するためのドロップダウンボタンを提供します。以下のように、st.selectbox() メソッドを使用して作成します。
select = st.selectbox("Country", ["All", "Australia", "Belarus", "Brazil", "Cameroon", "Canada", "Egypt", "India", "Kenya", "Ukraine", "UK", "US", "Venezuela" ])また、ラジオボタンを作成し、ユーザーが完全接種と部分接種を選択できるようにすることも可能です。
radio = st.radio("Type", ["Fully-Vaccinated", "Partly-Vaccinated" ])セレクトボックスとラジオボタンに機能を追加してみましょう。
if select != "ALL":
sql_statement = sql_statement + " AND Country = '"+select+"'"
if radio != "ALL":
sql_statement = sql_statement + " AND Type = '"+select+"'"各国のCovid-19ワクチン接種人口比率を示す棒グラフを作成してみましょう。これには、以下のように st.bar_chart() メソッドを使用することができます。
st.bar_chart(data=output)プロジェクトを実行する
ダッシュボードを見るには、プロジェクトを実行する必要があります。以下のコマンドを使用します。
streamlit run myapp.py生成されたURLをWebブラウザで開くと、ダッシュボードが表示されます。また、セレクトボックスやラジオボタンを操作して、ダッシュボード上でさまざまな結果を確認することができます。
ブログの内容について疑問や質問がある場合は Q&A サイトである Stack Overflow に質問を投稿しましょう。 GridDB 開発者やエンジニアから速やかな回答が得られるようにするためにも "griddb" タグをつけることをお忘れなく。 https://stackoverflow.com/questions/ask?tags=griddb