Here’s a video version of some of the content found in this blog.
Generally, data from one device, sensor, or input will be stored in one collection. In this blog post, we’ll explain what Containers are and what you can and cannot do with them. We will also explain how data is typically organized within a GridDB application.
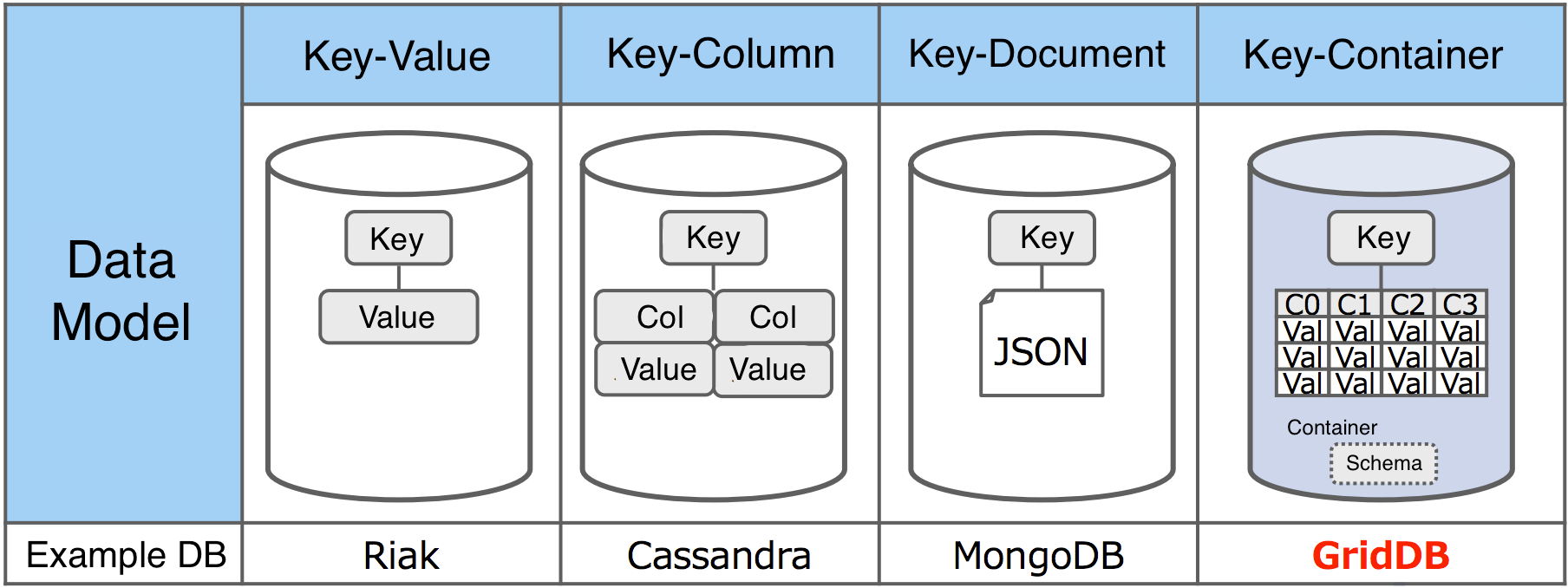
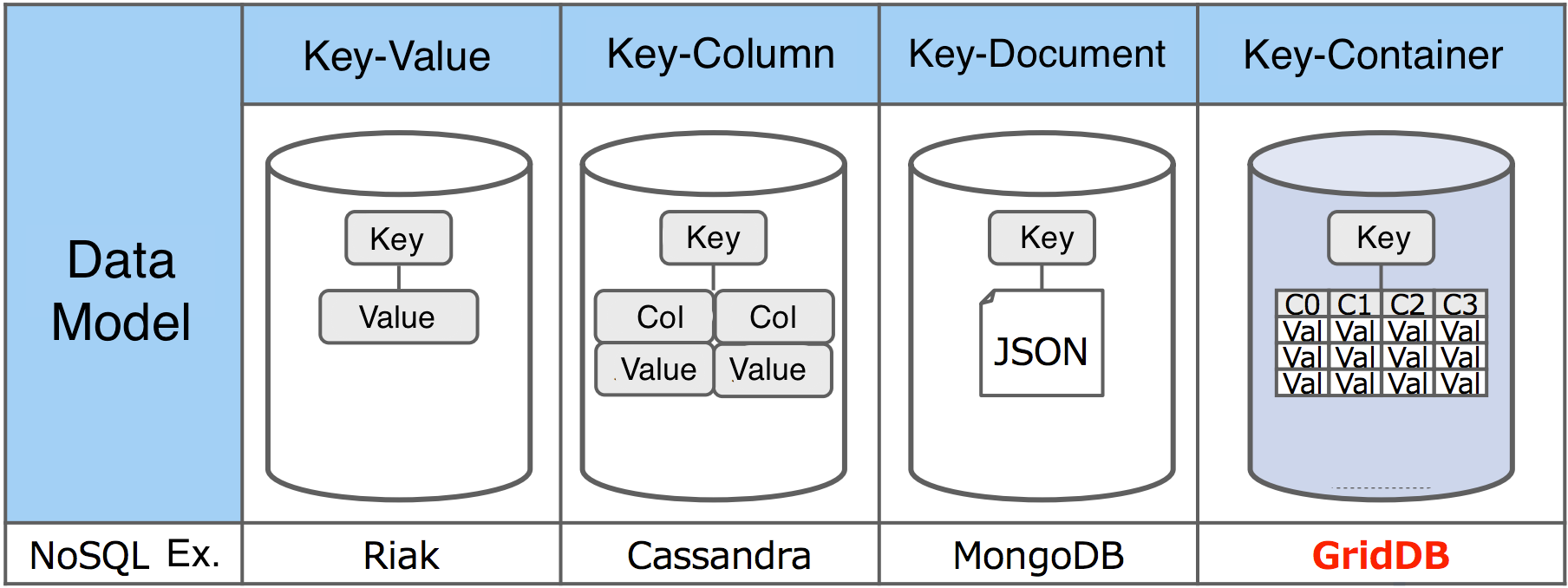
To compare GridDB to other NoSQL databases, in a Key-Value database (Redis), the key points to any value and attributes of that value usually cannot be indexed or queried, a Key in a Key-Document database (like MongoDB) points to a document where different documents can have different structures.
Containers
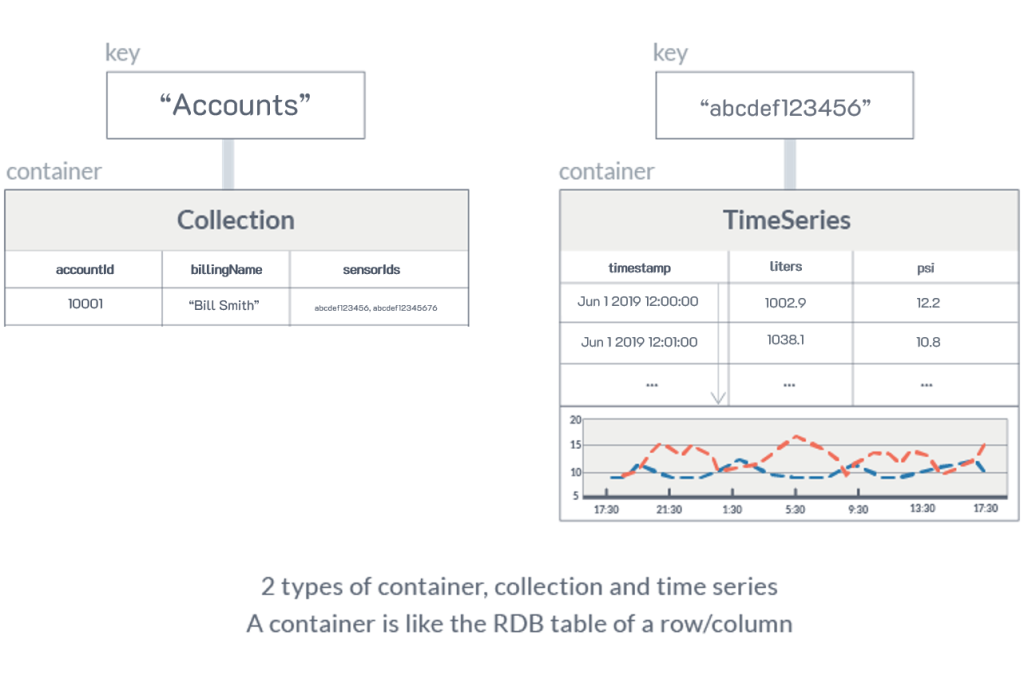
GridDB has two container types: Collections which can have any type of row key, and TimeSeries which always have a timestamp as the row key. They also feature several other unique features.
In Java, a container is defined by a static class of variables; timestamps, simple strings, numbers, geometry types, blobs or arrays of strings and numbers are all supported (Full list here). In all other languages, the container is defined by a ContainerInfo object, but some languages do not support arrays and geometry types at this time.
In a Collection, Row Keys can be either be unique or not, this is determined by placing a @RowKey attribute in front of the type in Java or the row_key parameter in a ContainerInfo object in other languages.
Data Modeling
With the Key-Container model, each device, application, sensor, account or dataset get its own container and typically the same schema would be used for each type of device. A unique ID would be part of the container key and a collection can be used to help organize the many container keys.
Writes to an ad-hoc queries of an individual container are very fast as just that container needs to be locked meanwhile the total time required to query many containers is usually faster than Key-Column or relational data models.
Let’s look at this example of a water company’s sensor recording and billing application.
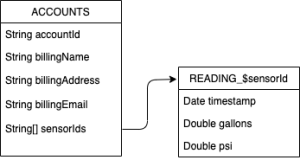
The above ER diagram would be represented in Java with the following classes:
static class AccountRecord {
@RowKey String accountId;
String billingName;
String billingAddress;
String billingEmail;
String[] sensorIds;
}
static class SensorReading {
@RowKey Date timestamp;
double liters;
double psi;
}
The following shows how a GridDB puts data into different containers as well as how the same data would be represented in a Relational Database.
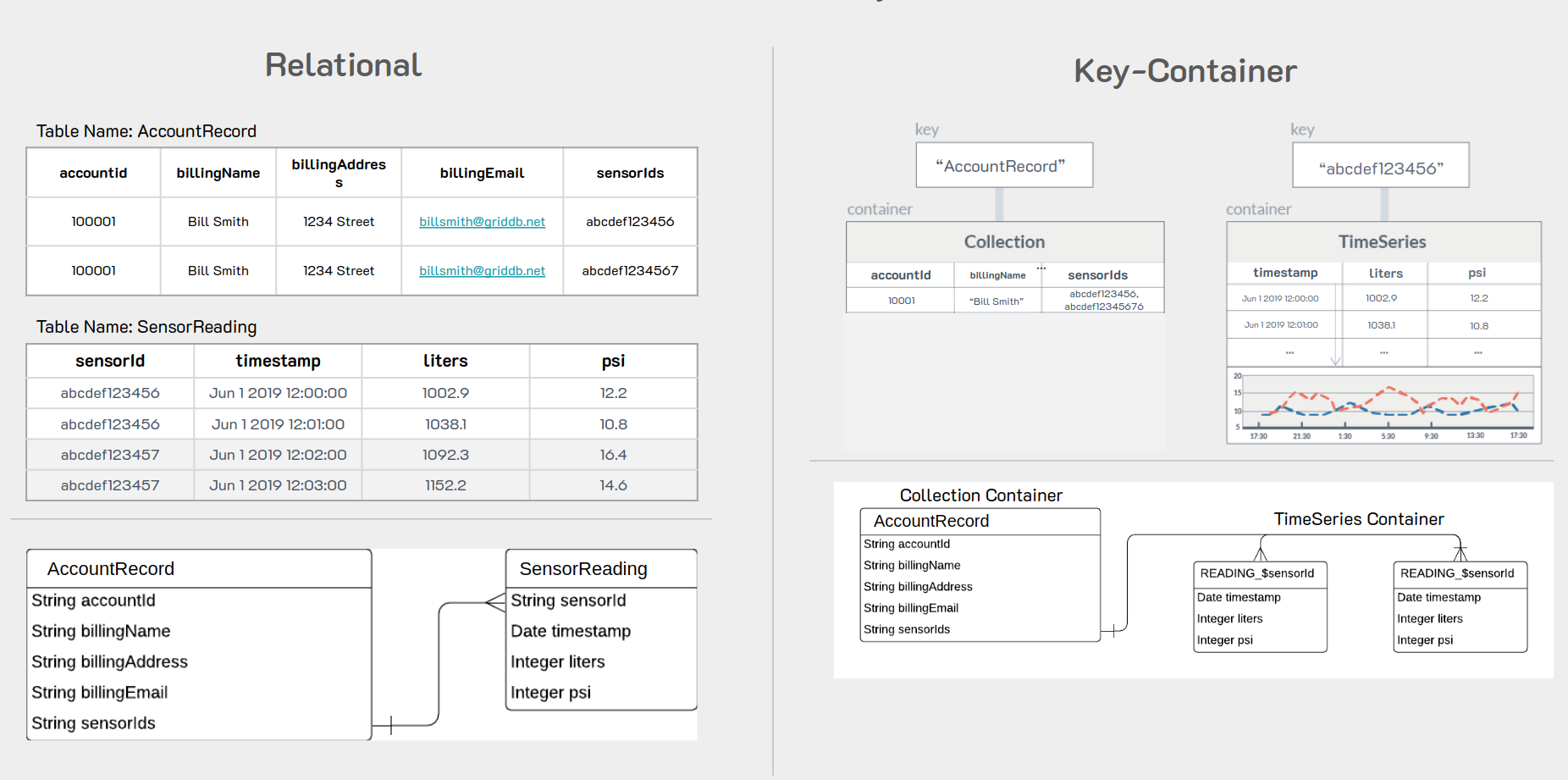
Notice on the relational side that all of the sensors will populate into one table.(Note: we settled on inserting all sensors into one table because it was the more efficient method in RDMBS). Imagine now that the application scales out to several tens of thousands of sensors; the RDBMS table housing the sensors will quickly become too cumbersome to do any meaningful work without significant slow downs.
Over time each sensor would push data into the appropriate SENSOR_$sensorId container and customers would be written to the ACCOUNTS container with the sensorIds that apply to their account. When it comes time to generate bills, the billing application would iterate through the rows of accounts, reading each of the READING_$sensorId containers to calculate the bill.
GridDB’s novel Key-Container data model allows developers an easy and efficient way to model data (Time Series or not) of many individual inputs into many containers that can be aggregated and iterated.