Extracting meaningful insights from a large corpus of documents is a challenging task. With advancements in Large Language Models (LLMS), it is now possible to automate the process of structured data extraction from text documents. In this article, you will learn how to extract structured data from PDF documents using LLMs in LangChain and store it in GridDB.
GridDB is a high-performance NoSQL database suited for managing complex and dynamic datasets. Its high-throughput NOSQL capabilities make it ideal for storing large structured datasets containing text insights.
We will begin by downloading a PDF document dataset from Kaggle and extracting structured information from the documents using LangChain. We will then store the structured data in a GridB container. Finally, we will retrieve the data from the GridDB container and analyze the structured metadata for the PDF documents.
Note: See the GridDB Blogs GitHub repository for codes.
Prerequisites
You need to install the following libraries to run the codes in this article.
- GridDB C Client
- GridDB Python client
You can install these libraries following the instructions on the GridDB Python Package Index (Pypi)
In addition, you need to install the langchain, openai, pydantic, pandas, pypdf, openai, tiktoken, and tqdm libraries to run codes in this article. The following script installs these libraries.
!pip install --upgrade -q langchain
!pip install --upgrade -q pydantic
!pip install --upgrade -q langchain-community
!pip install --upgrade -q langchain-core
!pip install --upgrade -q langchain-openai
!pip install --upgrade -q pydantic pandas pypdf openai tiktoken tqdm
Finally, run the script below to import the required libraries and modules into your Python application.
from pathlib import Path
import re
import pandas as pd
from tqdm import tqdm
from itertools import islice
from typing import Literal, Optional
import matplotlib.pyplot as plt
from langchain_core.pydantic_v1 import BaseModel, Field, validator
from langchain.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_openai import ChatOpenAI
from langchain.agents import create_openai_functions_agent, AgentExecutor
from langchain_experimental.tools import PythonREPLTool
from langchain_community.document_loaders import PyPDFDirectoryLoader
import griddb_python as griddb
Extracting Structured Data from PDF Documents
We will extract structured information from the PDF files dataset from Kaggle. Download the dataset into your local directory and run the following script.
The dataset contains over a thousand files; however, for the sake of testing, we will extract structured information from 100 documents.
The following script extracts data from the first 100 documents and stores it in a Python list.
# https://www.kaggle.com/datasets/manisha717/dataset-of-pdf-files
pdf_dir = Path("/home/mani/Datasets/Pdf")
loader = PyPDFDirectoryLoader(
pdf_dir,
recursive=True,
silent_errors=True
)# raises warning if a PDF document doesnt contain valid text
# first 100 that load cleanly
docs_iter = loader.lazy_load() # generator → 1 Document per good PDF
docs = list(islice(docs_iter, 100))
docs[0] Output:

The above output shows the contents of the first document.
In this article, we will use a large language model (LLM) with a structured response in LangChain to extract the title, summary, document type, topic category, and sentiment from a PDF document.
To retrieve structured data, we have to define the scheme of the data we want to retrieve. For example, we will predefine some categories for document type, topic category, and sentiment, as shown in the following script.
DOC_TYPES = (
"report", "article", "manual", "white_paper",
"thesis", "presentation", "policy_brief", "email", "letter", "other",
)
TOPIC_CATS = (
"science", "technology", "history", "business",
"literature", "health", "education", "art",
"politics", "other",
)
Sentiment = Literal["positive", "neutral", "negative"]Next, we will define a Pydantic BaseModel class object, which contains fields for the structured information we want to extract from the PDF documents. The descriptions of the fields tell LLMs what information to store in them.
class PDFRecord(BaseModel):
"""Validated metadata for a single PDF."""
title: str = Field(
...,
description="Document title. If the text contains no clear title, "
"generate a concise 6–12-word title that reflects the content."
)
summary: str = Field(
...,
description="Two- to three-sentence synopsis of the document."
)
doc_type: Literal[DOC_TYPES] = Field(
default="other",
description="Document genre; choose one from: " + ", ".join(DOC_TYPES)
)
topic_category: Literal[TOPIC_CATS] = Field(
default="other",
description="Primary subject domain; choose one from: " + ", ".join(TOPIC_CATS)
)
sentiment: Sentiment = Field(
default="neutral",
description="Overall tone of the document: positive, neutral, or negative."
)
# --- fallback helpers so bad labels never crash validation ---
@validator("doc_type", pre=True, always=True)
def _doc_fallback(cls, v):
return v if v in DOC_TYPES else "other"
@validator("topic_category", pre=True, always=True)
def _topic_fallback(cls, v):
return v if v in TOPIC_CATS else "other"The next step is to define a prompt for an LLM that guides the LLM in extracting structured data from PDF documents and converting it to JSON format. The BaseModel class we defined before can extract JSON data from a structured LLM response.
Notice that the prompt contains the pdf_text placeholder. This placeholder will store the text of the PDF document.
prompt = ChatPromptTemplate.from_messages([
("system",
"You are a meticulous analyst. "
"Extract only what is explicitly present in the text, "
"but you MAY generate a succinct title if none exists."),
("human",
f"""
**Task**
Fill the JSON schema fields shown below.
**Fields**
• title – exact title if present; otherwise invent a 6-12-word title
• summary – 2–3 sentence synopsis
• doc_type – one of: {", ".join(DOC_TYPES)}
• topic_category – one of: {", ".join(TOPIC_CATS)}
• sentiment – positive, neutral, or negative overall tone
**Rules**
– If a category is uncertain, use "other".
– Respond ONLY in the JSON format supplied automatically.
**Document begins**
{{pdf_text}}
""")
])The next step is to define an LLM. We will use the OpenAI gpt-4o-mini model and create the ChatOpenAI object that supports chat-like interaction with the LLM. You can use any other supported by the LangChain framework.
To extract structured data, we call the with_structured_output() function using the ChatOpenAI object and pass it the PDFRecord base model class we defined earlier.
Finally, we combine the prompt and LLM to create a LangChain runnable object.
llm = ChatOpenAI(model_name="gpt-4o-mini",
openai_api_key = "YOUR_OPENAI_API_KEY",
temperature=0)
structured_llm = llm.with_structured_output(PDFRecord)
chain = prompt | structured_llm We will extract the text of each document from the list of PDF documents and invoke the chain we defined. Notice that we are passing the PDF text (doc.page_content) as a value for the pdf_text key since the prompt contains a placeholder with the same name.
The response from the LLM chain is appended to the rows list.
rows = []
for doc in tqdm(docs, desc="Processing PDFs"):
record = chain.invoke({"pdf_text": doc.page_content}) # → PDFRecord
row = record.dict() # plain dict
row["path"] = doc.metadata["source"]
rows.append(row)The rows list now contains Python dictionaries containing structured information extracted from the PDF documents. We convert this list into a Pandas DataFrame and store it as a CSV file for later use.
dataset = pd.DataFrame(rows)
dataset.to_csv("pdf_catalog.csv", index=False)
print("✓ Saved pdf_catalog.csv with", len(rows), "rows")
dataset.head(10)Output:

The above output shows the data extracted from PDF documents. Each row corresponds to a single PDF document. Next, we will insert this data in GridDB.
Inserting Structured Data from PDF into GridDB
Inserting data into GridDB is a three-step process. You establish a connection with a GridDB host, create a container, and insert data into it.
Creating a Connection with GridDB
To create a GridDB connection, call the griddb.StoreFactory.get_instance() function to get a factory object. Next, call the get_store() function on the factory object and pass it the database host, cluster name, and user name and password.
The following script creates a connection to the locally hosted GridDB server and tests the connection by retrieving a dummy container.
factory = griddb.StoreFactory.get_instance()
DB_HOST = "127.0.0.1:10001"
DB_CLUSTER = "myCluster"
DB_USER = "admin"
DB_PASS = "admin"
try:
gridstore = factory.get_store(
notification_member = DB_HOST,
cluster_name = DB_CLUSTER,
username = DB_USER,
password = DB_PASS
)
container1 = gridstore.get_container("container1")
if container1 == None:
print("Container does not exist")
print("Successfully connected to GridDB")
except griddb.GSException as e:
for i in range(e.get_error_stack_size()):
print("[", i, "]")
print(e.get_error_code(i))
print(e.get_location(i))
print(e.get_message(i))Output:
Container does not exist
Successfully connected to GridDB
If you see the above output, you successfully established a connection with the GridDB server.
Inserting Data into GridDB
Next, we will insert the data from our Pandas DataFrame into the GridDB container.
To do so, we define the map_pandas_dtype_to_griddb() function, which maps the Pandas column types to GridDB data types.
We iterate through all the column names and types and create a list of lists, each nested list containing a column name and GridDB data type for the column.
Next, we create a ContainerInfo object using the container name, the container columns, and the types lists. Since we are storing tabular data, we set the container type to COLLECTION.
Next, we store the container in GridDB using the gridstore.put_container() function.
Finally, we iterate through all the rows in our pdf document dataset and store it in the container we created using the put() function.
# see all GridDB data types: https://docs.griddb.net/architecture/data-model/#data-type
def map_pandas_dtype_to_griddb(dtype):
if dtype == 'int64':
return griddb.Type.LONG
elif dtype == 'float64':
return griddb.Type.FLOAT
elif dtype == 'object':
return griddb.Type.STRING
# Add more column types if you want
else:
raise ValueError(f'Unsupported pandas type: {dtype}')
container_columns = []
for column_name, dtype in dataset.dtypes.items():
griddb_dtype = map_pandas_dtype_to_griddb(str(dtype))
container_columns.append([column_name, griddb_dtype])
container_name = "PDFData"
container_info = griddb.ContainerInfo(container_name,
container_columns,
griddb.ContainerType.COLLECTION, True)
try:
cont = gridstore.put_container(container_info)
for index, row in dataset.iterrows():
cont.put(row.tolist())
print("All rows have been successfully stored in the GridDB container.")
except griddb.GSException as e:
for i in range(e.get_error_stack_size()):
print("[", i, "]")
print(e.get_error_code(i))
print(e.get_location(i))
print(e.get_message(i))
Finally, we will retrieve data from GridDB and analyze the dataset.
Retrieving Data from GridDB and Performing Analysis
To retrieve data from a GridDB container, you must first retrieve the container using the get_container() function and then execute an SQL query on the container object using the query() function, as shown in the script below.
To execute the select query, you need to call the fetch() function, and to retrieve data as a Pandas dataframe, call the fetch_rows() function.
The following script retrieves structured data from our GridDB container and stores it in the pdf_dataset dataframe.
def retrieve_data_from_griddb(container_name):
try:
data_container = gridstore.get_container(container_name)
# Query all data from the container
query = data_container.query("select *")
rs = query.fetch()
data = rs.fetch_rows()
return data
except griddb.GSException as e:
print(f"Error retrieving data from GridDB: {e.get_message()}")
return None
pdf_dataset = retrieve_data_from_griddb(container_name)
pdf_dataset.head()
Output:

The above output shows the data retrieved from our GridDB container.
Once we store data from a GridDB container in a Pandas DataFrame, we can perform various analyses on it.
Using a Pie chart, Let’s see the topic category distribution in all PDF documents.
pdf_dataset["topic_category"].value_counts().plot.pie(autopct="%1.1f%%")
plt.title("Distribution of topic categories")
plt.ylabel("")
plt.show()Output:

The output shows that the majority of documents are related to science, followed by business.
Next, we can plot the distribution of document types using a donut chart.
df["doc_type"].value_counts().plot.pie(
autopct="%1.1f%%",
wedgeprops=dict(width=0.50) # makes the “donut” hole
)
plt.title("Document type")
plt.ylabel("")
plt.gca().set_aspect("equal")
plt.show()Output:

The output shows that the majority of documents are reports.
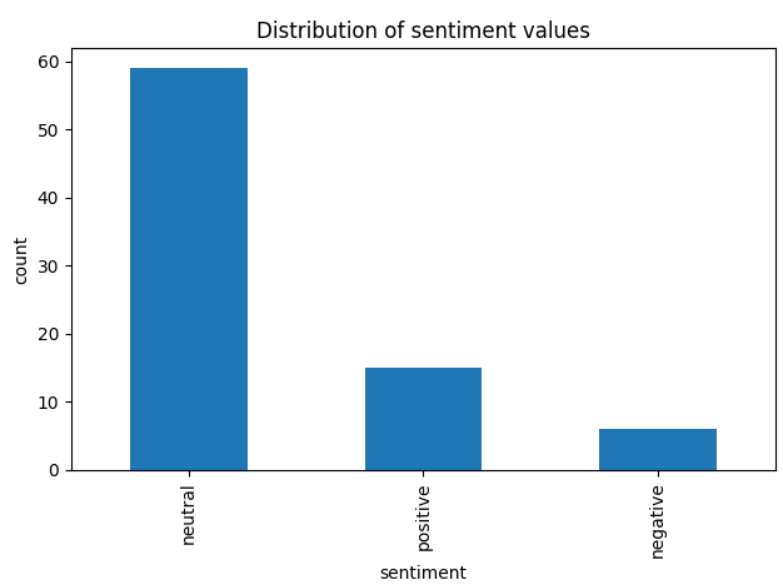
Finally, we can plot the sentiments expressed in documents as a bar plot.
pdf_dataset["sentiment"].value_counts().plot.bar()
plt.title("Distribution of sentiment values")
plt.xlabel("sentiment")
plt.ylabel("count")
plt.tight_layout()
plt.show()Output:

The above output shows that most of the documents have neutral sentiments.
Conclusion
This article explained how to build a complete pipeline for extracting metadata from unstructured PDF documents using LLMs and storing the result in GridDB. You explored using LangChain with OpenAI’s GPT-4 model to extract key information such as document title, summary, type, category, and sentiment and how to save this structured output into a GridDB container.
The combination of LLM-driven data extraction and GridDB’s performance-oriented architecture makes this approach suitable for intelligent document processing in real-time applications.
If you have questions or need assistance with GridDB please ask on Stack Overflow using the griddb tag. Our team is always happy to help.
For the complete code, visit my GridDB Blogs GitHub repository.
If you have any questions about the blog, please create a Stack Overflow post here https://stackoverflow.com/questions/ask?tags=griddb .
Make sure that you use the “griddb” tag so our engineers can quickly reply to your questions.