
This article demonstrates creating an interactive LangChain chatbot to retrieve information from a GridDB database using natural language queries. We will use the Python LangChain library and the OpenAI GPT-4o LLM (Large Language Model), to convert natural language queries into GridDB queries to interact seamlessly with the database.
Source code And Jupyter Notebook
You can find the source code (jupyter notebook) from our github repo:
$ git clone https://github.com/griddbnet/Blogs.git --branch chatbotPrerequisites
You need to install the following libraries to run codes in this article:
- GridDB C Client
- GridDB Python client
Follow the instructions on the GridDB Python Package Index (Pypi) page to install these clients.
You must also install LangChain, Numpy, Pandas, and Seaborn libraries.
The scripts below install and import the libraries you will need to run the code in this blog.
!pip install langchain
!pip install langchain-core
!pip install langchain-openai
!pip install langchain-experimental
!pip install tabulateimport griddb_python as griddb
import pandas as pd
from langchain_openai import OpenAI
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.pydantic_v1 import BaseModel, Field
from langchain.agents.agent_types import AgentType
from langchain_experimental.agents.agent_toolkits import create_pandas_dataframe_agent
from langchain.memory import ConversationBufferMemory
from langchain.chains import ConversationChain
from typing import List, DictCreating a Connection with GridDB
To interact with GridDB via a LangChain chatbot, you must create a connection with GridDB instance. To do so, you must create an object of the StoreFactory class using the get_instance() method. Next, call the get_store() method on the factor object and pass it the database hostname, cluster name, user, and password parameters.
In the following script, we create a connection with a GridDB instance and test if the connection is successful by creating a container object.
factory = griddb.StoreFactory.get_instance()
DB_HOST = "127.0.0.1:10001"
DB_CLUSTER = "myCluster"
DB_USER = "admin"
DB_PASS = "admin"
try:
gridstore = factory.get_store(
notification_member = DB_HOST,
cluster_name = DB_CLUSTER,
username = DB_USER,
password = DB_PASS
)
container1 = gridstore.get_container("container1")
if container1 == None:
print("Container does not exist")
print("Successfully connected to GridDB")
except griddb.GSException as e:
for i in range(e.get_error_stack_size()):
print("[", i, "]")
print(e.get_error_code(i))
print(e.get_location(i))
print(e.get_message(i))
Output:
Container does not exist
Successfully connected to GridDB
If the connection is successful, you should see the above message. Else, you can verify your credentials and try again.
Inserting Sample Data Into GridDB
We will create a Chatbot that will return information from a GridDB container.
We will create a GridDB container that contains world population statistics of different countries from 1970 to 2022. You can find more details about the dataset in my previous article on world population data analysis using GridDB.
You can download the dataset from Kaggle. The script below the world_population.csv you downloaded into a Pandas DataFrame.
## Dataset link: https://www.kaggle.com/datasets/iamsouravbanerjee/world-population-dataset
dataset = pd.read_csv(r"/home/mani/GridDB Projects/world_population.csv")
print(dataset.shape)
dataset.head()Output:
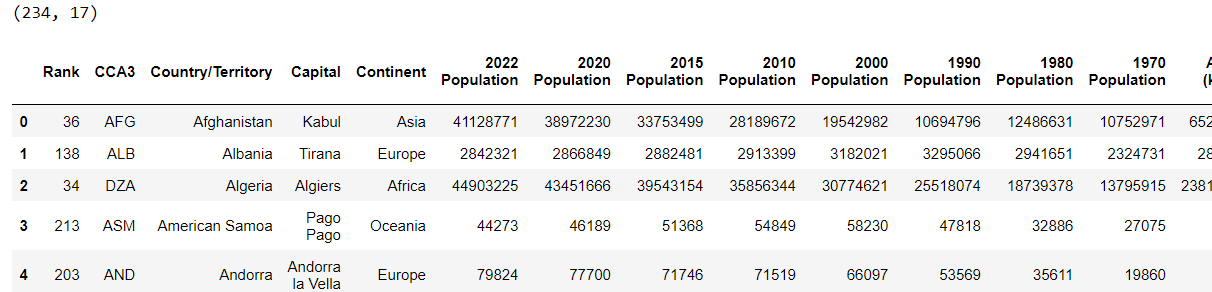
You can see that the dataset contains information such as country population, capital, continent, etc.
The dataset column contains special characters you must remove since GridDB doesn’t allow containers with column names to have special characters.
dataset.columns = dataset.columns.str.replace('[^a-zA-Z0-9]', '_', regex=True)
dataset.dtypesOutput:
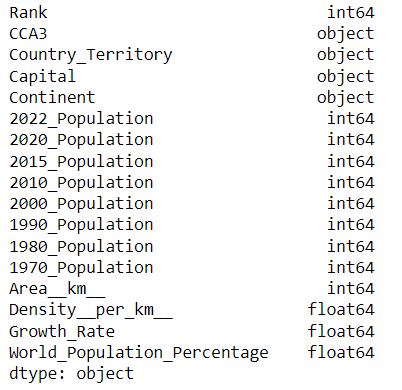
Next, we must map the DataFrame columns to the GridDB-compliant column types before inserting data into a GridDB container.
The following script inserts the data from the dataset DataFrame into a PopulationStats GridDB container.
# see all GridDB data types: https://docs.griddb.net/architecture/data-model/#data-type
def map_pandas_dtype_to_griddb(dtype):
if dtype == 'int64':
return griddb.Type.LONG
elif dtype == 'float64':
return griddb.Type.FLOAT
elif dtype == 'object':
return griddb.Type.STRING
# Add more column types if you want
else:
raise ValueError(f'Unsupported pandas type: {dtype}')
container_columns = []
for column_name, dtype in dataset.dtypes.items():
griddb_dtype = map_pandas_dtype_to_griddb(str(dtype))
container_columns.append([column_name, griddb_dtype])
container_info = griddb.ContainerInfo("PopulationStats",
container_columns,
griddb.ContainerType.COLLECTION, True)
try:
cont = gridstore.put_container(container_info)
for index, row in dataset.iterrows():
cont.put(row.tolist())
print("All rows have been successfully stored in the GridDB container.")
except griddb.GSException as e:
for i in range(e.get_error_stack_size()):
print("[", i, "]")
print(e.get_error_code(i))
print(e.get_location(i))
print(e.get_message(i))Output:
All rows have been successfully stored in the GridDB container.
Now that we have created a GridDB container containing sample records, we will create a LangChain chatbot that will allow you to retrieve information from the sample data container.
Creating a LangChain Chatbot to Interact with GridDB Data
In LangChain, you can create Chatbots using a wide range of large language (LLM) models. In this article, we will create a LangChain chatbot using GPT-4o, a state-of-the-art LLM from OpenAI.
To use GPT-4o in LangChain, you need to create an object of ChatOpenAI class and pass it your OpenAI API Key.
OPENAI_API_KEY = "YOUR_OPENAI_API_KEY"
llm = ChatOpenAI(api_key = OPENAI_API_KEY ,
temperature = 0,
model_name = "gpt-4o")Problem with Default LangChain Chains for Creating a Chatbot for Tabular Data
In my previous article, I explained how to perform CRUD operations on GridDB with LangChain.
The approach used in that article is good for interacting with GridDB using natural language if you already know the exact names of the GridDB container and columns. Otherwise, the LLM will attempt to retrieve information using made-up column names.
For instance, in the following section, we try to get the names of the top 3 countries with the highest population in 2020.
class SelectData(BaseModel):
container_name: str = Field(description="the container name from the user query")
query:str = Field(description="natural language converted to SELECT query")
system_command = """
Convert user commands into SQL queries for Griddb.
"""
user_prompt = ChatPromptTemplate.from_messages([
("system", system_command),
("user", "{input}")
])
select_chain = user_prompt | llm.with_structured_output(SelectData)
def select_records(query):
select_data = select_chain.invoke(query)
container_name = select_data.container_name
select_query = select_data.query
print(select_query)
result_container = gridstore.get_container(container_name)
query = result_container.query(select_query)
rs = query.fetch()
result_data = rs.fetch_rows()
return result_data
select_records("From the PopulationStats container, return the top 3 countries with the highest population in 2020")Output:
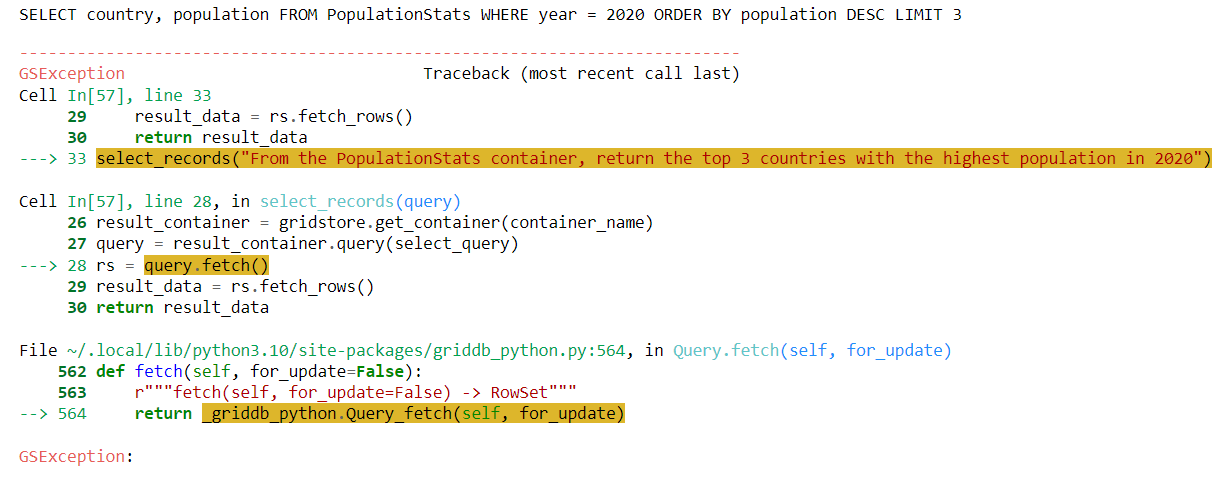
From the above output, you can see that the LLM generates a query that returns information from the country, population, and year columns. However, looking at the dataset, you will find no year column. Instead, the population information for the year 2020 is stored in the 2020 Population column.
To solve this problem, you can use LangChain agents.
LangChain Agents for Interacting with Tabular Data
To use LangChain agents, we will define a BaseModel class and a select_chain that extracts the container name and the additional query information from the user query.
class SelectData(BaseModel):
container_name: str = Field(description="the container name from the user query")
natural_query:str = Field(description = "user query string to retrieve additional information from result returned by the SELECT query")
system_command = """
Convert user commands into SQL queries for Griddb.
"""
user_prompt = ChatPromptTemplate.from_messages([
("system", system_command),
("user", "{input}")
])
select_chain = user_prompt | llm.with_structured_output(SelectData)
Next, we will define the select_records() function that accepts a user query and calls the select_chain to retrieve the container name and the additional query. The select_records() function retrieves the container data in Pandas DataFrame.
The next step is to create an OpenAI create_pandas_dataframe_agent() and pass to it the DataFrame containing the container data from the GridDB instance.
The additional query is passed to the agent’s invoke() method. The agent then retrieves information from the DataFrame based on the additional user query.
def select_records(query):
select_data = select_chain.invoke(query)
container_name = select_data.container_name
select_query = f"SELECT * FROM {container_name}"
natural_query = select_data. natural_query
print(f"Select query: {select_query}")
print(f"Additional query: {natural_query}")
result_container = gridstore.get_container(container_name)
query = result_container.query(select_query)
rs = query.fetch()
result_data = rs.fetch_rows()
agent = create_pandas_dataframe_agent(
ChatOpenAI(
api_key = OPENAI_API_KEY,
temperature=0,
model="gpt-4o"),
result_data,
verbose=True,
agent_type=AgentType.OPENAI_FUNCTIONS,
allow_dangerous_code = True
)
response = agent.invoke(f"Return the following information: {natural_query}")
return response
Let’s test the select_records method using the following query: From the PopulationStats container, return the top 3 countries with the highest population in 2020.
select_records("From the PopulationStats container, return the top 3 countries with the highest population in 2020")Output:
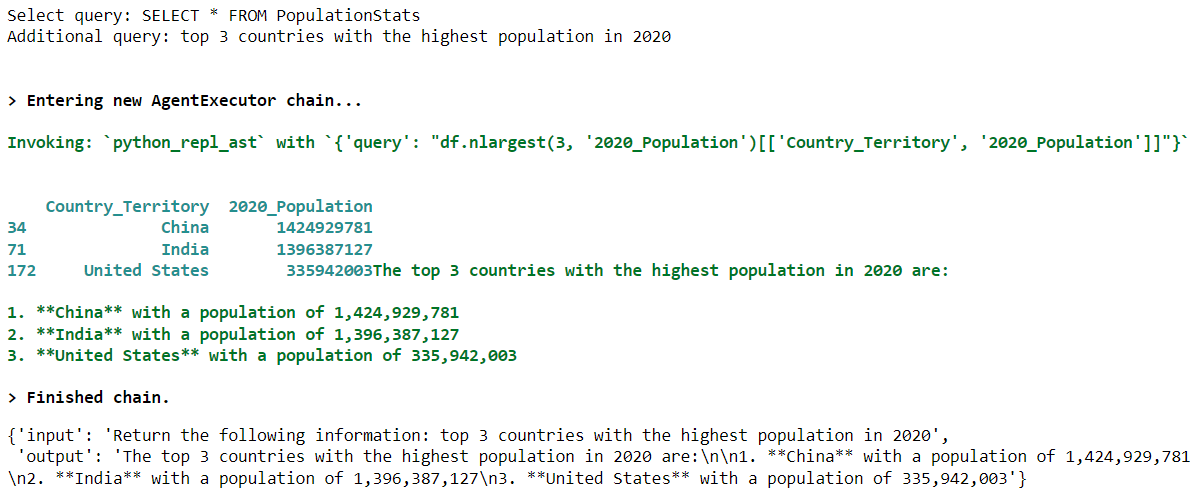
The output shows that the SELECT query selects all the records from the PopulationStats container, while the additional query fetches the top 3 countries with the highest population in 2020.
As you can see from the above output, the agent will know the column names of the PopulationStats container since it can access the corresponding result_data DataFrame and will return the required information.
Creating a LangChain Chatbot Interaction with GridDB Data
Now let’s create a chatbot capable of remembering the previous interaction.
I recommend that instead of repeatedly defining agents in the select_records function as you did in the previous script, you just fetch the container information in a DataFrame and then use that DataFrame once in the agent.
The following script defines SelectData base class and the select_records() function to retrieve the container name from the user query.
class SelectData(BaseModel):
container_name: str = Field(description="the container name from the user query")
query:str = Field(description="natural language converted to SELECT query")
system_command = """
Convert user commands into SQL queries for Griddb.
"""
user_prompt = ChatPromptTemplate.from_messages([
("system", system_command),
("user", "{input}")
])
select_chain = user_prompt | llm.with_structured_output(SelectData)
def select_records(query):
select_data = select_chain.invoke(query)
container_name = select_data.container_name
select_query = select_data.query
result_container = gridstore.get_container(container_name)
query = result_container.query(select_query)
rs = query.fetch()
result_data = rs.fetch_rows()
return result_data
result_data = select_records("SELECT all records from PopulationStats container")Next, we define the create_pandas_dataframe_agent and the get_response() functions, which accept a user query and return information about the Pandas DataFrame using the create_pandas_dataframe_agent agent.
To implement the chatbot functionality, we can define the chat_with_agent() function, which executes a while loop that keeps calling the get_response() function and prints the agent response on the console. The loop terminates when a user enters’ bye, quit, orexit`.
agent = create_pandas_dataframe_agent(
ChatOpenAI(
api_key=OPENAI_API_KEY,
temperature=0,
model="gpt-4"
),
result_data,
agent_type=AgentType.OPENAI_FUNCTIONS,
allow_dangerous_code=True,
)
def get_response(natural_query):
# Create a conversation chain
# Get the response from the agent
response = agent.invoke(f"Return the following information: {natural_query}")
# Add the interaction to the conversation memory
return response
# Function to chat with the agent
def chat_with_agent():
while True:
user_input = input("You: ")
if user_input.lower() in ['exit', 'quit', 'bye']:
print("AI: Goodbye!")
break
response = get_response(user_input)
print(f"AI: {response['output']}")
chat_with_agent()Output:

From the above output, you can see chatbot-like functionality retrieving responses about the world population dataset from the GridDB container.
Conclusion
In this article, you learned how to create a LangChain chatbot to interact with GridDB data using natural language queries. We explored how to connect Python to GridDB, insert sample data into a GridDB container, and retrieve information using LangChain agents. We also demonstrated how you can create a chatbot using LangChain agents.
GridDB is a highly scalable NoSQL database designed to handle large volumes of real-time data, making it well-suited for the Internet of Things (IoT) and big data applications. With advanced in-memory processing capabilities and efficient time series data management, GridDB can effectively manage large datasets.
If you have any questions about the blog, please create a Stack Overflow post here https://stackoverflow.com/questions/ask?tags=griddb .
Make sure that you use the “griddb” tag so our engineers can quickly reply to your questions.