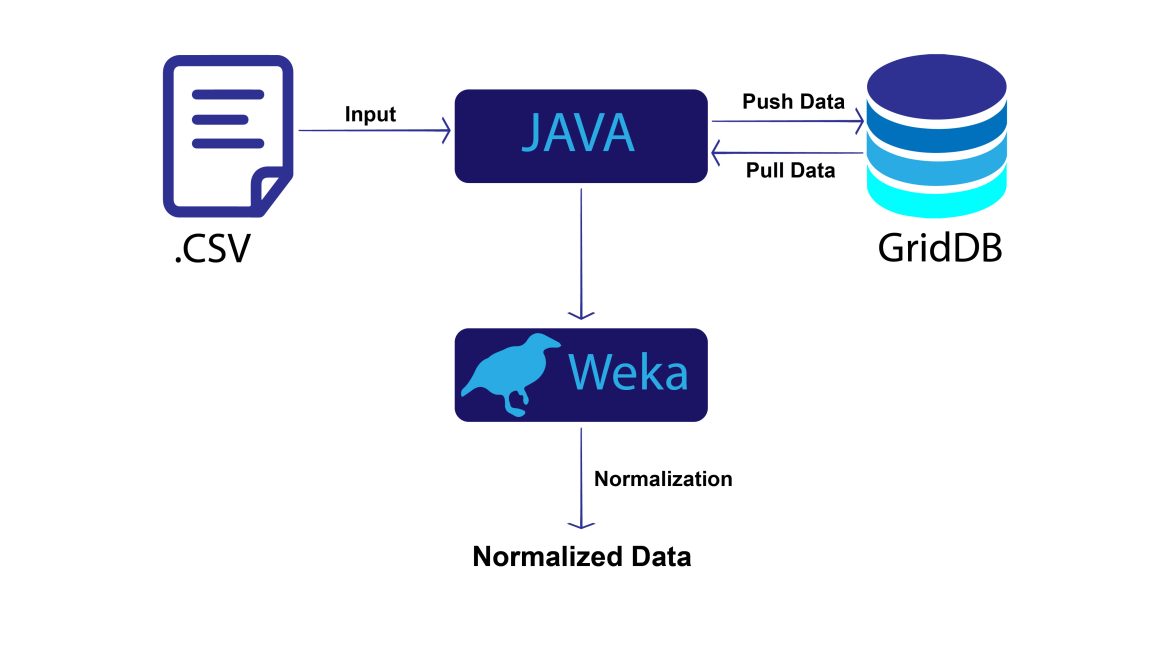
In this blog post, we will demonstrate normalizing data for machine learning with Java and GridDB.
Source code for this blog can be found on our Github page: https://github.com/griddbnet/Blogs
$ git clone https://github.com/griddbnet/Blogs.git --branch normalizationBefore we get started, Let’s understand normalization first.
What is Normalization?
Normalization is a commonly used data preparation technique in Machine Learning that changes the values of columns in the dataset using a common scale. Normalization is required when a range of characteristics are present in the dataset.
In our project, we’re going to use the dataset house.csv that looks something like this:
housesize,lotsize,bedrooms,granite,bathroom,sellingprice
3529,9191,6,0,0,205000
3247,10061,5,1,1,224900
4032,10150,5,0,1,197900
2397,14156,4,1,0,189900
2200,9600,4,0,1,195000
3536,19994,6,1,1,325000
2983,9365,5,0,1,230000You can see that the dataset contains large numbers with different ranges, making it difficult to perform data analytics operations.
With normalization, we can simplify this dataset by changing the column values on a common scale, such as ranging column values between 0 and 1. Looks something like this.
housesize,lotsize,bedrooms,granite,bathroom,sellingprice
0.571507,0.080533,0.5,1,1,224900
0.107533,0.459595,0,1,0,189900
0.729258,1,1,1,1,325000
0.725437,0,1,0,0,205000
1,0.088772,0.5,0,1,197900
0,0.03786,0,0,1,195000
0.427402,0.016107,0.5,0,1,230000You may notice that the column sellingprice remains unchanged. This is because the classifier must know which is our outcome variable.
That’s why we set the column sellingprice as our class index for the dataset before passing it to the classifier. You will observe it practically later in this article.
The following formula defines normalization mathematically.
Xn = (X – Xmin) / (Xmax – Xmin)
Where,
Xn = Normalized value.
Xmin = Minimum value of a feature.
Xmax = Maximum value of a feature.
Types of Normalization
Many types of normalization are available in machine learning. But the following types are widely used:
Min-Max Scaling: This type of normalization subtracts the minimum value from the highest value of each column and divides it by the range. Each new column has a minimum value of 0 and a maximum value of 1.
Standardization Scaling: Also known as Z-score normalization centers a variable at zero and standardizes the variance at one. It first subtracts the mean of each observation and then divides it by the standard deviation.
That’s enough for the theory. Let’s dive into something practical.
How to use Normalization?
Project Setup
Our project implements a basic level of normalization in Java and GridDB. Here is the project organization.
To run this project, your system should have:
– Java (Latest version)
– GridDB
Required JAR files
We need two JAR files gridstore-5.5.0.jar and weka-3.7.0.jar. Here, gridstore-5.5.0.jar is an official library for GridDB, and weka-3.7.0.jar is a Machine Learning library used for data analysis.
Download the Weka JAR from the following URL:
http://www.java2s.com/Code/Jar/w/weka.htm
Download the gridstore.jar from here:
https://mvnrepository.com/artifact/com.github.griddb/gridstore-jdbc/5.5.0
Import Packages
For this project, we need some basic Java packages, such as:
import java.util.Properties;
import java.util.Scanner;
import java.io.File;
import java.io.Reader;
import java.io.StringReader;Include the following packages to connect and operate GridDB:
import com.toshiba.mwcloud.gs.Collection;
import com.toshiba.mwcloud.gs.GSException;
import com.toshiba.mwcloud.gs.GridStore;
import com.toshiba.mwcloud.gs.GridStoreFactory;
import com.toshiba.mwcloud.gs.Query;
import com.toshiba.mwcloud.gs.RowKey;
import com.toshiba.mwcloud.gs.RowSet;For data analysis, include these packages from Weka:
import weka.classifiers.Evaluation;
import weka.classifiers.functions.LinearRegression;
import weka.core.Instances;
import weka.filters.Filter;
import weka.filters.unsupervised.attribute.Normalize;Well, that’s the initial step.
Let’s move on to our next step.
Creating a Class for Storing Data
Our project stores data in a GridDB container. So, we need to define the container schema as a static class:
static class House {
@RowKey int housesize;
int lotsize;
int bedrooms;
int granite;
int bathroom;
int sellingprice;
}The static class House consists of six integer-type columns with a RowKey housesize.
Creating a GridDB Connection
We have the schema class ready. It’s time to connect our program with GridDB.
For creating GridDB connection, we have to initiate a Properties instance defining the credentials for GridDB installation. Have a look at the following code:
Properties props = new Properties();
props.setProperty("notificationMember", "127.0.0.1:10001");
props.setProperty("clusterName", "myCluster");
props.setProperty("user", "admin");
props.setProperty("password", "admin");
GridStore store = GridStoreFactory.getInstance().getGridStore(props);You may need to change these connection specifics based on your GridDB installation.
Once you have successfully created your connection, it’s time to create a collection.
Collection coll = store.putCollection("House", House.class);Here, we created a collection object coll for the container House.
Push Data to GridDB
Now we have our GridDB schema and our connection is ready to go.
Let’s put some data to it,
In this purpose, we will retrive data from the house.csv file and push them to GridDB. The following code block achieves this task,
File file1 = new File("house.csv");
Scanner scan = new Scanner(file1);
String data = scan.next();
while (scan.hasNext()){
String scanData = scan.next();
String dataList[] = scanData.split(",");
String housesize = dataList[0];
String lotsize = dataList[1];
String bedrooms = dataList[2];
String granite = dataList[3];
String bathroom = dataList[4];
String sellingprice = dataList[5];
House hs = new House();
hs.housesize = Integer.parseInt(housesize);
hs.lotsize = Integer.parseInt(lotsize);
hs.bedrooms = Integer.parseInt(bedrooms);
hs.granite = Integer.parseInt(granite);
hs.bathroom = Integer.parseInt(bathroom);
hs.sellingprice = Integer.parseInt(sellingprice);
coll.put(hs);
}We created an object of our schema class House to push data to the container.
Retrieve Data from GridDB
Let’s pull data from the GridDB container and make the data available for analysis. Use the following code.
Query query = coll.query("select *");
RowSet rs = query.fetch(false); Query data from GridDB is similar to general SQL queries. Here, we used the query select * to retrieve all the data from the GridDB container.
We’ll save these data into a string for our next step.
String datastr = "@RELATION housenn@ATTRIBUTE houseSize NUMERICn@ATTRIBUTE lotSize NUMERICn@ATTRIBUTE bedrooms NUMERICn@ATTRIBUTE granite NUMERICn@ATTRIBUTE bathroom NUMERICn@ATTRIBUTE sellingPrice NUMERICnn@DATAn";
while (rs.hasNext()) {
House hs = rs.next();
datastr = datastr + hs.housesize+","+hs.lotsize+","+hs.bedrooms+","+hs.granite+","+hs.bathroom+","+hs.sellingprice+"n";
}Notice that we initialize the string datastr with the arff file structure.
Let’s see what the data looks like before normalization,
System.out.println("==== Before Normalization ===n"+datastr);Creating Weka Instances
We will use the Weka Machine Learning library for normalizing data. Hence, we need to convert our data into Weka Instances.
Do you remember we stored data in the string datastr in our previous step?
Yes, we’re going to pass that string in our Weka instances.
Reader dataString = new StringReader(datastr);
Instances dataset = new Instances(dataString);
dataset.setClassIndex(dataset.numAttributes()-1);The above code creates a Weka Instance.
Normalization
Let’s perform normalization to our dataset,
Normalize normalize = new Normalize();
normalize.setInputFormat(dataset);
Instances newdata = Filter.useFilter(dataset, normalize);Next, we are going to visualize data after normalization
System.out.println("==== After Normalization ===n"+newdata);Lastly, we just applied linear regression to our normalized data.
LinearRegression lr = new LinearRegression();
lr.buildClassifier(newdata);
Evaluation lreval = new Evaluation(newdata);
lreval.evaluateModel(lr, newdata);
System.out.println(lreval.toSummaryString());That’s all about the project. Let’s test it.
Compile and Execute
If you aren’t using any IDE, you may need to include the JAR files through the classpath:
export CLASSPATH=$CLASSPATH:/Home/User/Download/gridstore.jar
export CLASSPATH=$CLASSPATH:/Home/User/Download/weka-3.7.0.jarThese paths may differ based on your setup.
Now, you can compile the code using this command:
javac NormalizationJava.javaThen execute the code:
java NormalizationJavaShowing the Output
Running the code, you’ll have the following output:
==== Before Normalization ===
@RELATION house
@ATTRIBUTE houseSize NUMERIC
@ATTRIBUTE lotSize NUMERIC
@ATTRIBUTE bedrooms NUMERIC
@ATTRIBUTE granite NUMERIC
@ATTRIBUTE bathroom NUMERIC
@ATTRIBUTE sellingPrice NUMERIC
@DATA
3247,10061,5,1,1,224900
2397,14156,4,1,0,189900
3536,19994,6,1,1,325000
3529,9191,6,0,0,205000
4032,10150,5,0,1,197900
2200,9600,4,0,1,195000
2983,9365,5,0,1,230000
==== After Normalization ===
@relation house-weka.filters.unsupervised.attribute.Normalize-S1.0-T0.0
@attribute houseSize numeric
@attribute lotSize numeric
@attribute bedrooms numeric
@attribute granite numeric
@attribute bathroom numeric
@attribute sellingPrice numeric
@data
0.571507,0.080533,0.5,1,1,224900
0.107533,0.459595,0,1,0,189900
0.729258,1,1,1,1,325000
0.725437,0,1,0,0,205000
1,0.088772,0.5,0,1,197900
0,0.03786,0,0,1,195000
0.427402,0.016107,0.5,0,1,230000
Correlation coefficient 0.9945
Mean absolute error 4053.821
Root mean squared error 4578.4125
Relative absolute error 13.1339 %
Root relative squared error 10.51 %
Total Number of Instances 7
BUILD SUCCESSFUL (total time: 1 second)Wrapping Up
That’s all for normalization in Java with GridDB.
This article demonstrates applying normalization to the dataset for better analysis. As we mentioned, normalization is helpful when the dataset contains a range of characteristics.
Finally, make sure you close the query, container, and the GridDB database.
query.close();
coll.close();
store.close(); If you have any questions about the blog, please create a Stack Overflow post here https://stackoverflow.com/questions/ask?tags=griddb .
Make sure that you use the “griddb” tag so our engineers can quickly reply to your questions.