VitalWatch: Real-Time Wearable Health Monitoring with GridDB Cloud
More
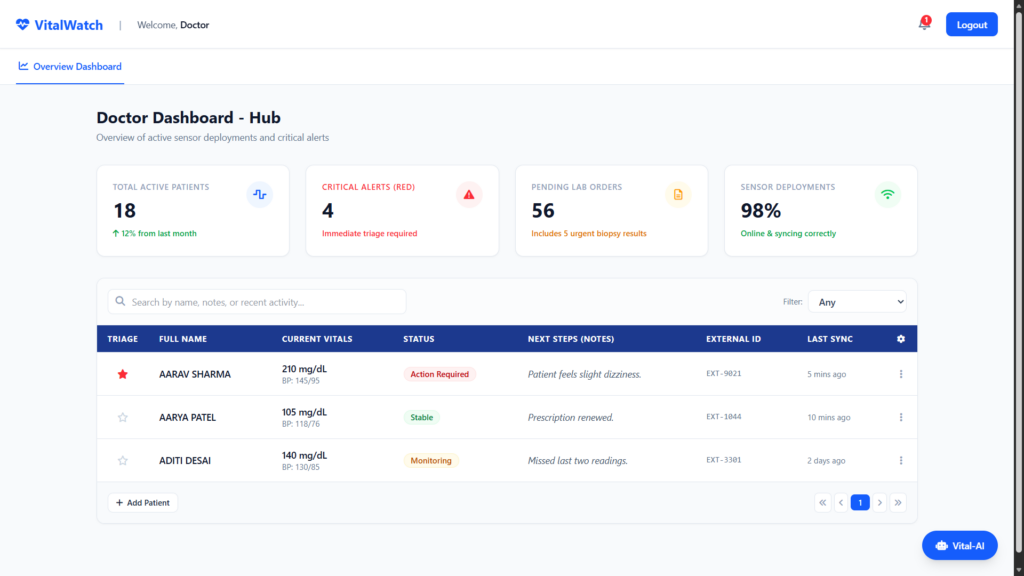
> Medical Disclaimer: All health metric estimations in this project (blood pressure, blood sugar) are simplified rule-based simulations for demonstration and educational purposes only. They are not clinically accurate and should never be used for real medical decision-making. This blog is the longer version of the hackathon entry from VitalWatch. You can see their original submission here: https://gallery.griddb.net/projects/vitalwatch.md Introduction In healthcare, early warning often means the difference between a manageable situation and a critical emergency. Wearable devices like smartwatches and fitness bands now collect continuous streams of biometric data — heart rate, blood oxygen, temperature, and activity level — all day long. While there is no shortage of data, most systems fail by evaluating each vital sign in isolation. They flag a high heart rate or a low SpO2 reading independently, without asking the obvious follow-up question: are these two changes happening at the same time, and in a physiologically connected way? A standalone elevated heart rate reading might mean the wearer just walked upstairs. But if heart rate rises and SpO2 simultaneously drops and body temperature climbs — that is a physiological chain event, not a coincidence. Most dashboards miss that story. VitalWatch addresses exactly this gap. Rather than building another static alert panel, we built a Wearable Health Intelligence Layer on top of GridDB Cloud that stores continuous vital sign streams, detects physiological chain events across multiple vital signs, and estimates derived health metrics like blood pressure and blood sugar from the raw sensor data. Why Time-Series Databases Matter for Wearable Health IoT A standalone SpO2 reading of 91% doesn’t tell the whole story. If it dropped from 98% in twenty minutes, it could indicate respiratory distress; if it has safely fluctuated between 90-92% for hours, it might just be a resting artifact. Evaluating sequences of readings over time provides the necessary context to tell the difference. Wearable devices generate this time-series data continuously — potentially dozens of readings per minute across multiple sensors. Traditional relational databases, optimized for structured record storage and joins, were not designed for the high-frequency append-heavy workloads that wearable telemetry produces. They can struggle with the combination of write volume, timestamped queries, and time-window aggregations that health monitoring requires. Time-series databases are purpose-built for this pattern. They act like a medical chart that never runs out of paper, allowing applications to look back at recent vital sign history and understand whether a wearer is moving toward an unsafe physiological state. Why GridDB Cloud for Wearable Health Monitoring GridDB Cloud provides an environment where sensor telemetry storage and retrieval are handled efficiently, letting the monitoring application focus entirely on health analysis rather than database infrastructure management. GridDB is a highly scalable, memory-first NoSQL database designed for high-frequency time-series IoT workloads. For VitalWatch, we use GridDB Cloud to: Store continuous wearable sensor data in TIME_SERIES containers with timestamp-based row keys. Maintain a fixed per-wearer schema for predictable, fast reads and writes. Ingest vital sign data in memory first and persist it safely to disk. Query recent time windows efficiently for early-warning detection. Correlate multiple vital sign streams in real time for chain event detection. Replay sensor history before an alert for physiological incident analysis. Provide the historical dataset that trains the machine learning health risk classifier. Without GridDB: Real-time multi-vital correlation would require expensive joins across separate tables. High-frequency wearable ingestion would create write bottlenecks. ML training on historical health data would require a separate ETL pipeline. System Architecture VitalWatch simulates a small health monitoring scenario for three wearers — an Athlete, an Elderly Patient, and an Office Worker — enrolled in a group monitoring program. Each wearer carries a simulated smartwatch that generates Heart Rate, SpO2, Body Temperature, and Activity Level readings. Derived health metrics (estimated blood pressure and blood sugar) are computed from the raw readings before storage. The overall system consists of the following main components: Sensor Simulation Layer A Python-based simulator generates realistic vital sign readings for each wearer. It applies a three-phase simulation model: Normal (all vitals safe), Stress (athlete begins showing cardiovascular signs), and Deterioration (athlete reaches critical levels while other wearers show secondary stress signals). Health Estimation Layer A rule-based estimator computes derived metrics — systolic/diastolic blood pressure and blood glucose — from the raw sensor values. These estimates are included in every row stored in GridDB so that the dashboard and ML model have access to the full health picture. Data Ingestion Layer The backend application receives simulated vital sign data and writes it to GridDB Cloud using the multi_put batch API, which allows rows for multiple wearer containers to be written in a single network round-trip. GridDB Cloud Database GridDB stores the complete vital sign history for each wearer in dedicated TIME_SERIES containers. The monitoring application queries this data to evaluate health conditions and detect physiological chain events. Monitoring Dashboard A web-based dashboard displays real-time vital signs, physiological chain alerts, and the fleet-wide health risk score. It polls the Flask API every three seconds and visualizes live trends using Chart.js. ML Health Risk Classifier A scikit-learn Random Forest classifier is trained directly on the historical data stored in GridDB. It learns to predict one of four health risk levels (Normal, Stress, Distress, Critical) from the seven-dimensional feature vector of each reading. Setting Up GridDB Cloud To store wearable telemetry, a GridDB Cloud instance can be deployed through the Microsoft Azure Marketplace. After subscribing, you receive the cluster connection details including the notification provider address, cluster name, and authentication credentials. Using the GridDB Python client, applications connect to the cluster through the native API. The following example shows how VitalWatch establishes a per-thread GridDB connection to avoid concurrency errors when multiple Flask worker threads are active: import griddb_python as griddb import threading _local = threading.local() def get_store(): """Return a per-thread GridDB connection to avoid concurrent access errors.""" if not hasattr(_local, "store") or _local.store is None: factory = griddb.StoreFactory.get_instance() _local.store = factory.get_store( notification_member=NOTIFICATION_MEMBER, cluster_name=CLUSTER_NAME, username=USERNAME, password=PASSWORD, ) return _local.store Connection credentials are read from environment variables so that no secrets appear in source code. Project Overview VitalWatch builds a smart health monitoring system for three simulated wearers enrolled in a group monitoring program. The system tracks each wearer’s vitals continuously and identifies early signs of physiological stress before they become critical events. Key ideas behind the system: Multi-vital monitoring: Rather than evaluating each vital sign independently, the system looks for correlated changes that indicate a linked physiological event. Physiological chain detection: It recognizes known biological relationships — for example, that falling SpO2 typically triggers compensatory heart rate elevation — and fires chain alerts when both sides of the correlation appear simultaneously. Profile-aware thresholds: Each wearer has individually tuned normal ranges and alert thresholds. An athlete’s resting heart rate of 55 bpm is healthy; the same reading might warrant attention for a sedentary office worker. Continuous risk scoring: Instead of a binary safe/unsafe flag, each wearer receives a 0–100 risk score that moves smoothly as vitals drift toward danger zones. Simulating Wearable Sensor Data Since real wearable devices are not available, the system uses a Python sensor simulator to generate realistic vital sign streams. The simulator creates readings for three wearer profiles: Athlete: Heart rate, SpO2, body temperature, activity level (trained physiology, lower resting HR) Elderly Patient: Heart rate, SpO2, body temperature, activity level (lower critical thresholds, highest monitoring priority) Office Worker: Heart rate, SpO2, body temperature, activity level (standard adult thresholds, sedentary baseline) To model a realistic health event, the dataset is generated across three phases: Normal: All wearers operating within their safe vital ranges. Stress: The athlete begins showing cardiovascular stress — heart rate rises, SpO2 drops. Deterioration: The athlete reaches critical levels; the elderly patient begins showing secondary stress; the office worker shows early signs of physiological disturbance. This models how a shared environmental trigger (extreme heat, altitude) affects multiple wearers simultaneously. To make the simulation physically plausible rather than generating flat hardcoded values, the system uses proportional interpolation with environmental noise: def _interpolate(low: float, high: float, progress: float = None) -> float: """Smoothly interpolate between two boundary values with optional random progress.""" if progress is None: progress = random.uniform(0.0, 1.0) return low + progress * (high – low) def generate_reading(wearer_id, status="Normal", progress=0.0, timestamp=None): nrm = WEARERS[wearer_id]["normal"] thr = WEARERS[wearer_id]["thresholds"] if status == "Stress": # HR ramps upward; SpO2 begins to drop (inverted: lower = worse) hr_base = _interpolate(nrm["heart_rate"][1], thr["heart_rate"]["warning"], progress) spo2_base = _interpolate(nrm["spo2"][0], thr["spo2"]["warning"], progress) t_base = _interpolate(nrm["temperature"][1], thr["temperature"]["warning"], progress * 0.6) # Environmental noise added to every reading regardless of phase noise_hr = random.uniform(-2.0, 2.0) noise_spo2 = random.uniform(-0.3, 0.3) noise_temp = random.uniform(-0.1, 0.1) This approach ensures that simulated vitals drift naturally toward thresholds rather than jumping abruptly, making the dashboard transitions visually and physiologically meaningful. Health Metric Estimation One of VitalWatch’s key additions is a rule-based health estimator that derives secondary health metrics from the raw wearable sensor data. Since wearable devices primarily measure heart rate, SpO2, temperature, and motion, higher-order metrics like blood pressure and blood glucose must be inferred. The estimations use simplified physiological relationships that are deliberately documented as approximations: def estimate_systolic_bp(heart_rate: float, spo2: float, activity_level: float) -> float: """ Estimate systolic blood pressure (mmHg) from HR, SpO2, and activity. NOTE: Simplified demonstration formula — not clinically accurate. """ baseline = 120.0 hr_delta = (heart_rate – 72) * 0.50 # HR deviation from resting reference activity_adj = (activity_level / 10.0) * 4.0 spo2_stress = max(0.0, (96.0 – spo2) * 0.80) # hypoxic stress contribution noise = random.uniform(-3.0, 3.0) return round(baseline + hr_delta + activity_adj + spo2_stress + noise, 1) def estimate_blood_sugar(heart_rate: float, activity_level: float, spo2: float) -> float: """ Estimate blood glucose (mg/dL) from HR, activity, and SpO2. NOTE: Simplified demonstration formula — not clinically accurate. """ baseline = 90.0 hr_delta = (heart_rate – 70) * 0.30 activity_adj = activity_level * 0.40 spo2_stress = max(0.0, (96.0 – spo2) * 1.50) noise = random.uniform(-5.0, 5.0) return round(baseline + hr_delta + activity_adj + spo2_stress + noise, 1) A single derive_health_metrics() function acts as the entry point used by the sensor simulator so that every row stored in GridDB automatically includes the full estimated health picture: def derive_health_metrics(heart_rate, spo2, temperature, activity_level) -> dict: """Given raw vitals, return all derived health metric estimates.""" return { "systolic_bp": estimate_systolic_bp(heart_rate, spo2, activity_level), "diastolic_bp": estimate_diastolic_bp(heart_rate, activity_level), "blood_sugar": estimate_blood_sugar(heart_rate, activity_level, spo2), } Live Alert Simulation To demonstrate how a health deterioration event develops over time, the project includes a live alert simulation script. Rather than inserting a static pre-built dataset, the script gradually writes escalating vital sign readings into GridDB Cloud every second, mimicking how a real health event would evolve. The simulation follows three stages: Normal Baseline – All wearers within safe ranges for the first few seconds. Athlete Stress – The athlete’s heart rate climbs and SpO2 begins to drop, proportionally ramped using interpolation. Full Deterioration – The athlete reaches critical levels; the elderly patient shows secondary stress; the office worker starts showing early disturbance signals. A simplified view of the simulation loop is shown below: def trigger_alert(): """Simulates a live health event that persists until resolved on the dashboard.""" store = insert_data.get_gridstore() start_sim() # signals the Flask API that simulation is active i = 0 while is_sim_active(): ts = datetime.now(timezone.utc) batch = {} for wearer_id in WEARERS: # Determine target health state based on simulation phase target = determine_phase(i, wearer_id) row = make_row(ts, wearer_id, target) batch[WEARERS[wearer_id]["container"]] = [row] store.multi_put(batch) i += 1 time.sleep(1) When the dashboard operator clicks “Alert Addressed”, the Flask API clears the simulation flag. The script detects this, injects a final batch of normal-range readings into GridDB Cloud, and exits. Those healthy readings immediately restore the dashboard to a stable state without requiring a manual reset. Storing Health Data in GridDB Cloud After generating the simulated vital sign readings, the data is stored in GridDB Cloud so the monitoring system can access recent history. Each wearer is assigned their own TIME_SERIES container with a fixed schema that stores all raw and derived health metrics. The timestamp acts as the primary key, allowing efficient time-ordered storage and retrieval of each wearer’s health history. Creating a TIME_SERIES container per wearer: def setup_containers(store) -> dict: """Create one TIME_SERIES container per wearer profile.""" containers = {} for wearer_id, cfg in WEARERS.items(): con_info = griddb.ContainerInfo( cfg["container"], [ ["timestamp", griddb.Type.TIMESTAMP], ["heart_rate", griddb.Type.DOUBLE], ["spo2", griddb.Type.DOUBLE], ["temperature", griddb.Type.DOUBLE], ["activity_level", griddb.Type.DOUBLE], ["systolic_bp", griddb.Type.DOUBLE], # estimated ["diastolic_bp", griddb.Type.DOUBLE], # estimated ["blood_sugar", griddb.Type.DOUBLE], # estimated ], griddb.ContainerType.TIME_SERIES, ) containers[wearer_id] = store.put_container(con_info) return containers Inserting a full dataset using multi_put: def insert_dataset(store, dataset: dict) -> None: """Bulk-insert all wearer readings in a single multi_put call.""" batch = {} for wearer_id, readings in dataset.items(): container_name = WEARERS[wearer_id]["container"] rows = [] for r in readings: ts = datetime.fromisoformat(r["timestamp"].replace("Z", "+00:00")) rows.append([ts, r["heart_rate"], r["spo2"], r["temperature"], r["activity_level"], r["systolic_bp"], r["diastolic_bp"], r["blood_sugar"]]) batch[container_name] = rows store.multi_put(batch) The multi_put operation writes rows for all three wearer containers in a single request, significantly improving ingestion efficiency when handling continuous vital sign streams. Querying Health Data and Detecting Pre-Alert Conditions Once vital sign data is stored in GridDB Cloud, the monitoring system queries recent readings to evaluate each wearer’s health condition. The system retrieves the latest records from each wearer container using GridDB’s Time-Series Query Language (TQL). def query_recent(store, wearer_id: str, limit: int = 20) -> list: """Fetch the most recent readings for a wearer using GridDB TQL.""" container = store.get_container(WEARERS[wearer_id]["container"]) query = container.query(f"select * order by timestamp desc limit {limit}") rs = query.fetch() readings = [] while rs.has_next(): row = rs.next() readings.append({ "timestamp": row[0].isoformat(), "heart_rate": row[1], "spo2": row[2], "temperature": row[3], "activity_level": row[4], "systolic_bp": row[5], "diastolic_bp": row[6], "blood_sugar": row[7], }) return readings To avoid false alerts caused by momentary sensor spikes, the system evaluates health conditions using a rolling window of the three most recent readings. By averaging the latest values, the monitoring logic becomes stable and resistant to transient noise: window = readings[:3] avg_hr = sum(r["heart_rate"] for r in window) / len(window) avg_spo2 = sum(r["spo2"] for r in window) / len(window) avg_temp = sum(r["temperature"] for r in window) / len(window) avg_act = sum(r["activity_level"] for r in window) / len(window) A key implementation detail is the handling of SpO2 as an inverted vital: unlike heart rate or temperature where higher values indicate danger, a lower SpO2 value indicates physiological risk. The severity function handles both directions using an inverted flag in the threshold configuration: def vital_severity(value: float, vital_key: str, wearer_id: str) -> float: """Return a 0.0–1.5 severity score. Handles both normal and inverted vitals.""" thr = WEARERS[wearer_id]["thresholds"][vital_key] inverted = thr.get("inverted", False) if inverted: # SpO2: lower value = higher severity normal_safe = WEARERS[wearer_id]["normal"][vital_key][0] if value >= normal_safe: return 0.0 elif value >= thr["warning"]: return 0.30 * (normal_safe – value) / (normal_safe – thr["warning"]) elif value >= thr["critical"]: return 0.30 + 0.70 * (thr["warning"] – value) / (thr["warning"] – thr["critical"]) else: overshoot = (thr["critical"] – value) / max(thr["warning"] – thr["critical"], 0.1) return min(1.0 + overshoot * 0.5, 1.50) else: # HR, temperature, activity: higher value = higher severity … Risk Scoring Instead of a simple status label, each wearer receives a continuous risk score between 0 and 100 based on exactly how far their vital signs have drifted from their individual safe ranges. For example, an athlete with a heart rate of 160 bpm and an elderly patient both showing the same reading would receive very different risk scores, because their normal ranges and thresholds are configured independently. def wearer_risk_score(wearer_id, avg_hr, avg_spo2, avg_temp, avg_act) -> int: """Calculate a 0–100 health risk score using weighted vital severities.""" s_hr = vital_severity(avg_hr, "heart_rate", wearer_id) s_spo2 = vital_severity(avg_spo2, "spo2", wearer_id) s_temp = vital_severity(avg_temp, "temperature", wearer_id) s_act = vital_severity(avg_act, "activity_level", wearer_id) weighted = ( s_hr * VITAL_WEIGHTS["heart_rate"] + # 35% s_spo2 * VITAL_WEIGHTS["spo2"] + # 40% ← SpO2 carries most weight s_temp * VITAL_WEIGHTS["temperature"] + # 15% s_act * VITAL_WEIGHTS["activity_level"] # 10% ) return min(round(weighted * 100), 100) The fleet-wide risk score is a weighted average across all wearers — the elderly patient contributes 50% of the weight because they are the highest-priority monitoring subject. Active physiological chain events add extra penalty points on top. Physiological Chain Detection VitalWatch understands that vital signs are physiologically linked. A falling SpO2 causes the cardiovascular system to compensate by increasing heart rate. Sustained high heart rate generates excess metabolic heat, raising body temperature. These relationships are encoded as rules: VITAL_CHAIN_RULES = [ { "source": "spo2", "target": "heart_rate", "message": ( "Oxygen-Cardiac Chain: Falling SpO2 is driving compensatory heart rate elevation. " "The body is increasing cardiac output to offset reduced blood oxygen." ), }, { "source": "heart_rate", "target": "temperature", "message": ( "Cardiac-Thermal Chain: Elevated heart rate is correlating with rising body temperature. " "Increased metabolic activity is generating excess heat." ), }, { "source": "spo2", "target": "temperature", "message": ( "Full Physiological Chain: Simultaneous SpO2 desaturation and thermal elevation detected. " "This pattern may indicate acute physiological stress or systemic illness." ), }, ] The chain detection function evaluates each wearer’s per-vital statuses against these rules. A chain alert fires only when the source vital is in a danger state and the target vital also shows an at-risk reading — confirming a linked physiological event rather than an isolated measurement anomaly: def detect_health_chains(wearer_id: str, vital_statuses: dict) -> list: chains = [] danger = {"Distress", "Critical"} at_risk = {"Stress", "Distress", "Critical"} for rule in VITAL_CHAIN_RULES: src = vital_statuses.get(rule["source"], "Normal") tgt = vital_statuses.get(rule["target"], "Normal") if src in danger and tgt in at_risk: chains.append({ "wearer_id": wearer_id, "source": rule["source"], "target": rule["target"], "message": rule["message"], }) return chains Machine Learning Health Risk Classifier VitalWatch includes a complete machine learning pipeline that uses the historical data stored in GridDB to train a health risk classifier. The model learns to predict one of four health states — Normal, Stress, Distress, or Critical — from the seven-dimensional feature vector of a single wearable reading. Why Random Forest? Random Forest is an ideal fit for this task because it seamlessly handles mixed physiological features across different units without requiring normalization. It also remains highly robust even with the smaller datasets typical of wearable monitoring demos. Additionally, the model outputs clear feature importances, making its health risk predictions easily explainable. Loading data from GridDB The training pipeline loads all available readings directly from the GridDB containers: def load_training_data(store) -> tuple: """Query all readings from GridDB and build a feature matrix with auto-generated labels.""" X, y, wearer_labels = [], [], [] for wearer_id in WEARERS: readings = query_recent(store, wearer_id, limit=500) for r in readings: features = [r["heart_rate"], r["spo2"], r["temperature"], r["activity_level"], r["systolic_bp"], r["diastolic_bp"], r["blood_sugar"]] # Labels are generated using the same rule-based logic as the dashboard label = STATUS_TO_INT[analyze_wearer(wearer_id, [r])["status"]] X.append(features) y.append(label) return np.array(X), np.array(y), wearer_labels This approach makes labels consistent with the dashboard display: the ML model learns to replicate the same health risk judgments that the rule-based monitoring system makes, but as a learnable function of the raw feature values. Training and evaluation model = RandomForestClassifier( n_estimators=150, max_depth=10, min_samples_leaf=2, random_state=42, n_jobs=-1, ) model.fit(X_train, y_train) After training, the pipeline prints a classification report and confusion matrix, followed by ranked feature importances: Feature Importances: spo2 ████████████████████████████████████████ 0.3912 heart_rate ████████████████████████████████ 0.3104 systolic_bp ████████████ 0.1187 blood_sugar ████████ 0.0823 temperature █████ 0.0521 diastolic_bp ████ 0.0401 activity_level ██ 0.0052 SpO2 and heart rate emerge as the most predictive features — a result that aligns with the physiological chain rules encoded in the rule-based detection layer. Building the Monitoring Dashboard Visualization is essential for making vital sign data actionable. The VitalWatch dashboard was built using HTML, JavaScript, and Chart.js to display real-time wearer status, vital sign trend charts, physiological chain alerts, and the fleet-wide health risk score. The Flask backend exposes three main data API endpoints that the dashboard polls every three seconds: Endpoint What it returns GET /api/fleet (Main) Status of all wearers + chain alerts + risk score GET /api/wearer/ Vital sign history for a single wearer (used for charts) GET /api/timeline Log of health status transitions over time A simplified view of the dashboard polling function: async function pollFleet() { try { const res = await fetch('/api/fleet'); const data = await res.json(); // Update each wearer card for (const [wearerId, status] of Object.entries(data.wearers)) { setCard(wearerId, status.status, status.message, status.latest); } renderChains(data.chains || []); updateFleetScore(data.risk_score ?? 0); } catch (e) { console.error('Fleet poll failed:', e); } } The dashboard calls the fleet endpoint every three seconds to keep the interface synchronized with the latest health data in GridDB Cloud. The chart endpoint provides rolling vital sign history for each wearer, rendered as a dual-axis mini trend chart (HR on the left axis, SpO2 on the right). Running the Project Make sure GridDB Cloud is running and credentials are configured as environment variables. Then run the following in order: # Step 1: Create containers and seed historical data $ $ python src/insert_data.py # Step 2: Start the monitoring backend $ $ python src/app.py # Step 3 (optional): Keep the dashboard alive with a live heartbeat $ $ python src/insert_data.py –live # Step 4 (optional): Trigger a live alert simulation $ $ python src/simulate_alert.py # Step 5 (optional): Train the ML health risk classifier $ $ python src/train_model.py Open http://localhost:5000 to view the dashboard. The Background Heartbeat (insert_data.py –live): This script provides a stable, healthy baseline so the dashboard stays “green” by default. The Manual Alert (simulate_alert.py): This script temporarily introduces a deteriorating health event to show how vital signs cascade. Click “Alert Addressed” in the dashboard to resolve it. One of the advantages of using GridDB for this architecture is automatic recovery: once the simulation finishes, the background producer continues sending normal-range readings. These healthy readings naturally displace the temporary critical spikes in the rolling query window, and the system returns to a safe state without a manual database reset. Results and Dashboard Overview After running the system, the monitoring dashboard displays the real-time health status of all three wearers. The interface shows live vital signs for Heart Rate, SpO2, Body Temperature, and Activity Level for each wearer, along with trend charts, chain alert panels, and the fleet-wide risk score. Normal State In the normal state, all wearers show green status indicators and a fleet risk score near 0. The escalation timeline panel is empty, confirming no status transitions have occurred. Stress Detected As the athlete’s heart rate climbs and SpO2 begins to fall, individual vital signs transition to warning state. The athlete card updates to “Stress” and the overall risk score begins rising. Physiological Chains Active When the athlete’s SpO2 drops into the danger zone while heart rate is simultaneously elevated, the system fires a chain alert: “Oxygen-Cardiac Chain: Falling SpO2 is driving compensatory heart rate elevation.” A second chain may fire if body temperature also begins rising. Alert Resolved Once the operator clicks “Alert Addressed,” the simulation stops, recovery readings are injected, and the dashboard returns to normal. The risk score drops back toward zero and chain alerts clear. By visualizing vital sign trends, physiological chain events, and fleet risk levels together, the dashboard gives health monitoring operators a clear and actionable picture of wearer health states. Conclusion Wearable health monitoring generates high-frequency, time-ordered data that tells a much richer story than any single sensor reading. Detecting that story requires a database purpose-built for time-series workloads and an analysis layer that understands physiological correlations rather than evaluating each vital in isolation. In this project, we built VitalWatch — a complete wearable health monitoring prototype using GridDB Cloud to store and query vital sign telemetry. By combining simulated sensor readings with rule-based physiological chain detection and a machine learning health risk classifier, the system can detect early warning patterns before they escalate into critical events. The complete implementation can be found in the project repository. : https://github.com/DoneByManthan/GridDB-VitalWatch.git In the future, this approach could be extended with: Personalized ML models trained on each wearer’s individual baseline rather than group averages stored in GridDB. Anomaly detection using unsupervised methods (e.g., Isolation Forest) on the GridDB historical data to catch unusual patterns that fall outside rule-defined thresholds. Real device integration by replacing the Python simulator with a Bluetooth LE or MQTT data ingestion layer that receives readings directly from consumer wearables. Federated learning where each wearer’s device trains a local model on-device and only sends model weight updates to a central server, preserving health data privacy while improving the global
Visualize GridDB Data Using LangGraph and OpenAI API
More
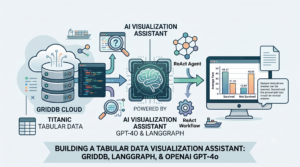
Large Language Models (LLMs) allow developers to combine advanced AI reasoning with powerful databases to analyze and visualize complex datasets. In this article, you will see how to build a tabular data visualization assistant using GridDB Cloud, LangGraph, and the OpenAI GPT-4o model. We will import the Titanic dataset into GridDB, query it programmatically, and then use a LangGraph ReAct agent to answer questions and generate plots automatically. GridDB’s flexible schema, high-performance design, and compatibility with structured data make it well-suited for storing both tabular and time series data. Prerequisites: You will need the following to run scripts in this article: A GridDB cloud account. Sign up for GridDB cloud and complete configuration settings. OpenAI API Key. You can use any other LLM provider, but you will need to update the scripts in this article slightly. Installing and Importing Required Libraries The following script installs and imports the required libraries for this application: !pip install langchain !pip install langchain-core !pip install langchain-community !pip install langgraph !pip install langchain_huggingface !pip install tabulate !pip uninstall -y pydantic !pip install –no-cache-dir "pydantic>=2.11,<3" import pandas as pd import json import datetime as dt import base64 import requests import numpy as np from pathlib import Path import matplotlib matplotlib.use("Agg") # safe, consistent backend import matplotlib.pyplot as plt from typing_extensions import Annotated from operator import add # used as list reducer from typing import TypedDict, List, Dict from pydantic import BaseModel, Field from IPython.display import Image, display from langchain_core.prompts import ChatPromptTemplate from langchain_core.tools import tool from langchain_openai import ChatOpenAI, OpenAI from langgraph.graph import START, END, StateGraph from langchain_core.messages import HumanMessage from langchain_experimental.agents import create_pandas_dataframe_agent from langgraph.prebuilt import create_react_agent from langchain.agents.agent_types import AgentType Importing the Dataset We will insert the Titanic dataset into GridDB and create visualizations using this data. The following script imports the data into a Pandas dataframe. dataset = pd.read_csv("https://raw.githubusercontent.com/datasciencedojo/datasets/refs/heads/master/titanic.csv", encoding = 'utf-8') dataset.head() Output: Establishing a Connection with GridDB Cloud To establish a connection with GridDB, replace your credentials in the following script and run it. username = "USER_NAME" password = "PASSWORD" base_url = "GRIDDB_CLOUD_URL" url = f"{base_url}/checkConnection" credentials = f"{username}:{password}" encoded_credentials = base64.b64encode(credentials.encode()).decode() headers = { 'Content-Type': 'application/json', # Added this header to specify JSON content 'Authorization': f'Basic {encoded_credentials}', 'User-Agent': 'PostmanRuntime/7.29.0' } response = requests.get(url, headers=headers) print(response.status_code) print(response.text) Output: 200 If you see the above message, you have successfully connected with GridDB cloud. Inserting Data in GridDB Cloud Dataset To insert data in GridDB, you first need to map your dataset types to GridDB dataset types and then create a GridDB container. Creating a Container for the Titanic Dataset in GridDB The following script maps your dataset column types to GridDB column types. dataset.insert(0, "SerialNo", dataset.index + 1) dataset.columns.name = None # Mapping pandas dtypes to GridDB types type_mapping = { "int64": "LONG", "float64": "DOUBLE", "bool": "BOOL", 'datetime64': "TIMESTAMP", "object": "STRING", "category": "STRING", } # Generate the columns part of the payload dynamically columns = [] for col, dtype in dataset.dtypes.items(): griddb_type = type_mapping.get(str(dtype), "STRING") # Default to STRING if unknown columns.append({ "name": col, "type": griddb_type }) print(columns) [{'name': 'SerialNo', 'type': 'LONG'}, {'name': 'PassengerId', 'type': 'LONG'}, {'name': 'Survived', 'type': 'LONG'}, {'name': 'Pclass', 'type': 'LONG'}, {'name': 'Name', 'type': 'STRING'}, {'name': 'Sex', 'type': 'STRING'}, {'name': 'Age', 'type': 'DOUBLE'}, {'name': 'SibSp', 'type': 'LONG'}, {'name': 'Parch', 'type': 'LONG'}, {'name': 'Ticket', 'type': 'STRING'}, {'name': 'Fare', 'type': 'DOUBLE'}, {'name': 'Cabin', 'type': 'STRING'}, {'name': 'Embarked', 'type': 'STRING'}] Next, we will create a collection type container titanic_db in our GridDB cloud database. url = f"{base_url}/containers" container_name = "titanic_db" # Create the payload for the POST request payload = json.dumps({ "container_name": container_name, "container_type": "COLLECTION", "rowkey": True, # Assuming the first column as rowkey "columns": columns }) # Make the POST request to create the container response = requests.post(url, headers=headers, data=payload) # Print the response print(f"Status Code: {response.status_code}") Output: Status Code: 201 Inserting Titanic Dataset in GridDB Next, we will iterate through the rows in our dataset, create a JSON payload containing the data, and will insert the data into the container we created in the previous section. url = f"{base_url}/containers/{container_name}/rows" # Convert dataset to list of lists (row-wise) with proper formatting def format_row(row): formatted = [] for item in row: if pd.isna(item): formatted.append(None) # Convert NaN to None elif isinstance(item, bool): formatted.append(str(item).lower()) # Convert True/False to true/false elif isinstance(item, (int, float)): formatted.append(item) # Keep integers and floats as they are else: formatted.append(str(item)) # Convert other types to string return formatted # Prepare rows with correct formatting rows = [format_row(row) for row in dataset.values.tolist()] # Create payload as a JSON string payload = json.dumps(rows) # Make the PUT request to add the rows to the container response = requests.put(url, headers=headers, data=payload) # Print the response print(f"Status Code: {response.status_code}") print(f"Response Text: {response.text}") Output: Status Code: 200 Response Text: {"count":891} The above output shows that the data has been successfully inserted into GridDB. Next, we will see how to retrieve data from GridDB and plot visualizations using it. Visualizing GridDB Results Using OpenAI and ReAct Agent The following script reads data from GridDB and inserts it in a Pandas dataframe. container_name = "titanic_db" url = f"{base_url}/containers/{container_name}/rows" # Define the payload for the query payload = json.dumps({ "offset": 0, # Start from the first row "limit": 10000, # Limit the number of rows returned "condition": "", # No filtering condition (you can customize it) "sort": "" # No sorting (you can customize it) }) # Make the POST request to read data from the container response = requests.post(url, headers=headers, data=payload) # Check response status and print output print(f"Status Code: {response.status_code}") if response.status_code == 200: try: data = response.json() print("Data retrieved successfully!") # Convert the response to a DataFrame rows = data.get("rows", []) titanic_dataset = pd.DataFrame(rows, columns=[col for col in dataset.columns]) except json.JSONDecodeError: print("Error: Failed to decode JSON response.") else: print(f"Error: Failed to query data from the container. Response: {response.text}") print(titanic_dataset.shape) titanic_dataset.head() Output: Let’s try to plot the average for the passengers who survived and those who didn’t. We will use these values to verify the result from our ReAct agent. avg = titanic_dataset.groupby('Survived')['Fare'].mean().round(2) print(avg) Output: Survived 0 22.12 1 48.40 Name: Fare, dtype: float64 Creating a LangGraph ReAct Agent for Data Visualization To plot visualizations, we will create a LangGraph ReAct agent with two tools: df_answer and save_plot. The df_answer tool will use the create_pandas_dataframe_agent to retrieve information from the database, including the plot, if any. The save_plot tool saves the plot to the local drive. The following script defines the agent’s state and the large language model (OpenAI GPT-4o in this case) we will use to answer the user’s question. class State(TypedDict): question: str answer: str plots: Annotated[List[Dict[str, str]], add] api_key = "YOUR_OPENAI_API_KEY" llm = ChatOpenAI(model="gpt-4o", api_key=api_key, temperature = 0) Next, we define the create_pandas_dataframe_agent function that returns information from the Pandas dataframe retrieved from GridDB. We also define the df_answer tool that calls the create_pandas_dataframe_agent. df_agent = create_pandas_dataframe_agent(llm, titanic_dataset, verbose=True, agent_type=AgentType.ZERO_SHOT_REACT_DESCRIPTION, allow_dangerous_code=True) _LAST = {"fig": None} # keep a handle to the last real figure @tool("df_answer") def df_answer(question: str) -> str: """ Use the pandas DataFrame agent to compute/plot. IMPORTANT: do NOT call plt.show() or plt.close() in the generated code. """ res = df_agent.invoke( question ) # CAPTURE whichever figure the agent actually created fig_nums = plt.get_fignums() # existing figures in this process if fig_nums: _LAST["fig"] = plt.figure(fig_nums[-1]) # latest real figure return res["output"] The following script defines the save_plot tool that saves the plot generated by the df_answer tool. @tool("save_plot") def save_plot(filename: str = "plot.png", dpi: int = 200, close: bool = True) -> str: """ Save the most recent existing Matplotlib figure (not an empty gcf()). Returns {"plot": {"name": …, "path": …}} or {"error": …}. """ Path("plots").mkdir(exist_ok=True) fig = _LAST.get("fig") # Fallback: grab last live figure if we didn't capture yet if fig is None: nums = plt.get_fignums() if not nums: return json.dumps({"error": "no_figure", "message": "No active figure to save."}) fig = plt.figure(nums[-1]) # Render + save fig.tight_layout() try: fig.canvas.draw() # ensure render except Exception: pass out = Path("plots") / filename fig.savefig(out, dpi=dpi, bbox_inches="tight") if close: plt.close(fig) # avoid accumulating figures return json.dumps({"plot": {"name": filename, "path": str(out.resolve())}}) Finally we define the ReAct agent using the LLM and the tool we just defined. SYSTEM = """ You work over a Titanic pandas DataFrame. – To compute answers or create charts, call `df_answer(question=…)`. – If a plot should be saved, call `save_plot(filename=…, dpi=200)`. – Keep text concise. If you saved a plot, you may echo the absolute path. """ react = create_react_agent( llm, tools=[df_answer, save_plot], prompt=SYSTEM, ) The following script creates our final graph object. def run_react(state: State) -> State: out = react.invoke({"messages": [("user", state["question"])]}) msgs = out["messages"] final_text = msgs[-1].content new_plots = [] for m in msgs: # Tool messages include the tool's return in `content` try: data = json.loads(getattr(m, "content", "") or "{}") except Exception: data = None if isinstance(data, dict) and "plot" in data: new_plots.append(data["plot"]) # {"name": "…", "path": "…"} return {"answer": final_text, "plots": new_plots} graph_builder = StateGraph(State) graph_builder.add_node("ask_question", run_react) graph_builder.add_edge(START, "ask_question") graph_builder.add_edge("ask_question", END) graph = graph_builder.compile() display(Image(graph.get_graph(xray=True).draw_mermaid_png())) Output: The above output shows the flow of the graph. The user’s question is passed to the ReAct agent, which decides which tools it requires to answer the user’s query. Testing the Agent & Generating Responses Let’s test the agent. We will first ask a simple question that doesn’t require saving or plotting a graph. # A) plain Q&A s = graph.invoke({"question": "What is the average Fare for passengers that survive and those who did not?"}) print(f"\nFinal Answer: {s['answer']}") Output: The output displays the average fares for passengers who survived and those who did not. Note that these values are identical to the ones we retrieved earlier by executing a direct operation on the Pandas dataframe. Next, we will request our agent to plot a chart using the results. # B) plot + save (the agent will call save_plot internally) s = graph.invoke({ "question": ("Plot a bar chart of average Fare for passengers that survive and those who did not?"), }) print(f"\nFinal Answer: {s['answer']}") print("plots so far:", s["plots"]) Output: The output shows that the agent saved the plot and also returned its location in the output. If you open the plot, you can see the average fare by survival rate plotted in the form of a bar chart. Conclusion This article demonstrates how to integrate GridDB Cloud with LangGraph and OpenAI to create a ReAct agent that can query tabular datasets and generate visualizations. By combining structured storage with the reasoning power of LLMs, we developed a system that seamlessly handles both textual answers and graphical plots. If you have questions or need support with GridDB Cloud, feel free to post them on Stack Overflow using the griddb tag. The GridDB team will be happy to help. For the complete code and additional examples, visit GridDB Blogs GitHub

Storing OpenTelemetry Metrics, Traces, and Logs in GridDB Cloud with Kafka
More
OpenTelemetry (OTel) is an open-source, vendor-neutral observability framework for cloud-native software. Rather than tying an application to a single monitoring vendor, it defines a common way to generate, collect, and export telemetry across three signal types: metrics, traces, and logs; commonly called the three pillars of observability. Metrics are numeric measurements sampled over time, such as CPU utilization or request counts. Traces describe the path of a single request as it moves through a system, broken into individual units of work called spans. Logs are timestamped event records emitted by the application. The value of the three pillars comes from being able to correlate across them: spotting a latency spike in a trace, then jumping to the exact log lines emitted during that request. Realizing that benefit requires the signals to live somewhere you can query them together, which is where GridDB Cloud comes in. All three signals are, at their core, streams of timestamped events, making them a natural fit for a time-series database. We have written extensively about pairing Kafka with GridDB, because a data-ingestion pipeline like Kafka fits well with what GridDB is built for. Previously we used the GridDB Kafka Connector to push time-series data to GridDB Cloud over the Web API. With the release of GridDB Cloud v3.2, we can now connect to a cloud instance natively, without the Web API, which opens up a broader set of tools. In this article, we will use that native connection to land all three OpenTelemetry signals into GridDB Cloud through Kafka. We will collect host metrics from a local machine, instrument a small application to emit traces and logs, route everything through Kafka, flatten the nested OTLP payloads with a Go bridge, and sink each signal into its own GridDB Cloud TIME_SERIES container using the GridDB Kafka Connector. We will then write queries that analyze the data, per-operation latency profiles, error rates, metric summaries, and a cross-signal lookup that connects a failing trace to the logs it produced. GridDB’s design favors one container per series, TIME_SERIES containers are optimized per series, and a query scoped to a single container is faster than filtering one large mixed container. That principle shapes the whole pipeline: rather than dumping raw OTLP into one place, we explode it into one container per metric, plus one container each for spans and logs. At a high level, this is what we will build: Set up the OpenTelemetry Collector to scrape host metrics and receive application traces and logs, pushing each signal to Kafka. Set up Kafka to receive and store the raw OTLP data. Run a Go “bridge” that reads the dense, nested OTLP JSON and explodes it into flat, one-row-per-event topics — one per metric, one for spans, one for logs. Use the GridDB Kafka Connector to sink those flattened topics into GridDB Cloud. host metrics ─┐ ├─► OTel Collector ─► Kafka [otel-metrics] [otel-traces] [otel-logs] Instrumented app ─┘ │ Go bridge (flatten nested OTLP) │ Kafka [metric_system_cpu_utilization, …] [otel_spans] [otel_logs] │ Kafka Connect (GridDB sink) │ GridDB Cloud — one TIME_SERIES container per signal One naming detail to note up front: the raw input topics use hyphens (otel-metrics, otel-traces, otel-logs) and the bridge’s flattened output topics use underscores (metric_*, otel_spans, otel_logs). The output names double as GridDB container names, and the hyphen/underscore split lets the sink’s topic filter target only the flattened topics. OpenTelemetry Install OpenTelemetry from opentelemetry.io. In this case the Collector was installed on bare metal. Once installed, configure config.yaml to describe how the Collector should behave. The configuration below sets up all three pillars: the hostmetrics scraper produces metrics, while the otlp receiver accepts traces and logs from an instrumented application. Each pipeline exports to Kafka with OTLP-JSON encoding: receivers: otlp: protocols: grpc: endpoint: 0.0.0.0:4317 http: endpoint: 0.0.0.0:4318 hostmetrics: collection_interval: 10s scrapers: cpu: metrics: system.cpu.utilization: enabled: true memory: metrics: system.memory.utilization: enabled: true load: disk: processors: resourcedetection: detectors: [system] system: hostname_sources: [os] batch: timeout: 5s send_batch_size: 100 exporters: kafka: brokers: – localhost:9092 metrics: topic: otel-metrics encoding: otlp_json traces: topic: otel-traces encoding: otlp_json logs: topic: otel-logs encoding: otlp_json debug: verbosity: basic service: pipelines: metrics: receivers: [otlp, hostmetrics] processors: [resourcedetection, batch] exporters: [kafka, debug] traces: receivers: [otlp] processors: [resourcedetection, batch] exporters: [kafka, debug] logs: receivers: [otlp] processors: [resourcedetection, batch] exporters: [kafka, debug] The hostmetrics scraper is the metrics source, configured at the bottom of the file in the metrics pipeline; it exports to the otel-metrics topic. The resourcedetection processor attaches the host’s name to every signal as a resource attribute. Start the Collector by pointing it at the config: $ otelcol-contrib –config ~/otel-griddb/config.yaml Instrumenting an Application for Traces and Logs Host metrics arrive on their own through the scraper, but in a real world setting, you’d want to be collecting traces and logs coming from the application you’re monitoring. To mimic this sort of real-world-use-case, we have set up a small Python worker that simulates processing jobs and instrument it with OpenTelemetry’s auto-instrumentation. Auto-instrumentation works well in this case because the application does not need an SDK wired in by hand; the opentelemetry-instrument launcher configures everything based on the environment variables including the providers, exporters, and the logging handler. A representative worker: import logging import random import time import uuid from opentelemetry import trace logging.basicConfig(level=logging.INFO, format="%(asctime)s %(levelname)s %(message)s") log = logging.getLogger("job-worker") tracer = trace.get_tracer("job-worker") JOB_TYPES = ["transcode_video", "resize_image", "send_email", "build_report"] def process_job(job_type: str, job_id: str) -> None: with tracer.start_as_current_span(job_type) as span: span.set_attribute("job.id", job_id) span.set_attribute("job.type", job_type) duration = random.uniform(0.05, 1.5) log.info("job %s (%s) started", job_id, job_type) time.sleep(duration) if random.random() < 0.1: # occasionally fail, so the data has errors to query span.set_status(trace.Status(trace.StatusCode.ERROR, "job failed")) log.error("job %s (%s) failed after %.2fs", job_id, job_type, duration) return log.info("job %s (%s) completed in %.2fs", job_id, job_type, duration) def main() -> None: log.info("worker starting") while True: job_type = random.choice(JOB_TYPES) process_job(job_type, uuid.uuid4().hex[:8]) time.sleep(random.uniform(0.2, 0.8)) if __name__ == "__main__": main() Telemetry destinations are set through environment variables, which the launcher reads to decide where to send spans and logs: $ export OTEL_EXPORTER_OTLP_ENDPOINT=http://localhost:4317 $ export OTEL_EXPORTER_OTLP_PROTOCOL=grpc $ export OTEL_SERVICE_NAME=job-worker $ export OTEL_TRACES_EXPORTER=otlp $ export OTEL_LOGS_EXPORTER=otlp $ export OTEL_METRICS_EXPORTER=none Run the worker under the launcher: $ opentelemetry-instrument python worker.py As a tip, you can keep these exports in a file (for example otel-env.sh) and load them with source otel-env.sh. Pasting a multi-line block directly into a shell can silently corrupt the values if the newlines arrive as the literal characters \n — each variable then absorbs the leftover export keyword, producing names such as otlpnexport that fail at startup with Requested component ‘otlpnexport’ not found. Sourcing a file avoids the issue. The OTEL_SERVICE_NAME value is attached to every span and log as the service.name resource attribute, which the bridge promotes to a dedicated column. Kafka This setup uses the KRaft build of Kafka, which no longer requires a separate ZooKeeper process. Install Kafka and start it by pointing at the default config; installed via Homebrew, it starts like this: $ kafka-server-start $(brew –prefix)/etc/kafka/kraft/server.properties Kafka Plugins and the GridDB Sink Wiring Kafka to GridDB Cloud requires the GridDB connector and its supporting gridstore JARs. Gather them into a directory of your choosing — here, a griddb subdirectory under a kafka-plugins folder in the home directory: $ ➜ ls ~/kafka-plugins/griddb $ griddb-kafka-connector-0.6.jar gridstore-conf-5.8.0.jar $ gridstore-5.8.0.jar gridstore-jdbc-5.8.0.jar $ gridstore-advanced-5.8.0.jar gridstore-jdbc-call-logging-5.8.0.jar $ gridstore-call-logging-5.8.0.jar These JARs are gathered from the GridDB Cloud v3.2 support page. You will also need to build the GridDB Kafka Connector from this fork, which adds support for the connection.route and database configuration properties required for GridDB Cloud’s native connection. > Author note: Link the v3.2 support page (the [TODO v3.2 BLOG] reference from the original draft). Kafka Connect Kafka Connect needs a connect-standalone.properties worker configuration. Because the bridge emits Kafka Connect envelopes that carry an explicit schema, the value converter must have schemas enabled: # connect-standalone.properties bootstrap.servers=localhost:9092 key.converter=org.apache.kafka.connect.json.JsonConverter value.converter=org.apache.kafka.connect.json.JsonConverter key.converter.schemas.enable=false value.converter.schemas.enable=true offset.storage.file.filename=/tmp/connect.offsets offset.flush.interval.ms=10000 # Directory above the griddb folder; Connect scans subdirectories for plugins plugin.path=/Users/israelimru/kafka-plugins rest.port=8083 The sink configuration tells Connect how to push data to GridDB Cloud. A single sink handles all three signal types: every flattened topic — metrics, spans, and logs — carries a datetime field and maps to a TIME_SERIES container, so one topic filter and one timestamp transform cover them all. The TimestampConverter is essential: it coerces the integer epoch-millis datetime into a real Timestamp, which is what makes GridDB create a TIME_SERIES container keyed on time rather than a collection with a plain integer column. name=griddb-otel-sink connector.class=com.github.griddb.kafka.connect.GriddbSinkConnector tasks.max=1 cluster.name=[yourClusterName] user=[yourUser] password=[yourPassword] multicast=false notification.provider.url=[yourNotificationProviderURL] connection.route=PUBLIC database=[yourDatabase] container.type=TIME_SERIES topics.regex=metric_.*|otel_.* # Coerce the int64 epoch-millis datetime into a Timestamp before mapping, # so datetime becomes the TIMESTAMP row key of each TIME_SERIES container. transforms=TimestampConverter transforms.TimestampConverter.type=org.apache.kafka.connect.transforms.TimestampConverter$Value transforms.TimestampConverter.field=datetime transforms.TimestampConverter.target.type=Timestamp The topics.regex=metric_.|otel_. pattern matches the underscore output topics (metric_system_cpu_utilization, otel_spans, otel_logs) while ignoring the hyphenated raw inputs. Start the Connect worker with both files: $ connect-standalone ~/otel-griddb/connect-standalone.properties ~/otel-griddb/griddb-otel-sink.properties The connect-standalone command runs the Kafka Connect worker — the link between Kafka topics and external systems. It loads the GridDB sink plugin and starts the job defined in the sink properties, which consumes from the matching topics and writes each record as a row in GridDB Cloud. The Go Bridge OTLP JSON is deeply nested. A metrics message wraps resourceMetrics → scopeMetrics → metrics → dataPoints; a traces message wraps resourceSpans → scopeSpans → spans; logs follow the same shape. GridDB stores flat rows, so the bridge reads each raw OTLP topic and explodes it into flat, one-row-per-event records, each wrapped in a Kafka Connect envelope carrying its schema. The main loop dispatches on the source topic: switch rec.Topic { case metricsTopic: // otel-metrics produced, err = explode(rec.Value) case tracesTopic: // otel-traces produced, err = explodeTraces(rec.Value) case logsTopic: // otel-logs produced, err = explodeLogs(rec.Value) } Metrics The metrics handler walks down to each data point and emits one flat row per point, routing it to a per-metric topic (metricToTopic turns system.cpu.utilization into metric_system_cpu_utilization): func explode(payload []byte) ([]*kgo.Record, error) { var o otlpMetrics if err := json.Unmarshal(payload, &o); err != nil { return nil, fmt.Errorf("unmarshal otlp: %w", err) } var out []*kgo.Record for _, rm := range o.ResourceMetrics { host := hostFromResource(rm.Resource) for _, sm := range rm.ScopeMetrics { for _, m := range sm.Metrics { var series *dataSeries switch { case m.Gauge != nil: series = m.Gauge case m.Sum != nil: series = m.Sum default: continue // histograms not supported } topic := metricToTopic(m.Name) for _, dp := range series.DataPoints { val, ok := dpValue(dp) if !ok { continue } nanos, err := strconv.ParseInt(dp.TimeUnixNano, 10, 64) if err != nil { continue } envelope := connectEnvelope{ Schema: flatSchema, Payload: flatRow{ Datetime: nanos / 1_000_000, Value: val, Host: host, Unit: m.Unit, Attrs: attrsToString(dp.Attributes), }, } b, _ := json.Marshal(envelope) out = append(out, &kgo.Record{Topic: topic, Value: b}) } } } } return out, nil } Traces The traces handler pulls service.name and host.name from the resource, iterates down to individual spans, converts nanosecond timestamps to milliseconds, and computes each span’s duration from its start and end times: func explodeTraces(payload []byte) ([]*kgo.Record, error) { var o otlpTraces if err := json.Unmarshal(payload, &o); err != nil { return nil, fmt.Errorf("unmarshal otlp traces: %w", err) } var out []*kgo.Record for _, rs := range o.ResourceSpans { host := resourceAttr(rs.Resource, "host.name") service := resourceAttr(rs.Resource, "service.name") for _, ss := range rs.ScopeSpans { for _, s := range ss.Spans { startNs, err1 := strconv.ParseInt(s.StartTimeUnixNano, 10, 64) endNs, err2 := strconv.ParseInt(s.EndTimeUnixNano, 10, 64) if err1 != nil || err2 != nil { continue } envelope := spanEnvelope{ Schema: spanSchema, Payload: spanRow{ Datetime: startNs / 1_000_000, DurationMs: (endNs – startNs) / 1_000_000, TraceID: s.TraceID, SpanID: s.SpanID, ParentSpanID: s.ParentSpanID, Name: s.Name, Kind: s.Kind, StatusCode: s.Status.Code, ServiceName: service, Host: host, Attrs: attrsToString(s.Attributes), }, } b, _ := json.Marshal(envelope) out = append(out, &kgo.Record{Topic: spansContainer, Value: b}) } } } return out, nil } Its schema leaves datetime as int64; the sink’s TimestampConverter promotes it to a GridDB TIMESTAMP row key: var spanSchema = connectSchema{ Type: "struct", Name: "otel_span", Fields: []connectField{ {Type: "int64", Optional: false, Field: "datetime"}, {Type: "int64", Optional: false, Field: "duration_ms"}, {Type: "string", Optional: true, Field: "trace_id"}, {Type: "string", Optional: true, Field: "span_id"}, {Type: "string", Optional: true, Field: "parent_span_id"}, {Type: "string", Optional: true, Field: "name"}, {Type: "int32", Optional: true, Field: "kind"}, {Type: "int32", Optional: true, Field: "status_code"}, {Type: "string", Optional: true, Field: "service_name"}, {Type: "string", Optional: true, Field: "host"}, {Type: "string", Optional: true, Field: "attrs"}, }, } Logs The logs handler is structurally identical, walking resourceLogs → scopeLogs → logRecords and emitting one flat row per record to the otel_logs topic. Each row carries the record’s severity number and text, its body, the service.name/host.name from the resource, and — critically — the trace_id and span_id that tie the log back to the span that produced it. That correlation key is the reason for landing logs and traces in the same database, and we use it in the queries below. Build and run the bridge: $ go build -o bridge $ ./bridge It logs each input record it explodes: 2026/05/15 13:31:36 topic=otel-metrics offset=150 exploded into 58 records 2026/05/15 13:31:37 topic=otel-traces offset=151 exploded into 12 records 2026/05/15 13:31:37 topic=otel-logs offset=149 exploded into 9 records Running Everything With every piece in place, start the components in order: Kafka (KRaft) OTel Collector The instrumented worker (opentelemetry-instrument python worker.py) The Go bridge Kafka Connect (connect-standalone) Once running, Kafka Connect reports writing rows to GridDB Cloud, with a container per metric plus the span and log containers: [griddb-otel-sink|task-0] Put 1 record to buffer of container metric_system_cpu_load_average_15m [griddb-otel-sink|task-0] Put 1 record to buffer of container metric_system_disk_io [griddb-otel-sink|task-0] Put 1 record to buffer of container otel_spans [griddb-otel-sink|task-0] Put 1 record to buffer of container otel_logs In the GridDB Cloud console, the containers appear as TIME_SERIES. The otel_spans container holds one row per span — datetime (the span start) as the TIMESTAMP row key, plus duration_ms, the ID fields (trace_id, span_id, parent_span_id), the operation name, kind, status_code, service_name, host, and a flattened attrs string. The otel_logs container holds one row per log record, keyed on datetime, with severity_number, severity_text, body, trace_id, span_id, service_name, host, and attrs. Each metric_* container holds datetime, value, host, unit, and attrs. Here’s a brief look at what our data looks like in the GridDB Cloud Portal Querying the Data Storing telemetry is only useful if you can ask questions of it. The following queries move from simple feeds to genuine analysis, one pillar at a time, and finish by crossing between them. Metrics For a single metric, a one-line aggregate summarizes its range over the whole collection period — useful for spotting how much disk io has run: SELECT MIN(value) AS min_util, AVG(value) AS avg_util, MAX(value) AS max_util FROM metric_system_disk_io; Example run using the GridDB Cloud CLI Tool: $ ➜ ~ griddb-cloud-cli sql query -s "SELECT MIN(value) AS min_util, AVG(value) AS avg_util, MAX(value) AS max_util FROM metric_system_disk_io;" -r $ [{"stmt": "SELECT MIN(value) AS min_util, AVG(value) AS avg_util, MAX(value) AS max_util FROM metric_system_disk_io;" }] $ min_util,avg_util,max_util, $ [1.00627853312e+11 1.2719715549835805e+11 3.24776685568e+11] The latest readings give a live view of a single series: SELECT datetime, value, host FROM metric_system_disk_io ORDER BY datetime DESC LIMIT 20; Example run: $ ➜ ~ griddb-cloud-cli sql query -s "SELECT datetime, value, host FROM metric_system_disk_io ORDER BY datetime DESC LIMIT 20;" -r $ [{"stmt": "SELECT datetime, value, host FROM metric_system_disk_io ORDER BY datetime DESC LIMIT 20;" }] $ datetime,value,host, $ [2026-05-27T20:54:31.978Z 1.65120098304e+11 Israels-Mac.local] $ [2026-05-27T20:54:21.979Z 1.65116936192e+11 Israels-Mac.local] $ [2026-05-27T20:54:11.979Z 1.6481210368e+11 Israels-Mac.local] $ [2026-05-27T20:54:01.980Z 1.64800229376e+11 Israels-Mac.local] $ [2026-05-27T20:53:51.979Z 1.64774305792e+11 Israels-Mac.local] $ [2026-05-27T20:53:41.979Z 1.64678656e+11 Israels-Mac.local] $ [2026-05-27T20:53:31.979Z 1.64668919808e+11 Israels-Mac.local] $ [2026-05-27T20:53:21.980Z 1.6465928192e+11 Israels-Mac.local] $ [2026-05-27T20:53:11.979Z 1.64600336384e+11 Israels-Mac.local] $ [2026-05-27T20:53:01.979Z 1.64591157248e+11 Israels-Mac.local] $ [2026-05-27T20:52:51.996Z 1.64583391232e+11 Israels-Mac.local] $ [2026-05-27T20:52:41.980Z 1.64520382464e+11 Israels-Mac.local] $ [2026-05-27T20:52:31.979Z 1.64511981568e+11 Israels-Mac.local] $ [2026-05-27T20:52:21.980Z 1.64502102016e+11 Israels-Mac.local] $ [2026-05-27T20:52:11.979Z 1.64488118272e+11 Israels-Mac.local] $ [2026-05-27T20:52:01.979Z 1.64480098304e+11 Israels-Mac.local] $ [2026-05-27T20:51:51.979Z 1.6446855168e+11 Israels-Mac.local] $ [2026-05-27T20:51:41.979Z 1.6444940288e+11 Israels-Mac.local] $ [2026-05-27T20:51:31.979Z 1.64428091392e+11 Israels-Mac.local] $ [2026-05-27T20:51:21.979Z 1.64419739648e+11 Israels-Mac.local] Traces A few conventions matter for the trace and log queries. A span’s status_code is 0 for UNSET, 1 for OK, and 2 for ERROR. A log record’s severity_number follows fixed ranges: 1–4 TRACE, 5–8 DEBUG, 9–12 INFO, 13–16 WARN, 17–20 ERROR, 21–24 FATAL. The first real question for any traced system is where the time is going. Because each span carries its own duration_ms, a single grouped query produces a full latency profile per operation — minimum, average, and maximum duration with the call count: SELECT name, COUNT(*) AS calls, MIN(duration_ms) AS min_ms, AVG(duration_ms) AS avg_ms, MAX(duration_ms) AS max_ms FROM otel_spans GROUP BY name ORDER BY avg_ms DESC; $ ➜ ~ griddb-cloud-cli sql query -s "SELECT name, COUNT(*) AS calls, MIN(duration_ms) AS min_ms, AVG(duration_ms) AS avg_ms, MAX(duration_ms) AS max_ms FROM otel_spans GROUP BY name ORDER BY avg_ms DESC" -r $ [{"stmt": "SELECT name, COUNT(*) AS calls, MIN(duration_ms) AS min_ms, AVG(duration_ms) AS avg_ms, MAX(duration_ms) AS max_ms FROM otel_spans GROUP BY name ORDER BY avg_ms DESC" }] $ name,calls,min_ms,avg_ms,max_ms, $ [job.transcode_video 3535 11 1455.5188118811882 953212] $ [job.generate_report 3609 12 889.7420338043779 1.000412e+06] $ [job.sync_inventory 3569 24 285.75231157186886 2580] $ [job.resize_image 3587 7 120.47058823529412 1619] $ [job.send_email 3660 15 57.44672131147541 207] A high max_ms against a low avg_ms points to intermittent outliers. To inspect those outliers directly, sort by duration: SELECT ts, name, duration_ms, trace_id FROM otel_spans ORDER BY duration_ms DESC LIMIT 10; $ ➜ ~ griddb-cloud-cli sql query -s "SELECT ts, name, duration_ms, trace_id FROM otel_spans ORDER BY duration_ms DESC LIMIT 10" -r $ [{"stmt": "SELECT ts, name, duration_ms, trace_id FROM otel_spans ORDER BY duration_ms DESC LIMIT 10" }] $ ts,name,duration_ms,trace_id, $ [2026-07-01T21:39:34.774Z job.generate_report 1.000412e+06 11bedd5adde787c507fe6700220f2719] $ [2026-07-01T21:18:32.090Z job.transcode_video 953212 4c945d48dab3de71cf43e2be37bcc845] $ [2026-07-01T21:16:27.534Z job.transcode_video 107162 b23966ac1330eaff79a17b0c0adeb9b4] $ [2026-07-01T19:16:53.336Z job.transcode_video 8010 501f49c5d7a8b5e8774c2e8f013f27bf] $ [2026-07-01T22:26:21.396Z job.transcode_video 8010 9064d16e9f05ef6e67d2b7f32bc4368a] $ [2026-07-01T21:04:59.306Z job.transcode_video 8007 1a96c129efbba1ab93fc5263242b9f52] $ [2026-07-01T20:22:30.204Z job.transcode_video 8007 ad9e78a3ab6f3ab1bc21c9454395f6c5] $ [2026-07-01T20:44:08.697Z job.transcode_video 8006 b7429f02f990a3e7decd314ec8a61e45] $ [2026-07-01T20:29:03.554Z job.transcode_video 8006 84f1aa7a770aa5fc29ca409e71b93b6a] $ [2026-07-01T20:03:24.204Z job.transcode_video 8006 57207e6dedc7c6e24e76cb061e8e7022] Reliability is the next question. Since status_code = 2 marks an errored span, error counts per operation come from a single filtered aggregate: SELECT name, COUNT(*) AS errors FROM otel_spans WHERE status_code = 2 GROUP BY name ORDER BY errors DESC; $ ➜ ~ griddb-cloud-cli sql query -s "SELECT name, COUNT(*) AS errors FROM otel_spans WHERE status_code = 2 GROUP BY name ORDER BY errors DESC" -r $ [{"stmt": "SELECT name, COUNT(*) AS errors FROM otel_spans WHERE status_code = 2 GROUP BY name ORDER BY errors DESC" }] $ name,errors, $ [job.generate_report 344] $ [job.transcode_video 208] $ [job.sync_inventory 142] $ [job.resize_image 69] $ [job.send_email 34] Logs A severity breakdown gives a quick health summary: SELECT severity_text, COUNT(*) AS count FROM otel_logs GROUP BY severity_text ORDER BY count DESC; $ ➜ ~ griddb-cloud-cli sql query -s "SELECT severity_text, COUNT(*) AS count FROM otel_logs GROUP BY severity_text ORDER BY count DESC" -r $ [{"stmt": "SELECT severity_text, COUNT(*) AS count FROM otel_logs GROUP BY severity_text ORDER BY count DESC" }] $ severity_text,count, $ [INFO 17174] $ [ERROR 797] Filtering on the severity number isolates everything at ERROR level or above: SELECT datetime, severity_text, service_name, body FROM otel_logs WHERE severity_number >= 17 ORDER BY datetime DESC LIMIT 20; $ ➜ ~ griddb-cloud-cli sql query -s "SELECT ts, severity_text, service_name, body FROM otel_logs WHERE severity_number >= 17 ORDER BY ts DESC LIMIT 20" -r $ [{"stmt": "SELECT ts, severity_text, service_name, body FROM otel_logs WHERE severity_number >= 17 ORDER BY ts DESC LIMIT 20" }] $ ts,severity_text,service_name,body, $ [2026-07-01T22:48:29.403Z ERROR job-worker job d9dd3342 (generate_report) failed after 0.47s: rate limited] $ [2026-07-01T22:48:18.950Z ERROR job-worker job 070712fb (sync_inventory) failed after 0.06s: invalid payload] $ [2026-07-01T22:48:13.213Z ERROR job-worker job d56f92f3 (generate_report) failed after 0.39s: downstream timeout] $ [2026-07-01T22:48:11.816Z ERROR job-worker job 05ef9096 (generate_report) failed after 0.25s: invalid payload] $ [2026-07-01T22:48:00.613Z ERROR job-worker job 4441a1ec (transcode_video) failed after 3.86s: downstream timeout] $ [2026-07-01T22:47:55.657Z ERROR job-worker job 48491076 (generate_report) failed after 0.64s: connection refused] $ [2026-07-01T22:47:28.637Z ERROR job-worker job 51316b2b (transcode_video) failed after 0.17s: rate limited] $ [2026-07-01T22:47:26.343Z ERROR job-worker job b554b041 (transcode_video) failed after 0.53s: connection refused] $ [2026-07-01T22:47:24.968Z ERROR job-worker job 3e71df8a (generate_report) failed after 0.67s: downstream timeout] $ [2026-07-01T22:47:14.096Z ERROR job-worker job 31e1be77 (transcode_video) failed after 0.05s: invalid payload] $ [2026-07-01T22:47:12.386Z ERROR job-worker job f638a350 (transcode_video) failed after 0.75s: connection refused] $ [2026-07-01T22:47:01.852Z ERROR job-worker job 3fe1ac79 (generate_report) failed after 0.45s: invalid payload] $ [2026-07-01T22:46:36.300Z ERROR job-worker job 346819a2 (generate_report) failed after 1.38s: downstream timeout] $ [2026-07-01T22:46:28.549Z ERROR job-worker job 483cabb8 (resize_image) failed after 0.05s: connection refused] $ [2026-07-01T22:46:14.511Z ERROR job-worker job c438270a (transcode_video) failed after 0.09s: connection refused] $ [2026-07-01T22:45:49.406Z ERROR job-worker job 60e89b69 (generate_report) failed after 0.46s: connection refused] $ [2026-07-01T22:45:14.076Z ERROR job-worker job e3404a92 (send_email) failed after 0.09s: rate limited] $ [2026-07-01T22:45:11.384Z ERROR job-worker job e5eaabd8 (generate_report) failed after 1.36s: invalid payload] $ [2026-07-01T22:45:08.027Z ERROR job-worker job e207ee04 (generate_report) failed after 1.64s: invalid payload] $ [2026-07-01T22:44:55.155Z ERROR job-worker job 3af41a8b (generate_report) failed after 1.43s: invalid payload] Crossing Signals The most compelling result of collectingg traces and logs in the same database is correlation. Suppose the error query above flags an operation that fails often. We can take its most recent failing trace and pull every log record emitted during that exact request, joined on trace_id. First identify the trace: SELECT trace_id, name, duration_ms FROM otel_spans WHERE status_code = 2 ORDER BY datetime DESC LIMIT 1; $ ➜ ~ griddb-cloud-cli sql query -s "SELECT trace_id, name, duration_ms FROM otel_spans WHERE status_code = 2 ORDER BY ts DESC LIMIT 1" -r $ [{"stmt": "SELECT trace_id, name, duration_ms FROM otel_spans WHERE status_code = 2 ORDER BY ts DESC LIMIT 1" }] $ trace_id,name,duration_ms, $ [693c5d8f3479288991b91dafd43d20f1 job.generate_report 473] Then retrieve its logs in order: SELECT datetime, severity_text, body, span_id FROM otel_logs WHERE trace_id = '<trace_id from the previous result>' ORDER BY datetime; $ ➜ ~ griddb-cloud-cli sql query -s "SELECT ts, severity_text, body, span_id FROM otel_logs WHERE trace_id = '693c5d8f3479288991b91dafd43d20f1' ORDER BY ts" -r $ [{"stmt": "SELECT ts, severity_text, body, span_id FROM otel_logs WHERE trace_id = '693c5d8f3479288991b91dafd43d20f1' ORDER BY ts" }] $ ts,severity_text,body,span_id, $ [2026-07-01T22:48:29.403Z ERROR job d9dd3342 (generate_report) failed after 0.47s: rate limited 7492c1f55f487fe2] In two short queries we go from “this operation is failing” to the precise log lines explaining why an investigation that typically spans two separate systems, performed here against one database. Conclusion With this pipeline in place, all three OpenTelemetry signals land in GridDB Cloud through a single path: the Collector handles ingestion and fan-out to Kafka, the Go bridge flattens nested OTLP into one clean row per event, and the GridDB Kafka Connector — using GridDB Cloud v3.2’s native connection — sinks each signal into a purpose-built TIME_SERIES container. Because the data is queryable with standard aggregates and the trace identifier is shared between spans and logs, GridDB becomes a single backend for the correlated analysis that observability work depends on: metric summaries, latency profiling, error attribution, and trace-to-log

Building a Modern Job Board with Spring Boot & GridDB Cloud
More
In this tutorial, we’ll build a fully functional job board web application from the ground up. Our application will allow users to browse available positions, search for jobs based on specific skills, and administrators can manage job listings. We’ll be working with three powerful technologies: Spring Boot to handle our backend component, Thymeleaf for creating dynamic web pages, and GridDB Cloud as our scalable database solution. As an exciting bonus, we’ll also integrate Spring AI with OpenAI’s language model to automatically generate relevant skill tags from job descriptions. This project is designed to give you hands-on experience with real-world web development concepts. We’ll start with the basics, setting up our development environment and cofiguring our database connection, then gradually build up to more advanced features like search functionality and AI integration. By the time we’re finished, you’ll have a complete understanding of how modern web applications work, from data storage and business logic to user interfaces and AI-powered features. Prerequisites & Project Setup First, let’s make sure we have everything installed and configured properly before we start building our job board application. Development Tools: Java 17 or later, Maven 3.5+, and your favorite IDE (IntelliJ IDEA or VS Code) A GridDB Cloud account. You can sign up for a GridDB Cloud Free instance at https://form.ict-toshiba.jp/download_form_griddb_cloud_freeplan_e An OpenAI API account for the AI-powered skill generation feature. You can find your Secret API key on the API key page. After completing the prerequisites, we’ll create a new Spring Boot application using Spring Initializr. Here’s how we’ll set it up: Navigate to start.spring.io Configure your project: Project: Maven Language: Java Spring Boot: 3.5.x (latest stable version) Group: com.example Artifact: springboot-jobboard Java Version: 17 or later Add the following dependencies: Spring Web – for creating our REST controllers and web layer Thymeleaf – for server-side template rendering Spring Security – for basic authentication (we’ll keep it simple) Click Generate to download a ZIP file with our project structure Once you’ve downloaded and extracted the project, import it into your IDE. Then make sure we have the main project structure as follows: $ ├───java $ │ └───com $ │ └───example $ │ └───springbootjobboard $ │ ├───config $ │ ├───controller $ │ ├───domain $ │ ├───model $ │ ├───repos $ │ ├───rest $ │ ├───security $ │ ├───service $ │ ├───util $ │ └───webapi $ │ └───acquisition We’ll then add the additional dependencies we need for GridDB Cloud integration and AI-powered features. <dependency> <groupId>org.springframework.ai</groupId> <artifactId>spring-ai-starter-model-openai</artifactId> <version>1.0.1</version> </dependency> <dependency> <groupId>com.github.f4b6a3</groupId> <artifactId>tsid-creator</artifactId> <version>5.2.5</version> </dependency> <dependency> <groupId>org.apache.commons</groupId> <artifactId>commons-text</artifactId> <version>1.14.0</version> </dependency> > :bulb: Tip: If you prefer to skip the setup process, you can clone the completed project repository here. After adding all dependencies, next configure the application properties. GridDB Configuration griddbcloud.base-url=YOUR_GRIDDBCLOUD_BASE_URL griddbcloud.auth-token=YOUR_GRIDDBCLOUD_AUTH_TOKEN OpenAI API Key spring.ai.openai.api-key=${OPENAI_API_KEY} Then Export your Open AI API keys as environment variables: $ export OPENAI_API_KEY="your_api_key_here" Database Integration To access the GridDB Web API endpoint, we must provide an access token in the HTTP Authorization header. The access token is a Base64 encoded string of the username and password, separated by a colon. To access the configured values above, we need to bind the properties defined in the application.properties file to a POJO class using the @ConfigurationProperties annotation. // GridDbCloudClientProperties.java @Component @ConfigurationProperties(prefix = "griddbcloud") public class GridDbCloudClientProperties { private String baseUrl; private String authToken; //setter, getter } Next, we create GridDbCloudClient under webapi package, a centralized place to construct all HTTP requests to the GridDB Cloud Web API. // GridDbCloudClient.java public class GridDbCloudClient { private final RestClient restClient; public GridDbCloudClient(String baseUrl, String authToken) { this.restClient = RestClient.builder() .baseUrl(baseUrl) .defaultHeader("Authorization", "Basic " + authToken) .defaultHeader("Content-Type", "application/json") .defaultHeader("Accept", "application/json") .build(); } public void createContainer(GridDbContainerDefinition containerDefinition) { restClient .post() .uri("/containers") .body(containerDefinition) .retrieve() .toBodilessEntity(); } } The org.springframework.web.client.RestClient is built and configured only once during application startup, and the same instance is reused. Use baseUrl() to set the common base URL for all requests made to the GridDB Cloud Web API. Configure the Authorization header that should be included in every request by default using defaultHeader(). The Accept HTTP request header tells the server that our client wants to receive a JSON content in the response. The Content-Type header tells the server that JSON data is being sent in the request body. Next, add a helper method for adding rows to the specified container. // GridDbCloudClient.java public void registerRows(String containerName, Object body) { ResponseEntity<String> result = restClient .put() .uri("/containers/" + containerName + "/rows") .body(body) .retrieve() .toEntity(String.class); } The registerRows method: insert or update multiple rows of data in a specific GridDB container through the Web API. It takes the container’s name and the rows to be registered as parameters. .body(body) we provide the Java object that will be automatically converted to JSON by Spring’s message converter. Next, we need to create a method to execute an SQL statement that combines rows from one or multiple tables. For example, search job postings by skill, need to join the table JobPost with Skill. The GridDB Web API endpoint executes one or more SQL SELECT statements on a specific database: URL: /:cluster/dbs/:database/sql/dml/query HTTP Method: Post Example request body: [ {"stmt" : "select * from container1"}, {"stmt" : "select * from myTable"} ] Here is the helper method: public SQLSelectResponse[] select(List<GridDbCloudSQLStmt> sqlStmts) { try { ResponseEntity<SQLSelectResponse[]> responseEntity = restClient .post() .uri("/sql/dml/query") .body(sqlStmts) .retrieve() .toEntity(SQLSelectResponse[].class); return responseEntity.getBody(); } catch (Exception e) { throw new GridDbException("Failed to execute /sql/dml/query",HttpStatusCode.valueOf(500),e.getMessage(),e); } } Core Data Model In a job board platform, the schema would include tables like Company, JobPost, JobPostSkill, SkillTag, and Users. The schema would facilitate efficient storage and retrieval of job postings, company information, job skills tags, and user roles. User has 3 roles: RECRUITER, ADMIN, and APPLICANT. Job post types are: FULL_TIME(“Full Time”), PART_TIME(“Part Time”), CONTRACT(“Contract”), INTERNSHIP(“Internship”) Work models are: ONSITE, HYBRID, and REMOTE. Each job post can have multiple skills. This database design should support the process of creating and searching jobs in general. We will build our application based on this design. Let’s start with our primary data in a job board. Job Post The job_post table is the most important data model, representing a single job listing. We need to create a class to centralize the database operations from creating tables, querying rows, and creating or updating rows. Here is our container class: service/JobPostContainer.java @Component public class JobPostContainer { private final Logger log = LoggerFactory.getLogger(getClass()); private final GridDbCloudClient gridDbCloudClient; private static final String TBL_NAME = "JBJobPost"; public JobPostContainer(GridDbCloudClient gridDbCloudClient) { this.gridDbCloudClient = gridDbCloudClient; } public void createTable() { List<GridDbColumn> columns = List.of( new GridDbColumn("id", "STRING", Set.of("TREE")), new GridDbColumn("title", "STRING"), new GridDbColumn("description", "STRING"), new GridDbColumn("jobType", "STRING", Set.of("TREE")), new GridDbColumn("maximumMonthlySalary", "DOUBLE"), new GridDbColumn("datePosted", "TIMESTAMP"), new GridDbColumn("companyId", "STRING", Set.of("TREE")), new GridDbColumn("workModel", "STRING", Set.of("TREE")), new GridDbColumn("location", "STRING"), new GridDbColumn("applyUrl", "STRING")); GridDbContainerDefinition containerDefinition = GridDbContainerDefinition.build(TBL_NAME, columns); this.gridDbCloudClient.createContainer(containerDefinition); } } Here, the GridDbCloudClient is being injected into JobPostContainer via the constructor. By using constructor injection, we get some advantages: preventing circular dependencies at compile time and easier to unit test by simply passing mock or stub implementations of dependencies directly to the constructor during testing. public void saveRecords(List<JobPostRecord> jobPostRecords) { StringBuilder sb = new StringBuilder(); sb.append("["); for (int i = 0; i < jobPostRecords.size(); i++) { JobPostRecord record = jobPostRecords.get(i); sb.append("["); sb.append("\"").append(record.id()).append("\""); sb.append(", "); sb.append("\"").append(StringEscapeUtils.escapeJson(record.title())).append("\""); sb.append(", "); sb.append("\"").append(StringEscapeUtils.escapeJson(record.description())).append("\""); sb.append(", "); sb.append("\"").append(record.jobType().name()).append("\""); sb.append(", "); sb.append(record.maximumMonthlySalary()); sb.append(", "); sb.append("\"") .append(DateTimeUtil.formatToZoneDateTimeString(record.datePosted())) .append("\""); sb.append(", "); sb.append("\"").append(record.companyId()).append("\""); sb.append(", "); sb.append("\"").append(record.workModel().name()).append("\""); sb.append(", "); if (record.location() != null) { sb.append("\"") .append(StringEscapeUtils.escapeJson(record.location())) .append("\""); } else { sb.append("null"); } sb.append(", "); if (record.applyUrl() != null) { sb.append("\"").append(record.applyUrl()).append("\""); } else { sb.append("null"); } sb.append("]"); if (i < jobPostRecords.size() – 1) { sb.append(", "); } } sb.append("]"); String result = sb.toString(); this.gridDbCloudClient.registerRows(TBL_NAME, result); } saveRecords(List jobPostRecords): converts a list of JobPostRecord objects into a JSON-formatted string array and saves it to the GridDB instance using GridDbCloudClient. For datePosted, we should convert it into a string as UTC time format like YYYY-MM-DDThh:mm:ss.SSSZ. We escape the character in a String to prevent JSON parsing errors. public List<JobPostRecord> getAll() { AcquireRowsRequest requestBody = AcquireRowsRequest.builder().limit(50L).sort("id ASC").build(); AcquireRowsResponse response = this.gridDbCloudClient.acquireRows(TBL_NAME, requestBody); if (response == null || response.getRows() == null) { log.error("Failed to acquire rows from GridDB"); return List.of(); } List<JobPostRecord> jobPosts = convertResponseToRecord(response.getRows()); return jobPosts; } public List<JobPostRecord> searchBySkill(String skill) { String stmt = """ SELECT jp.* \ FROM JBJobPost jp \ JOIN JBCompany c ON jp.companyId = c.id \ JOIN JBJobPostSkill jps ON jp.id = jps.jobPostId \ JOIN JBSkillTag st ON jps.skillTagId = st.id \ WHERE LOWER(st.name) IN ('%s') \ GROUP BY jp.id, c.name """.formatted(skill.toLowerCase()); List<GridDbCloudSQLStmt> statementList = List.of(new GridDbCloudSQLStmt(stmt)); SQLSelectResponse[] response = this.gridDbCloudClient.select(statementList); if (response == null || response.length != statementList.size()) { // log.error("ERROR"); return List.of(); } List<List<Object>> results = response[0].getResults(); if (results.isEmpty()) { log.info("No result for searching skill: {}", skill); return List.of(); } List<JobPostRecord> records = convertResponseToRecord(results); return records; } getAll(): retrieves all job post records from a GridDB database, converts them into JobPostRecord objects, and returns them as a List. searchBySkill(String skill): find job posts that require a specific skill. We create a SQL query using Java’s text block. The SQL query selects all columns from the JobPost table, joins with the Company, JobPostSkill, and SkillTag tables, then filters by skill name. Then wraps the SQL statement in a GridDbCloudSQLStmt object and sends it to the GridDB Cloud using the select method of the client. Service Layer Next, we’ll add the service layer that sits between the Web Controller and the Data Access layer. @Service public class JobPostGridDbService { private final JobPostContainer jobPostContainer; public JobPostGridDbService(JobPostContainer jobPostContainer) { this.jobPostContainer = jobPostContainer; } public static String nextId() { return TsidCreator.getTsid().format("job_%s"); } public List<JobPostDTO> findAll(String searchSkill) { final List<JobPostRecord> jobPosts; if (searchSkill != null && !searchSkill.isBlank()) { jobPosts = jobPostContainer.searchBySkill(searchSkill); } else { jobPosts = jobPostContainer.getAll(); } return jobPosts.stream() .map(jobPost -> mapToDTO(jobPost, new JobPostDTO())) .collect(Collectors.toList()); } public String create(final JobPostDTO jobPostDTO) { String id = (jobPostDTO.getId() != null) ? jobPostDTO.getId() : nextId(); JobPostRecord newJobPost = new JobPostRecord( id, jobPostDTO.getTitle(), jobPostDTO.getDescription(), jobPostDTO.getJobType(), jobPostDTO.getMaximumMonthlySalary(), jobPostDTO.getDatePosted(), jobPostDTO.getCompanyId(), jobPostDTO.getWorkModel(), jobPostDTO.getLocation(), jobPostDTO.getApplyUrl()); jobPostContainer.saveRecords(List.of(newJobPost)); return id; } } This service class hides the database operation After getting the query result, transform it into a DTO class. @Service public class JobPostSkillGridDbService { private final JobPostSkillContainer jobPostSkillContainer; public JobPostSkillGridDbService(JobPostSkillContainer jobPostSkillContainer) { this.jobPostSkillContainer = jobPostSkillContainer; } public void replaceSkillsForJobPost(String jobPostId, List<String> skillTagIds) { deleteByJobPostId(jobPostId); if (!skillTagIds.isEmpty()) { createSkillsForJobPost(jobPostId, skillTagIds); } } } replaceSkillsForJobPost: update the list of skills for a job. It first removes all skill associations for the current job, then creates new associations between the job post and each skill tag ID in the list. Web Controller Next, let’s add the web controller class. This layer is the entry point of our web application. It receives requests, coordinates with the service layer to fulfill the data requested, and ensures users get the responses they expect. We will try to keep the controller thin and focus on its core responsibilities. controller/JobPostController.java @Controller @RequestMapping("/jobs") public class JobPostController { private final Logger log = LoggerFactory.getLogger(getClass()); private final JobPostGridDbService jobPostService; private final CompanyGridDbService companyService; private final JobPostSkillGridDbService jobPostSkillService; private final SkillTagGridDbService skillTagService; private final ChatModel chatModel; private final TableSeeder tableSeeder; private final Map<String, String> jobTypeValues = Arrays.stream(JobPostType.values()) .collect( java.util.stream.Collectors.toMap( JobPostType::name, JobPostType::getLabel)); public JobPostController( final JobPostGridDbService jobPostService, final CompanyGridDbService companyService, final JobPostSkillGridDbService jobPostSkillService, final SkillTagGridDbService skillTagService, ChatModel chatModel, TableSeeder tableSeeder) { this.jobPostService = jobPostService; this.companyService = companyService; this.jobPostSkillService = jobPostSkillService; this.skillTagService = skillTagService; this.chatModel = chatModel; this.tableSeeder = tableSeeder; } @ModelAttribute public void prepareContext(final Model model) { Map<String, String> companies = companyService.findAll().stream() .collect( java.util.stream.Collectors.toMap( com -> com.getId(), com -> com.getName())); model.addAttribute("jobTypeValues", jobTypeValues); model.addAttribute("workModelValues", WorkModel.values()); model.addAttribute("companyIdValues", companies); } @GetMapping public String list( @RequestParam(name = "searchSkill", required = false) String searchSkill, final Model model) { List<JobPostDTO> jobs = jobPostService.findAll(searchSkill); List<JobListingResponse> jobPosts = jobs.stream() .map( jobPost -> { JobListingResponse response = buildJobPostResponse(jobPost.getId()); return response; }) .toList(); model.addAttribute("jobPosts", jobPosts); model.addAttribute("searchSkill", searchSkill); return "jobs/list"; } } All dependencies (service, component) are injected using constructor injection. Annotated with @ModelAttribute the prepareContext(final Model model) will be executed before every controller method. It populates common attributes (job types, work models, companies), making it available to all Thymeleaf templates, useful for building dropdowns. Frontend using Thymeleaf Thymeleaf provides a flexible approach to render dynamic web pages in Spring Boot applications. We use fragments to create reusable template components and structure the templates in logical directories. $ src/ $ └── main/ $ └── resources/ $ ├── templates/ $ │ ├── layout.html $ │ └── authentication/ $ │ └── company/ $ │ └── home/ $ │ └── jobs/ $ │ └── fragments/ $ │ └── forms.html $ └── static/ $ └── css/ Job listing page <!DOCTYPE HTML> <html xmlns:th="http://www.thymeleaf.org" xmlns:layout="http://www.ultraq.net.nz/thymeleaf/layout" xmlns:sec="http://www.thymeleaf.org/extras/spring-security" layout:decorate="~{layout}"> <head> <title>[[#{jobPost.list.headline}]]</title> <style type="text/css"> </style> </head> <body> <div layout:fragment="content"> <!– Page Header –> <div class="page-header row mb-4"> <div class="col-md-8"> <h1 class="fw-bold">Find Your Dream Job</h1> <p class="fs-3">Browse through our latest job openings </p> </div> <div sec:authorize="hasRole('ADMIN')" class="col-md-4 text-md-end action-buttons mt-3 mt-md-0"> <a sec:authorize="hasRole('ADMIN')" th:href="@{/jobs/add}" class="btn btn-create btn-lg text-white me-2"><i class="bi bi-plus-circle me-1"></i> [[#{jobPost.list.createNew}]]</a> </div> </div> <div class="row"> <!– Filters Sidebar –> <div class="col-lg-3"> <form th:action="@{/jobs}" method="get"> <div class="filter-card card p-3 mb-4"> <div class="input-group"> <span class="input-group-text bg-transparent border-0"> <i class="bi bi-search"></i> </span> <input type="text" name="searchSkill" th:value="${searchSkill}" class="form-control border-0 bg-transparent" placeholder="Skill…"> <button class="btn btn-primary">Search</button> </div> </div> </form> </div> <!– Job Listings –> <div class="col-lg-9"> <div class="row row-cols-1 row-cols-md-2 g-4"> <div th:each="jobPost : ${jobPosts}" class="col"> <div class="card job-card h-100"> <div class="card-body"> <div class="d-flex justify-content-between align-items-start mb-3"> <div class="company-logo"><img th:src="@{https://ui-avatars.com/api/?name={name}(name=${jobPost.company.name})}" alt="Company Logo" width="32" height="32" class="rounded-circle me-2"></div> </div> <h5 class="card-title"> <a th:text="${jobPost.title}" th:href="@{/jobs/view/{id}(id=${jobPost.id})}" class="job-title-link">Developer</a> </h5> <p class="card-text mb-2"> <a href="#" class="text-decoration-none"><span th:text="${jobPost.company.name}">jobType</span></a> </p> <div class="mb-3"> <span th:text="${jobPost.jobType}" class="job-tag job-type">jobType</span> <!– <span class="job-tag salary">$7,000 – $9,000</span> –> <span th:text="${jobPost.workModel}" class="job-tag work-mode">Hybrid</span> </div> <p class="card-text text-muted small"> <i th:text="${jobPost.location}" class="bi bi-geo-alt me-1"> </i> </p> <p th:text="${#strings.abbreviate(jobPost.description, 150)}" class="card-text"></p> <div class="d-flex justify-content-between align-items-center action-buttons"> <span class="text-muted small"></span> <a sec:authorize="!hasRole('ADMIN')" th:href="@{/jobs/view/{id}(id=${jobPost.id})}" class="btn btn-lg btn-primary">View Details</a> <a sec:authorize="hasRole('ADMIN')" th:href="@{/jobs/edit/{id}(id=${jobPost.id})}" class="btn btn-lg btn-primary"><i class="bi bi-pencil-square"></i> Edit</a> </div> </div> </div> </div> </div> </div> </div> <script src="https://cdnjs.cloudflare.com/ajax/libs/jquery/3.7.1/jquery.min.js"></script> </div> </body> </html> The Create New Job button is only available for ADMIN. We provide a search form to let users filter jobs by skill. We use th:each attribute to iterate over a list of jobs. Each job post is shown as a card. The job description was abbreviated to 150 characters. Edit button only for ADMIN. The title is a clickable link to the job details. For the styling we uses Bootstrap 5 and custom CSS. Here is what it looks like as an admin: Spring AI Integration Next, we introduce an intelligent feature that automates the process of adding relevant skills to a job post. We will leverage Spring AI, a powerful library that simplifies communication between our Spring Boot application and advanced AI models from providers like OpenAI. The process is straightforward: when an admin is creating or editing a job post, they can click a “Generate Skills” button. Behind the scenes, our application prepares relevant data before sending it to the OpenAI model and consumes the output. The most important part, we want to turn the AI-generated response into structured data like a Java record. private List<SkillTagDTO> generateSkills(JobPostDTO jobPostDTO, List<SkillTagDTO> skillTags) throws JsonProcessingException, JsonMappingException { ObjectMapper objectMapper = new ObjectMapper(); String skillCatalogJson = objectMapper.writeValueAsString(skillTags); BeanOutputConverter<SkillResponse> outputConverter = new BeanOutputConverter<>(new ParameterizedTypeReference<SkillResponse>() {}); String format = outputConverter.getFormat(); // @formatter:off String promptStr = """ You are an AI assistant that extracts required skills from a job description. TASK: – Only return skills present in the provided JSON skill catalog. – Matching is case-insensitive. – Do not invent or include skills not in the catalog. – Output strictly as a JSON array of objects. NOW PROCESS: <JOB_DESCRIPTION> {jobDescription} </JOB_DESCRIPTION> <SKILL_LIST> {skillCatalog} </SKILL_LIST> {format} """; // @formatter:on Prompt prompt = PromptTemplate.builder() .template(promptStr) .build() .create( Map.of( "jobDescription",jobPostDTO.getDescription(), "skillCatalog",skillCatalogJson, "format",format), OpenAiChatOptions.builder() .responseFormat(new ResponseFormat(ResponseFormat.Type.JSON_OBJECT, null)) .build()); var generation = this.chatModel.call(prompt).getResult(); String outputText = generation.getOutput().getText(); SkillResponse skillResponse = outputConverter.convert(outputText); return skillResponse.skills(); } record SkillResponse(List<SkillTagDTO> skills) {} We use the low-level ChatModel API directly. Use Jackson’s ObjectMapper to convert the list of SkillTagDTO objects into JSON string. We want the AI Model to give us skills that only present in our provided skill catalog. BeanOutputConverter: to generate a JSON schema based on a given Java class, which is then used to transform the LLM output into our desired type SkillResponse record. We build the prompt using a template and inject the job description, skill catalog (as JSON), and the output format. We configure the OpenAI Chat API to respond with a JSON object through OpenAiChatOptions. Send the prompt to the OpenAI chat model using its call method. Gets the AI’s output text, use outputConverter to parse the JSON response into SkillResponse object. Return the list of extracted skills. Demo showing generate skills from job description using Spring AI and OpenAI. Running the Project: End-to-End Execution $ export OPENAI_API_KEY=your_key Build the project and run the application in development mode. $ mvn clean package $ mvn spring-boot:run Open localhost. Conclusion In this tutorial, we’ve successfully built a fully functional job board web application that demonstrate the power of modern Java development. We’ve gained hands-on experience integrating Spring Boot, Thymeleaf, and GridDB Cloud to create a complete full-stack solution from the ground up. One of the most exciting aspects of our implementation was integrating Spring AI’s support for OpenAI’s Structured Outputs. This feature transforms how web handle AI-generated content by ensuring predictable, well-formatted responses. While this application provides a solid foundation for any job board platform, there are numerous features we can consider adding: A complete user authentication and registration. Allowing recruiters to register and post jobs under their own account. Introduce pagination to display jobs. Tracing the request and response of the LLM call into the observability platform. Add cache in generating skills. If the job description hasn’t changed, then we should not call the OpenAI

GridDB Cloud vs. InfluxDB Cloud vs. MongoDB Atlas: A Cloud Time Series Benchmark
More
Choosing a managed time series database for your IoT or DevOps workload usually comes down to one nervous question: am I paying for performance, or just paying? So we put three of the most popular options head-to-head: GridDB Cloud, InfluxDB Cloud, and MongoDB Atlas, using the standardized Time Series Benchmark Suite (TSBS). Same workload, same methodology, real ingestion and query numbers. Below are some of the more interesting findings. 1. At the pay-as-you-go tier, GridDB Cloud and InfluxDB Cloud cost exactly the same. Identical rate cards, so performance becomes the only tiebreaker. GridDB delivered 4–5× higher query throughput at 4–5× lower latency. 2. InfluxDB choked on large batches. A 100,000-row batch threw 429 Too Many Requests errors instantly. GridDB sailed through the same load at roughly 44,000 rows/sec. 3. MongoDB Atlas M40 costs $407/month more than GridDB’s fixed plan — and lost every benchmark. On threshold-scan queries at 64 workers, GridDB ran about 10× faster. 4. GridDB scaled. The others hit a wall. InfluxDB capped out near 11.5 queries/sec; MongoDB plateaued at 32 workers. GridDB kept climbing past 64. Putting it all together, we can confidently say that there’s a GridDB Cloud pricing model that beats the competition whether your workload is bursty and variable or heavy and continuous. The full methodology, ingestion and query tables, architecture diagrams, and the per-query breakdowns behind every number above can be found in the whitepaper. Take a look now! Download the full white paper (PDF)

Connecting to GridDB Cloud v3.2 from Your Local Dev Environment (No VPN, No VNet Peering)
More
With the release of GridDB Cloud v3.2, we now get the ability to connect to GridDB Cloud from your local machine using the native NoSQL clients (Java, Python, etc.) — without having to spin up a VNet peering, without configuring a VPN, and without needing to use the Web API. If you’ve followed along with our previous blogs covering the Azure Marketplace signup, the VNet peering setup, or the various Azure Connected Services integrations, you know that getting the native API working from outside the cloud used to be a bit tricky. You either had to host your code inside an Azure VNet peered to GridDB Cloud, set up a VPN to tunnel in, or resign yourself to the Web API. For local dev iteration, none of those options were super easy. With v3.2, that changes. You can now point your local Python or Java client directly at your cloud instance over the public internet, authenticate, and run queries. You can follow the official quick start guide but I will summarize and give some helpful tips that worked for me. GridDB Cloud v3.2 is available via the Azure Marketplace. If you haven’t signed up yet, grab either the Pay-As-You-Go plan or the Fixed Monthly plan. Our Azure Marketplace signup blog walks through the whole process. The Checklist Here’s the short version of what you need to do, in order. I’ll go deeper on each step below. First, we need to prepare our environment. Preparation Generate your notification provider URL from the Cloud dashboard before whitelisting Whitelist your local machine’s IP in the GridDB access area Download the EE-only library jars from the Cloud help page (they’re not on Maven) Extract gridstore-advanced.jar from the RPM if you’re not on Rocky Linux Install the Python client Add all the jars — including gridstore-advanced — to your CLASSPATH Append connectionRoute=PUBLIC to your connection details That last one is the whole reason this works. Without it, the client tries to connect over the private route and will timeout. 1. Generate the Notification Provider URL (Do This First!) Before you do anything else in the Cloud dashboard, head to the cluster settings and manually generate the notification provider URL. If you whitelist your IP first, it will fail with a strange warning. Save that URL somewhere — you’ll need it for your connection string. 2. Whitelist Your IP Now go to the access control area of the Cloud dashboard and add your local machine’s public IP to the whitelist. If you click ‘Add my IP’, it will automatically add your curren’t machine’s public IP Address. 3. Download the EE Library Files Head into cloud dashboard’s help/downloads/support section and grab the Enterprise Edition library bundle labeled as: GridDB Cloud Library and Plugin download . These jars are not available on Maven Central or anywhere else — they ship exclusively with the EE build of GridDB, which is what the Cloud runs on. You need these to be able to make SSL connections to the cloud. 4. Extract gridstore-advanced.jar from the RPM The EE download is distributed as an RPM. If you’re running Rocky Linux (or any RHEL-compatible distro), you can install it normally. But if you’re on Ubuntu, Debian, or pretty much anything else, you need to manually crack the RPM open to pull the jar out: $ rpm2cpio griddb-ee-java-lib-5.9.0-linux.x86_64.rpm | cpio -idmv This drops the contents into your current directory. The jar you want is gridstore-advanced.jar — it lives inside usr/share/java/ or similar after extraction. Without this jar on your classpath, your SSL handshake to the cloud will fail. 5. Install the Python Client Standard Python client install — nothing new here. Follow the official Python client getting started guide for the full walkthrough (install Java, clone the python_client repo, mvn install, then pip install .). 6. Add Everything to CLASSPATH Once you have all your jars in one place (gridstore.jar, gridstore-jdbc.jar, gridstore-arrow.jar, arrow-memory-netty.jar, and critically gridstore-advanced.jar), export your CLASSPATH: $ export CLASSPATH=/path/to/lib/gridstore.jar:/path/to/lib/gridstore-jdbc.jar:/path/to/lib/gridstore-arrow.jar:/path/to/lib/arrow-memory-netty.jar:/path/to/lib/gridstore-advanced.jar If gridstore-advanced.jar isn’t on this path, the connection will fail. 7. Add connectionRoute=PUBLIC This is the magic parameter that tells the client to use the new public route introduced in v3.2. In your Python code, your factory config should include it: self.gridstore = None try: self.gridstore = GridDB.factory.get_store( notification_provider=self.notification_provider, cluster_name=self.cluster_name, username=self.username, password=self.password, database=self.database, connection_route='PUBLIC' #NOTE, PUBLIC must be in ALL CAPS ) print(f"Successfully connected to {self.cluster_name}.") except Exception as e: print(f"Failed to connect to GridDB: {e}") Without this, the client will try to use the internal route and you’ll be stuck waiting. Python Example With all the pieces in place, here’s what a basic connect-and-query looks like from your local machine: $ (venv) israel@griddb:~/development/griddb-university/python$ export CLASSPATH=$CLASSPATH:./gridstore.jar:./gridstore-arrow.jar:./arrow-memory-netty.jar:./gridstore-advanced.jar $ (venv) israel@griddb:~/development/griddb-university/python$ export GRIDDB_NOTIFICATION_PROVIDER="URL" $ export GRIDDB_CLUSTER_NAME="gs_clustermfcloud87" $ export GRIDDB_USERNAME="admin" $ export GRIDDB_PASSWORD="password" $ export GRIDDB_DATABASE="nSt" $ (venv) israel@griddb:~/development/griddb-university/python$ python3 main.py $ JVM already started. $ Attempting to connect to GridDB… $ Successfully connected to gs_clustermfcloud8737. $ Successfully created TimeSeries: SamplePython_timeseries1 $ Successfully put row into SamplePython_timeseries1: [datetime.datetime(2025, 10, 1, 15, 0, tzinfo=datetime.timezone.utc), 10.21] $ — Reading from SamplePython_timeseries1 — $ [datetime.datetime(2025, 10, 1, 15, 0), 10.21] That’s it. No Azure Function wrapping, no container, no VPN client running in the background; just your script, talking directly to GridDB Cloud. The full sample python source code along with Java sample code is included with this article. Java from Your Local Machine As java is the native interface for GridDB, let’s also take a look at connecting via Java. The steps are largely the same, including the adding the new connectionRoute property and having the special library for making SSL requests to GridDB Cloud. Gotcha #1: URL-encode the Notification Provider Value When you pass the notification provider URL into Java’s GridStoreFactory, you need to URL-encode the value. If you don’t, Java’s property parser will see the &connectionRoute=PUBLIC portion as a separate parameter and silently drop it — and you’ll be left wondering why your connection is timing out even though everything looks right. The fix is to encode the full URL before passing it in: String notificationProvider = URLEncoder.encode( "https://<your-provider-url>?clusterName=<name>&connectionRoute=PUBLIC", StandardCharsets.UTF_8.toString() ); Gotcha #2: Manually Install gridstore-advanced.jar to Your Local Maven Repo Same jar as before, same reason — not on Maven Central. To use it with Maven, you have to install it to your local .m2 repository manually: $ mvn install:install-file \ $ -Dfile=/path/to/your/python/gridstore-advanced.jar \ $ -DgroupId=com.github.griddb \ $ -DartifactId=gridstore-advanced \ $ -Dversion=5.9.0 \ $ -Dpackaging=jar Then add it as a dependency in your pom.xml: <dependency> <groupId>com.github.griddb</groupId> <artifactId>gridstore-advanced</artifactId> <version>5.9.0</version> </dependency> Now Maven will resolve it like any other dependency when you build your project. Java Example $ (venv) israel@griddb:~/development/griddb-university/java$ java -jar target/java-samples-1.0-SNAPSHOT-jar-with-dependencies.jar $ jdbc:gs:///gs_clustermfcloud8737/nl7QftSt?notificationProvider=https%3A%2F%2Fdbaasshare&connectionRoute=PUBLIC $ CREATE TABLE IF NOT EXISTS exampleJdbc (id integer, value string); $ INSERT INTO exampleJdbc values (0, 'test0'),(1, 'test1'),(2, 'test2'),(3, 'test3'),(4, 'test4') $ SELECT * FROM exampleJdbc $ id value 0 test0 1 test1 2 test2 3 test3 4 test4 0 test0 1 test1 2 test2 3 test3 4 test4 $ Running SQL: SELECT ts, AVG(temp) as avg_temp FROM device WHERE ts BETWEEN TIMESTAMP('2020-07-12T00:01:20Z') AND TIMESTAMP('2020-07-12T00:14:00Z') GROUP BY RANGE (ts) EVERY(20, SECOND) $ java.sql.SQLException: [280005:SQL_DDL_TABLE_NOT_EXISTS] Parse SQL failed, reason = GET TABLE failed. (reason=GET TABLE failed. (reason=Specified table 'device' is not found)) on executing query (sql="SELECT ts, AVG(temp) as avg_temp FROM device WHERE ts BETWEEN TIMESTAMP('2020-07-12T00:01:20Z') AND TIMESTAMP('2020-07-12T00:14:00Z') GROUP BY RANGE (ts) EVERY(20, SECOND) ") (db='nl7QftSt') (user='S01K7vrCuF-israel') (clientId='c761d357-ec46-4e5c-8f80-405e69635810:4') (source={clientId=155, address=172.22.5.69:46422}) (connection=PUBLIC) (address=20.205.145.126:20001, partitionId=8289) $ Testing GridDB NoSQL $ Creating Container And again, the sample code will be shared here. In this case, we are connecting to GridDB Cloud via the NoSQL interface AND the SQL interface through JDBC. Both work here once the above steps are adhered to. C Client Please note, that if you would like to use the C Client, you will also need to follow the same procedure as the Java code but for the C Client. That is, you will need to include the ‘public route’ to your connection details and will need to extract the .rpm called griddb-ee-c-lib-5.8.0-linux.x86_64.rpm (assuming you are not using CentOS/Rocky Linux) and grab the library files libgridstore.so.0.0.0 and libgridstore_advanced.so.0.0.0 and the header (gridstore.h). Once you have those in place, add the public route to your connection details const GSPropertyEntry props[] = { { "notificationProvider", "https://<url-encoded-provider-url>" }, { "clusterName", "<your cluster name>" }, { "database", "public" }, { "user", "<user>" }, { "password", "<password>" }, { "sslMode", "PREFERRED" }, { "connectionRoute", "PUBLIC" } }; And you should be good to go for the C Client as well! Conclusion Being able to hit GridDB Cloud directly from your local dev machine is a genuinely big deal for iteration speed. If you haven’t signed up for GridDB Cloud v3.2 yet, it’s exclusively on the Azure Marketplace — you can grab the Pay-As-You-Go plan

Create Dynamic Ambient Music Using AI and IoT Data
More
This tutorial shows how to generate evolving ambient music driven by IoT sensor data. We’ll ingest sensor readings into GridDB database, map those readings to musical parameters using OpenAI, and call ElevenLabs Music to render an audio track. The UI is built with React + Vite, and the backend is Node.js. Introduction Ambient music thrives on context. Here, the environment literally composes the score. Heat can slow the tempo, humidity can soften the timbre, and human presence can thicken the arrangement. We’ll stitch together a small system: devices post telemetry (we will use the data directly), GridDB keeps the data, the AI model creates music parameters, and ElevenLabs will render audio that you can play instantly in the browser. System Architecture The system has several core components working together to turn IoT data into ambient sound: IoT Data Source Environmental sensors capture values such as temperature, humidity, sound levels, and occupancy. These readings are the raw input for the music generation process. Node.js Backend Node.js acts as the central orchestrator. It receives IoT sensor readings and coordinates interactions between the AI models, the music generator, and the database. OpenAI Model The IoT data is processed by an OpenAI model. The model transforms the data into a musical prompt. For example, “calm ambient soundscape with airy textures and slow tempo.” This ensures the music reflects the current environment in a more human-like, descriptive way. ElevenLabs Music API The generated music prompt is sent to the ElevenLabs Music API. ElevenLabs then produces an audio track that matches the description. The result is ambient audio that adapts to real-world conditions. GridDB Database Both the music prompt and the audio metadata (such as file path or data URL) are stored in GridDB. GridDB also keeps the original IoT readings. React + Vite Frontend The frontend provides a web-based interface where users can trigger new music generation, view sensor snapshots, and play the most recent ambient tracks. Prerequisites Node.js This project is built using React + Vite, which requires Node.js version 16 or higher. You can download and install Node.js from https://nodejs.org/en. OpenAI Create the OpenAI API key here. You may need to create a project and enable a few models. In this project, we will use an AI model from OpenAI: gpt-5-mini to create an audio prompt. GridDB Sign Up for GridDB Cloud Free Plan If you would like to sign up for a GridDB Cloud Free instance, you can do so at the following link: https://form.ict-toshiba.jp/download_form_griddb_cloud_freeplan_e. After successfully signing up, you will receive a free instance along with the necessary details to access the GridDB Cloud Management GUI, including the GridDB Cloud Portal URL, Contract ID, Login, and Password. GridDB WebAPI URL Go to the GridDB Cloud Portal and copy the WebAPI URL from the Clusters section. It should look like this: GridDB Username and Password Go to the GridDB Users section of the GridDB Cloud portal and create or copy the username for GRIDDB_USERNAME. The password is set when the user is created for the first time. Use this as the GRIDDB_PASSWORD. For more details, to get started with GridDB Cloud, please follow this quick start guide. IP Whitelist When running this project, please ensure that the IP address where the project is running is whitelisted. Failure to do so will result in a 403 status code or forbidden access. You can use a website like What Is My IP Address to find your public IP address. To whitelist the IP, go to the GridDB Cloud Admin and navigate to the Network Access menu. ElevenLabs You need an ElevenLabs account and API key to use this project. You can sign up for an account at https://elevenlabs.io/signup. After signing up, go to the Developer section, and create and copy your API key. And make sure to enable the Music Generation access permission. How to Run 1. Clone the repository Clone the repository from https://github.com/junwatu/grid-sound-ambient to your local machine. $ git clone https://github.com/junwatu/grid-sound-ambient.git $ cd grid-sound-ambient $ cd apps 2. Install dependencies Install all project dependencies using npm. $ npm install 3. Set up environment variables Copy file .env.example to .env and fill in the values: # Copy this file to .env.local and add your actual API keys # Never commit .env.local to version control # ElevenLabs API Key for ElevenLabs Music ELEVENLABS_API_KEY= OPENAI_API_KEY= GRIDDB_WEBAPI_URL= GRIDDB_PASSWORD= GRIDDB_USERNAME= WEB_URL=http://localhost:3000 Please look at the section on Prerequisites before running the project. 4. Run the project Run the project using the following command: $ npm run start 5. Open the application Open the application in your browser at http://localhost:3000 or any address that WEB_URL is set to. You also need to allow the browser to access your microphone. Building The Ambient Music Generator IoT Data In this project, we will use pre-made IoT data. The data is an array of sensor snapshots. Each object is a single time-stamped reading for a building zone. This data mimics real data conditions from the IoT sensor. [ { "timestamp": "2025-08-20T09:15:00", "zone": "Meeting Room A", "temperature_c": 22.8, "humidity_pct": 47, "co2_ppm": 1020, "voc_index": 185, "occupancy": 7, "noise_dba": 49, "productivity_score": 65, "trend_10min.co2_ppm_delta": 120, "trend_10min.noise_dba_delta": 1, "trend_10min.productivity_delta": -5 }, … ] You can look at the data sample in the apps/data/iot_music_samples.json. User Interface The UI is a small React app (Vite + Tailwind) that drives the end‑to‑end flow and plays generated audio. The workflow for the user is: Click the Load example button to load sensor data into the text input, or you can paste a single sensor snapshot JSON into the textarea from the apps/data/iot_music_samples.json file. Click “Generate Music” to call. The app displays the generated prompt, a brief (expandable) description, and an HTML5 audio player. Optionally, you can open “View History” to fetch recent records and replay saved tracks. These are the server routes used by the client-side UI: | Method & Route | Trigger in UI | Purpose Consumes | |—————————-|—————————————-|———————————————- | POST /api/iot/generate-music | Generate Music button | Full pipeline: brief → prompt → music → save | GET /api/music/history | View History modal | Load saved generations | GET /audio/ | Audio players in results/history | Stream ambient music from server The client data returned from the server is JSON. It contains all the data needed for the UI, from music prompt, music brief, to audio metadata such as audio path and filename. One thing to note here is that the OpenAI model is being used to generate music brief AND the music prompt. What’s the difference? Please, read the next section. Result UI Other than user input for IoT data snapshot, after successfully generating ambient music, the result user interface will render: Generated music prompt (+ Music bried details) Music player, it’s information, and the download link. History UI When the user clicks the View History button, the app changes state to display all generated music, associated metadata, simplified IoT data, music briefs, and prompts. Generate Music Prompt Music Brief This project generates a music brief before the final prompt to provide flexibility and a clear separation of concerns. The brief normalizes noisy IoT data into structured parameters, and the same brief can be reused with other (including non‑OpenAI) models without changing the mapping, making it robust for real‑world conditions. Here is an example of the music brief: { "mood": "soothing", "energy": 48, "tension": 30, "bpm": [ 50, 64 ], "duration_sec": 60, "loopable": true, "key_suggestion": "A minor", "instrument_focus": [ "warm pads", "soft piano", "breathy synth", "warm low strings", "subtle low percussion" ], "texture_notes": "Airy, sparse texture with warm low mids and a gentle high-frequency roll-off to avoid brightness.", "rationale": "CO2 >1000 ppm and rising calls for lower-energy, soothing airiness; occupancy is low and temp/humidity are ideal, so use sparse warm timbres and minimal rhythmic drive to reduce stress." } Music brief generation is handled by generateMusicBrief(sensorSnapshot). It takes a single IoT sensor snapshot and uses the OpenAI model gpt-5-mini to produce the brief. The full code can be found in the lib\openai.ts file. The important part of the code is the AI system prompt: const systemPrompt = ` You are an assistant that converts building sensor snapshots into a concise “music brief” for an ambient soundtrack generator. Return ONLY compact JSON with these fields: { "mood": "calm|focused|energizing|soothing|alert|uplifting|neutral", "energy": 0-100, "tension": 0-100, "bpm": [low, high], "duration_sec": number, "loopable": true|false, "key_suggestion": "A minor|D minor|C major|… (optional)", "instrument_focus": ["pads","soft piano","light percussion", …], "texture_notes": "short sentence on space/density/brightness", "rationale": "1–2 sentences mapping readings→choice" } Decision rules: – High CO2 (>1000 ppm) or high VOC (>200) → lower energy (35–55), soothing/airiness to reduce stress; avoid bright highs. – High occupancy (>25) with good air (CO2 < 800) → moderate energy (55–70) and gentle momentum; keep distractions low (no sharp transients). – High noise (>60 dBA) → simpler textures, fewer rhythmic accents; tighten BPM range. – Productivity_score < 60 → light uplift (energy +10), but stay minimal. – Temperature 22–24°C & humidity 45–55% is ideal; if outside, reduce tension slightly and favor warm timbres. Prefer keys: minor for calming/focus, major for uplifting. Keep outputs steady and minimal; no reactivity to single-sample spikes—assume 10–15 min trend. `; This system prompts the behaviour of the model AI to create a music brief with a pre-defined data structure using decision rules. If you want to enhance this project, this is the crucial part where you can adjust the decision rules to your requirements. Music Prompt The music prompt is generated using the generateMusicPrompt(musicBrief) function. This function will call the OpenAI model gpt-5-mini to generate a music prompt based on the music brief input. const response = await openai.responses.create({ model: "gpt-5-mini", input: [ { role: "developer", content: [{ type: "input_text", text: systemPrompt }] }, { role: "user", content: [{ type: "input_text", text: JSON.stringify(brief, null, 2) }] }, ], text: { format: { type: "text" }, verbosity: "medium" }, reasoning: { effort: "medium", summary: "auto" }, store: false, } as any); What’s important here is the system prompt that is set in the AI model. const systemPrompt = ` You convert an internal JSON "music brief" into a concise prompt for a generative music API. Rules: – Output 3–5 short lines, max ~450 characters total. – No meta commentary, no JSON, no emojis. – Include: mood, energy/tension, BPM range, duration, loopable flag, (optional) key, instruments, texture, goal. – Avoid sharp/bright transients when asked; keep language precise and production-safe. – Never invent values not present in the brief; default only when missing. Example: "Ambient track for a focused open office. Mood: focused, energy 62/100, tension 35/100. Tempo: 84–92 BPM, loopable, ~240s. Key: D minor. Instruments: warm pads, soft piano, light shaker, subtle bass. Texture: low-density, gentle movement, softened highs; avoid sharp transients and bright cymbals. Goal: steady momentum that supports concentration without masking speech." `; Again, you can customize this system prompt to meet any of your custom project requirements before feeding it to music generation. The full source code for music prompt generation is in the libs\openai.ts file. This is an example of the generated music prompt: "Calm. Energy 60/100, tension 25/100.\nTempo: 58–64 BPM, duration ~60s, loopable. Key: A minor.\nInstruments: warm pads, soft electric piano, subtle low bass, minimal brushed percussion.\nTexture: sparse, warm, low‑mid focused with airy pads and subdued transients; avoid sharp/bright transients to prevent masking ambient noise. Goal: gentle uplift and comfort without masking background." Generate Ambient Music After the music brief and music prompt generation, the next step is to generate the ambient music. This workflow handled by the composeMusic() function (full source code in the libs\elevenlabs.ts file): export async function composeMusic({ prompt, music_length_ms = 60000, model_id = "music_v1", apiKey = process.env.ELEVENLABS_API_KEY, }: ComposeParams): Promise<ArrayBuffer> { if (!apiKey) { throw new Error('ElevenLabs API key not configured'); } const response = await fetch("https://api.elevenlabs.io/v1/music", { method: "POST", headers: { "xi-api-key": apiKey, "Content-Type": "application/json", }, body: JSON.stringify({ prompt, music_length_ms, model_id }), }); if (!response.ok) { const errorText = await response.text(); const err: any = new Error(`ElevenLabs API error: ${errorText}`); err.status = response.status; throw err; } return await response.arrayBuffer(); } Basically, the code will call ElevenLabs Music API, which uses the latest music_v1 model. However, in this project, the duration of the generated music is hardcoded to 60 seconds or 1 minute. You can edit this directly in the source code by changing the music_length_ms = 60000 code. The default audio output format from the ElevenLabs Music API is mp3_44100_128. The API also supports several other formats, for a complete list, refer to the official documentation. Database The container type used in this project is collection, and the schema for the data is defined by the interface MusicGenerationRecord code: export interface MusicGenerationRecord { timestamp: string; zone: string; temperature_c: number; humidity_pct: number; co2_ppm: number; voc_index: number; occupancy: number; noise_dba: number; productivity_score: number; trend_10min_co2_ppm_delta: number; trend_10min_noise_dba_delta: number; trend_10min_productivity_delta: number; music_brief: string; music_prompt: string; audio_path: string; audio_filename: string; music_length_ms: number; model_id: string; generation_timestamp: string; } And if you have access to the GridDB cloud dashboard, you will see these columns created based on the interface fields and their type. Save Data The save process will save the IoT data, music briefs, music prompts, audio path, audio filename, and timestamp on every successfull music generation and the function that responsible for this task is the saveMusicGeneration(musicRecord) function, initially it will check if the container music_generations exist or not and if exist than the data will be saved to the database. export async function saveMusicGeneration(record: MusicGenerationRecord): Promise<void> { if (!GRIDDB_CONFIG.griddbWebApiUrl) { console.warn('⚠️ GridDB not configured, skipping database save'); return; } await initGridDB(); try { const client = getGridDBClient(); const containerName = 'music_generations'; console.log(`💾 Saving music generation record for zone: ${record.zone}`); // Generate a unique ID that fits in INTEGER range (max 2,147,483,647) // Use a combination of current time modulo and random number const timeComponent = Date.now() % 1000000; // Last 6 digits of timestamp const randomComponent = Math.floor(Math.random() * 1000); // 3 digit random const id = timeComponent * 1000 + randomComponent; // Prepare the data object for insertion with proper date formatting const data = { id, timestamp: new Date(record.timestamp), zone: record.zone, temperature_c: record.temperature_c, humidity_pct: record.humidity_pct, co2_ppm: record.co2_ppm, voc_index: record.voc_index, occupancy: record.occupancy, noise_dba: record.noise_dba, productivity_score: record.productivity_score, trend_10min_co2_ppm_delta: record.trend_10min_co2_ppm_delta, trend_10min_noise_dba_delta: record.trend_10min_noise_dba_delta, trend_10min_productivity_delta: record.trend_10min_productivity_delta, music_brief: record.music_brief, music_prompt: record.music_prompt, audio_path: record.audio_path, audio_filename: record.audio_filename, music_length_ms: record.music_length_ms, model_id: record.model_id, generation_timestamp: new Date(record.generation_timestamp) }; // Use the fixed insert method that now handles schema-aware transformation await client.insert({ containerName, data: data }); console.log(`✅ Music generation record saved to GridDB (ID: ${id}, Zone: ${record.zone}, File: ${record.audio_filename})`); } catch (error) { console.error('❌ Failed to save music generation record:', error); throw error; } } Read Data To view the history of the music generations, it needs to read data from the database, and this task is internally handled by the getMusicGenerations() function. const client = getGridDBClient(); const containerName = 'music_generations'; console.log(`📊 Retrieving ${limit} music generation records from GridDB`); const results = await client.select({ containerName, orderBy: 'generation_timestamp', order: 'DESC', limit }); The client.select() function is basically a wrapper for SQL SELECT. For the full source code for this function, you can look in the libs\griddb.ts file. Node.js Server All backend functionality is handled by the Node.js server. It exposes a few routes that can be used by the client application or for manual API testing. Server Routes Method Path Purpose GET /api/health Health check with current timestamp POST /api/iot/generate-music Generate music based on the IoT data GET /api/music/history List past generations This server also has a function to save the generated music file into the local public/audio directory. It generates a clean MP3 filename using the generateAudioFilename(zone, timestamp) function and writes the audio buffer to apps/public/audio/. The function then returns the public URL path /audio/. The generated music is served as static files, so any /audio/.mp3 URL is directly accessible over HTTP. You can open these files directly in a browser. Further Enhancements This project is a simple prototype of what we can do using IoT, AI and the GridDB database. In the real scenario, you need to wire the app with real IoT sensor