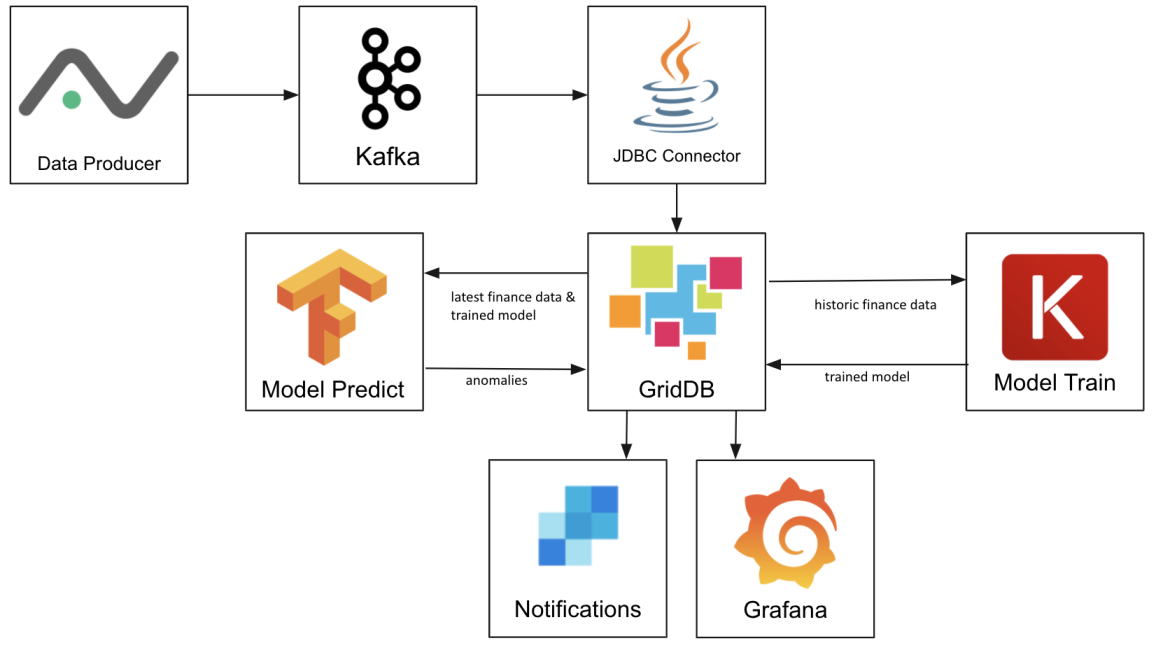
このプロジェクトでは、GridDBを使って機械学習プラットフォームを作成し、そのプラットフォーム上でKafkaを使って、株式市場データプロバイダーであるAlphavantageから株式市場データをインポートします。TensorflowとKerasがモデルを学習し、それをGridDBに格納し、最後にLSTM予測を使って日々の日中の取引履歴から異常を見つけ出します。最後に、データをGrafanaで可視化し、GridDBのREST Trigger機能を使ってTwilioのSendgridに通知を送るように設定します。
このプロジェクトの実際の機械学習部分は、Towards Data ScienceとCuriouslyの記事にインスパイアされたものです。このモデルとデータフローは、予知保全や機械の故障予測など、他の多くのデータセットにも適用できますし、時系列データの異常を見つけたい場合にも適しています。機械学習における異常とは、予測された値が実際の値と大きく異なることです。株価の異常であれば、良い取引の機会があることを意味するかもしれませんし、エンジンのセンサーデータの異常であれば、故障が差し迫っていることを意味するかもしれません。
以下のようなGridDBの機能を紹介します。Key-Containerデータモデル、kafka-connect-jdbc & JDBC、Pandasデータフレーム、Grafanaコネクタ 、Triggers
わずか数銘柄の何十万行ものデータを毎日株式市場終了後に読み込むには、書き込み性能が高いGridDBが必要です。GridDBのキーコンテナ・アーキテクチャは、個々の銘柄に対するクエリが効率的であることを意味し、AAPL銘柄の価格異常を見つけるためにGOOGの日中のデータをスキャンする必要はありません。まだGridDBをセットアップしていない場合は、こちらのマニュアルに従って、まずGridDBをインストールしてください。
Kafka
Kafkaは、さまざまなインプットとアウトプットに対応するデータストリーミングプラットフォームで、簡単に作成することができます。Kafkaはこちらのダウンロードページからダウンロードできます。私たちはバージョン2.12-2.5.0を使用しています。また、お使いのシステムにJava 1.8の開発環境がインストールされている必要があります。ダウンロード後に、ZookeeperとKafkaサーバーを解凍して起動してください。
$ tar xzvf kafka_2.12-2.5.0.tgz
$ cd kafka_2.12-2.5.0
$ export PATH=$PATH:/path/to/kafka_2.12-2.5.0/bin
$ zookeeper-server-start.sh --daemon config/zookeeper.properties
$ kafka-server-start.sh --daemon config/server.properties
KafkaがさまざまなJDBCデータベースに書き込めるようにするためのコネクタであるKafka Connect JDBCを使用します。このコネクタにはすでにGridDBのサポートが追加されていますが、これは私たちのGithubリポジトリからのみ入手することができます。JARをダウンロードしてください。
他にも、GridDB.netのGithubリポジトリにあるgridstore-jdbc.jarも使用する必要します。これは、Kafka Connect JDBCコネクタが必要とする追加のJDBC機能を実装したものです。
両方のJARをダウンロードしたら、/path/to/kafka_2.12-2.5.0/libs/に配置します。
ここで、kafka-connect-jdbc用のconfigファイル、configs/jdbc-connect.jsonを作成します。このコンフィグファイルは、コネクタが接続するJDBC URL、使用するトピック、および文字列のtimeフィールドをデータベースで使用される実際のタイムスタンプに変換する方法を指定します。
Kafka Connectを起動する前に、使用する予定の株式銘柄のトピックをすべて作成しておきましょう。
ここで、Kafka Connectを起動します。
データの取り込み
データはまずAlphaAdvantageからCSV形式で取得し、異なるエンドポイントを使用してトレーニング用の過去4ヶ月分のデータを取得し、次にデイリーAPIを使用して異常を見つけます。RESTエンドポイントは以下の通りです。バッチモード(月単位 )https://www.alphavantage.co/query?function=TIME_SERIES_INTRADAY_EXTENDED&symbol=${SYMBOL}&interval=1min&slice=year1month${MONTH}&apikey=${AV_API_KEY} – Daily https://www.alphavantage.co/query?function=TIME_SERIES_INTRADAY&datatype=csv&symbol=${SYMBOL}&interval=1min&apikey=${AV_API_KEY}
返されたCSVはPythonの辞書に入れられます。
produce()関数は、行データ辞書を使用して、Kafkaが必要とするJSONレコードを生成します。
最後に、データは「INTRADAY_${SYMBOL}」トピックのKafkaに送信され、Kafka Connect JDBCコネクタによってGridDBに書き込まれます。
実行する前に、Pipを使ってPythonの依存関係をインストールします。
その後、マニュアルでloadbatch.pyを実行します。
daily importをcrontabに追加することで、毎晩実行されるようになります。これはシステムの時計がUTCに設定されていることを前提としています。
トレーニング
まず、PipでPythonモジュールの依存関係をインストールします。
過去のバッチデータがGridDBにロードされたら、モデルをトレーニングすることができるようになります。過去3ヶ月分のデータを検索し、Pandasのデータフレームとして取得しています。
ここからは、Keras LSTMモデルに期待される入力に合わせてデータを修正します。データの95%はトレーニングに使用し、残りの5%は検証に使用します。
モデル用ストレージ
モデルをGridDBに保存するには、Kerasを使って完全なモデルをファイルシステムにエクスポートすることしかできないため、少し工夫が必要です。まず、モデルを保存するための一時ファイルを作成します。次に、一時ファイルを開き、バイト配列としてGridDBに書き込みます。最後にテンポラリファイルを削除します。
モデルをロードするには、その逆を行います。GridDBから最新のものを読み込み、テンポラリに書き込み、Kerasでロードしてからテンポラリファイルを削除します。
異常検知
トレーニングと同様に、データはGridDBからクエリされ、Pandasのデータフレームに読み込まれた後、モデルに合わせたフォーマットに変換されます。
その後、モデルが読み込まれ、予測が実行されます。異常を発見するために、予測値と実際の値の差(ロス)を計算し、ロスが0.65より大きい値をすべてGridDBに書き戻します。
異常検知スクリプトは、毎日のデータロードが開始されてから1時間後に実行されるよう、crontabにも登録されています。
通知
GridDBの特徴の一つにトリガー機能があり、指定したコンテナに行が書き込まれるたびに、JMSメッセージの送信やREST APIコールを行うように設定することができます。
トリガーのアーキテクチャと実装の詳細については、テクニカルとAPIの参照資料をご覧ください。
GridDBのPythonクライアントはトリガーの追加をサポートしていないため、Javaを使用する必要があります。
REST APIの呼び出しは非常に基本的なもので、Authorizationヘッダーの追加はサポートされていないため、Flaskアプリケーションを作成し、TwiloのSendGridを使ってメールを送信します。
PIPは、トリガーハンドラーアプリケーションを実行する前に、すべてのディペンデンシーをインストールするために使用します。
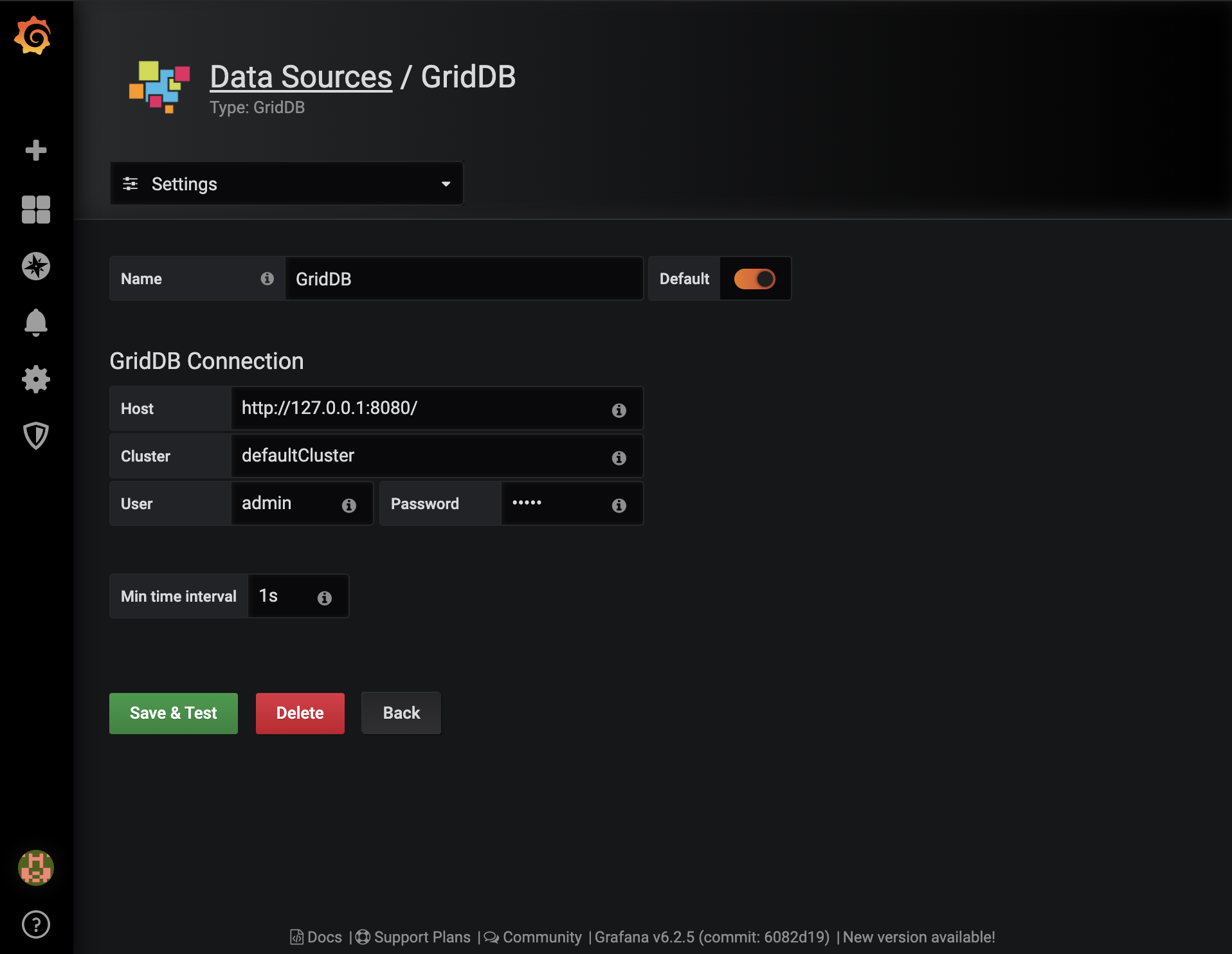
Grafanaは、説明書を参考にしてインストールできます。インストールが完了したら、まず最初にデフォルトのGridDBデータソースを作成し、システム設定に基づいて設定します。
GridDBデータソースをインストールするには、まずtarをダウンロードして解凍し、distディレクトリをGrafanaのシステムディレクトリにコピーします。
Grafana GridDBデータソースの詳しい説明はこちらにあります。
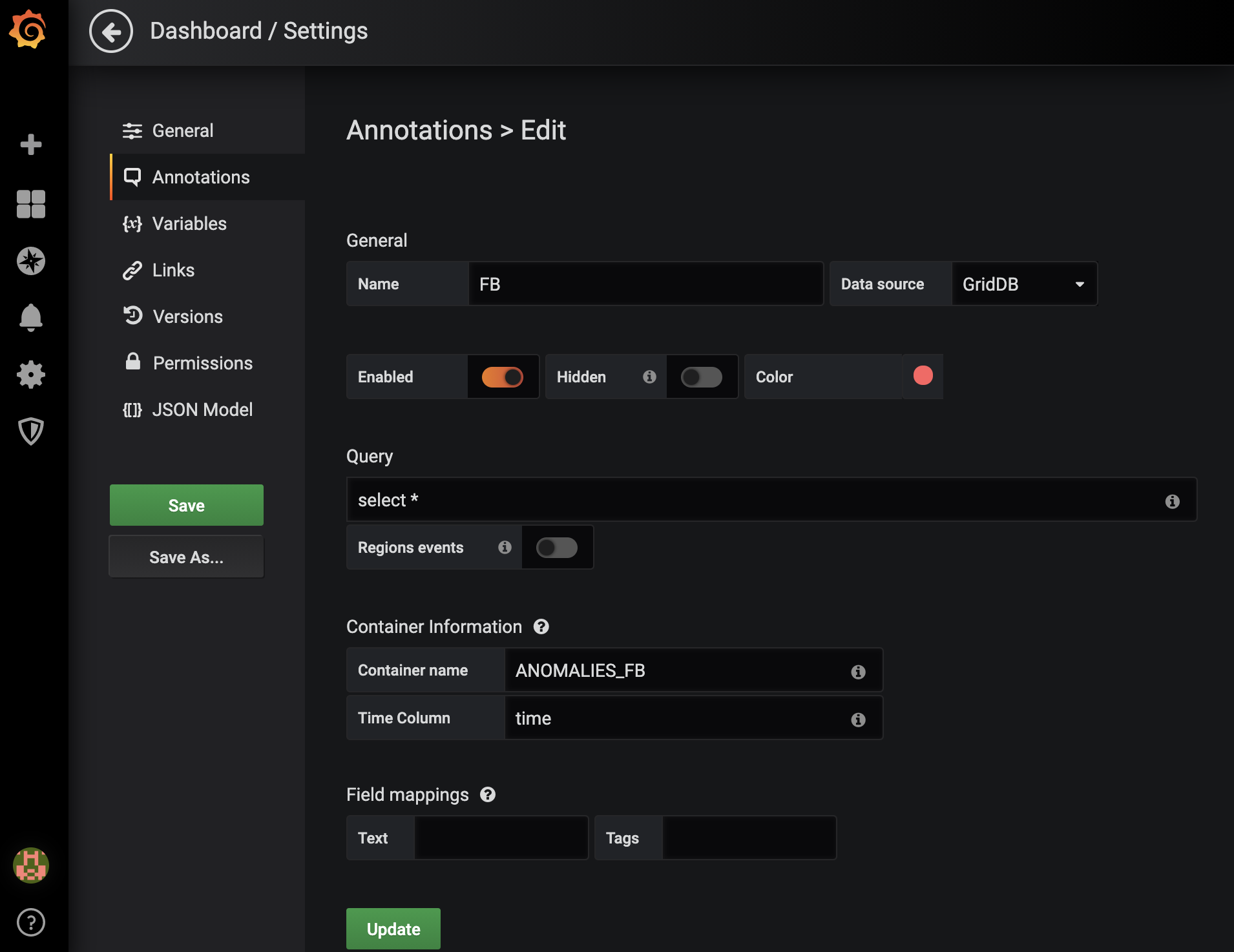
ここで、監視しているすべての株式銘柄に対して1つのダッシュボードを作成します。各ダッシュボードには、特定の銘柄に異常が発生するたびにマークする注釈を付けます。この例では、Facebook (FB) の異常に注目しています。
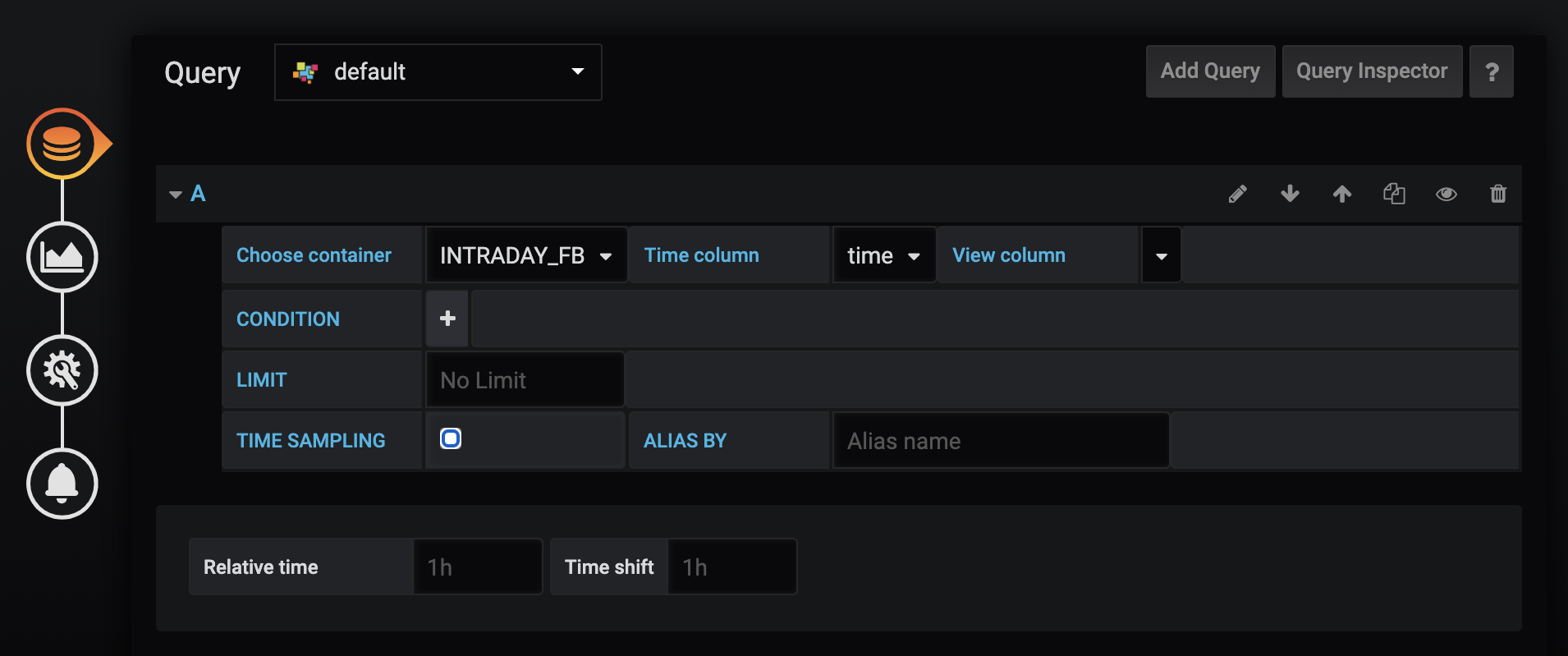
新しいパネルを作成し、クエリを作成します。コンテナ名を「INTRADAY_FB」に設定し、返されるレコードの制限をすべて取り除きます。デフォルトの制限値である10,000では、数週間分のデータしか得られません。
最後に、株価と異常を可視化してみましょう。
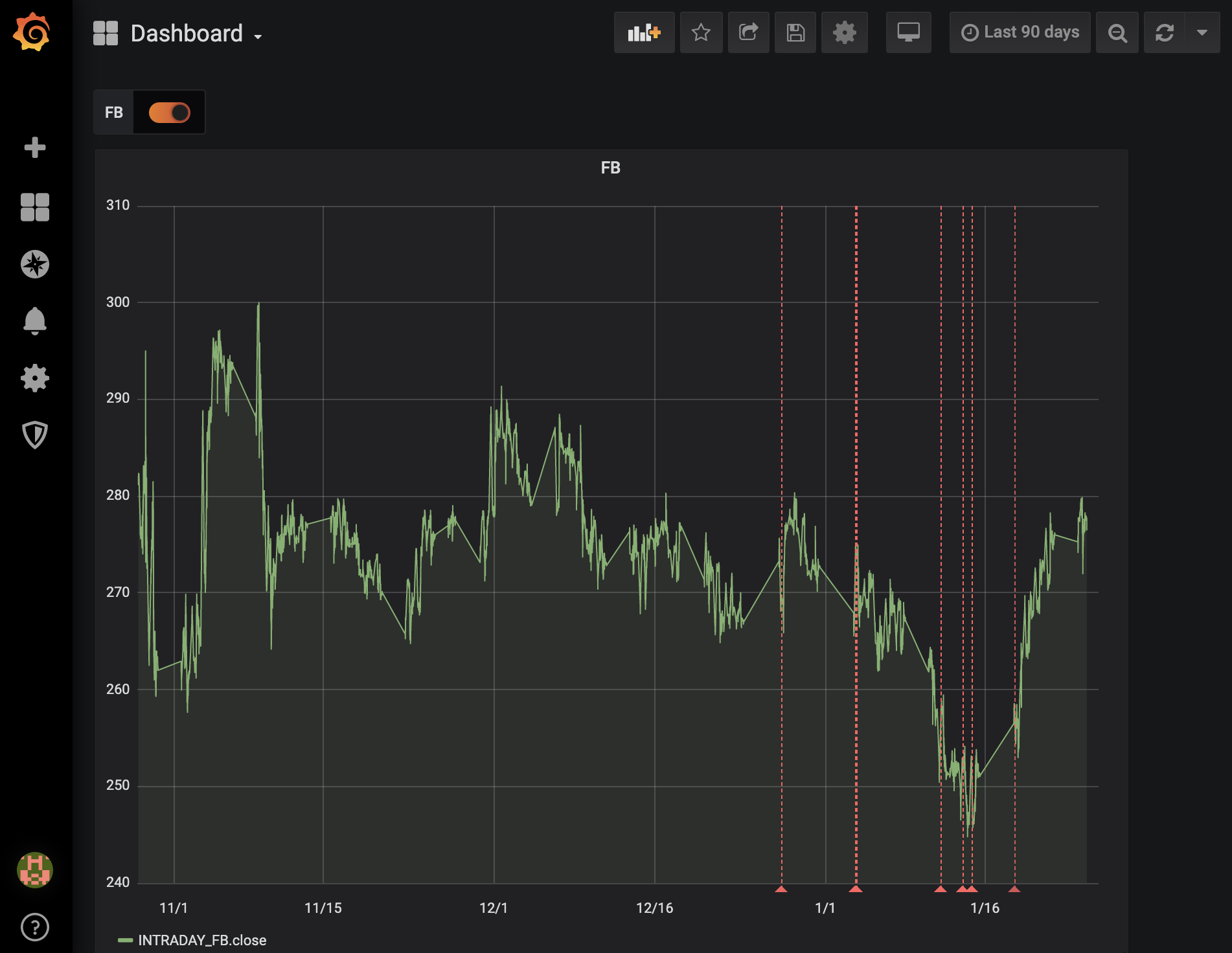
上のグラフでは、株価を主要な時系列とし、異常(予測される価格が実際の価格と大きく異なる場合)を赤の点線で示しています。
結論
このプロジェクトでは、モデルと入出力データの両方を保存する機能を中心に、現実世界で本番運用可能な機械学習プロジェクトの展開において、データストアとしてGridDBがいかに有効であるかを実証しました。また、KafkaやGrafanaなどのオープンソースツールをプロジェクトに組み込むことで、効果的なデータストリーミングや可視化を実現することができました。そして最後に、異常を見逃さないために、GridDBのTrigger機能をSendGridと組み合わせて使用しました。
このプロジェクトの完全なソースコードは、GridDB.netのGitHubページ[https://github.com/griddbnet/stock-anomaly-ml-project]をご参照ください。
If you have any questions about the blog, please create a Stack Overflow post here https://stackoverflow.com/questions/ask?tags=griddb .
Make sure that you use the “griddb” tag so our engineers can quickly reply to your questions.