
プロジェクトの概要
はじめに
このプロジェクトでは、GridDBとStreamlitを使って、インタラクティブなデータサイエンスダッシュボードを作成する方法を紹介します。
GridDBに取り込まれた過去のプロジェクトのデータを基に、Streamlitを使ってニューヨーク市の犯罪の苦情を視覚化します。Streamlitでは、入力や出力に使える様々なウィジェットを使って、どんな種類のダッシュボードでも素早く簡単に開発することができます。このプロジェクトでは、入力ウィジェットを使ってGridDBのTQLクエリ文字列を構築し、チャート出力ウィジェットを使って返されたデータを表示します。
要件
今回のプロジェクトでは、Streamlitをインストールし、Pythonクライアントと一緒にGridDBをインストールしてください。
また、今回使うニューヨーク市の犯罪に関するデータをDBに挿入する必要があります。これについては、以前のブログGridDBを使用したニューヨークの犯罪データの地理空間分析で詳しく紹介しています。
設定
GridDBをインストールする
GridDBをインストールする方法については、ドキュメントを参照してください。
Streamlitをインストールする
Installing Streamlit is done via pip
pip3 install streamlit --user
Note: pipでのインストールに問題がある場合は、pipが最新のバージョンであることを確認してください。
データを取り込む
まず最初に、すべてのデータ(CSV形式)をGridDBサーバに読み込みます。CSVからデータフレームに直接データを読み込むこともできますが、GridDBのhybrid in-memoryアーキテクチャにより、先にデータベースに読み込むことで、アプリケーションの速度が大幅に向上します。さらに、7m行すべてを読み込むのではなく、関連するデータのみをデータフレームに読み込むため、クエリのスピードも向上します。
そこで、NYCのデータを自分のDBに取り込むために、以下のようなスクリプトを使います。データはNYC Open Dataから取得しています。
データを取り込むには、 CSVParser ライブラリを使います。
Iterable records = CSVFormat.RFC4180.withFirstRecordAsHeader().parse(in);
for (CSVRecord record : records) {
Complaint c = parseCsvRecord(record);
if(c != null)
col.put(c);
}
col.commit();詳しい説明については、以前のこちらのブログを参照してください。
基本的な流れとしては、こちらからソースコードをダウンロードし、自分のCLASSPATHにgriddb.jarとCSV parse jarの両方を指定します。そこからIngest.javaをコンパイルして、同じディレクトリにあるrows.csvという名前のデータでJavaファイルを実行します。すると、プログラムが実行され、データがGridDBサーバに取り込まれます。
このプロジェクトを早く済ませたい方は、700万行すべてがDBに取り込まれるのを待つ必要はありません。テストのためには、5万行程度を取り込むだけでもよいでしょう。
GridDBサーバーにデータが入り、Streamlitがインストールされたので、このプロジェクトの本題に入る準備が整いました。
ソースコード
GridDBサーバに接続する
まず、PythonコードをGridDBサーバーに接続します。次のスニペットは、使用したライブラリと接続の詳細を示しています。
#!/usr/bin/python3
import pandas as pd
import streamlit as st
import griddb_python
import datetime
import traceback
griddb = griddb_python
factory = griddb.StoreFactory.get_instance()
gridstore = factory.get_store(
host="239.0.0.1",
port=31999,
cluster_name="defaultCluster",
username="admin",
password="admin"
)GridDBのデフォルトの接続文字列を使用していることがわかります。また、優れたデータサイエンスツールであるpandasを使用しています。PandasでのGridDBの使用についてはこちらのブログGridDB上でPandasのデータフレームを使用するを参照してください。
複数のコンテナを扱う
次に、関連するデータを照会します。データセットは複数のコンテナに保存されているので、アプリは1つ、複数、またはすべてのコンテナを照会できる必要があります。まず最初に、すべてのコンテナへのアクセスが必要なので、辞書を開き、保存します。また、辞書に’all’マッピングを作成し、開いたすべてのコンテナのリストを格納することで、すべての区間に問い合わせができるようにしています。
cols = {}
for x in range(1, 125):
col = gridstore.get_container("precinct_"+str(x))
if col != None:
cols[x] = [col]
cols['all'] = (e[0] for e in cols.values())最後に、Streamlitウィジェットで選択された区間を繰り返し検索します。通常は1つの区間しかありませんが、’all’,の場合はすべての区間が照会されます。簡略化のため、Multiqueryは使用していません。
df=pd.DataFrame()
for col in cols[precinct]:
try:
q = col.query(tql)
rs = q.fetch(False)
df = df.append(rs.fetch_rows())
except:
pass
入力ウィジェット
Streamlitには、ダッシュボードに追加できる様々な入力ウィジェットがあり、その一覧はAPI Referenceに記載されています。
カレンダー
streamlitのdate_inputウィジェットでは、ユーザが開始日と終了日を選択することができます。日付は、datetime.dateオブジェクトのタプルとして返されますが、これはまず、datetime.datetime.combine()を使ってdatetime.datetimeオブジェクトに変換する必要があります。
date_range = st.date_input("Period", [datetime.date(2010, 1,1), datetime.date(2020, 12, 31) ])
start = datetime.datetime.combine(date_range[0], datetime.datetime.min.time())
end = datetime.datetime.combine(date_range[1], datetime.datetime.min.time())その後、datetime.datetimeオブジェクトをint(datetime.datetime.timestamp()¬*1000)でミリ秒単位のエポックに変換し、TQLクエリで使用することができます。
tql = "select * where CMPLNT_FR > TO_TIMESTAMP_MS("+str(int(start.timestamp()*1000))+") AND CMPLNT_FR < TO_TIMESTAMP_MS("+str(int(end.timestamp()*1000))+")"スライダー、ラジオボタン、セレクトボックス
Streamlitの他の入力ウィジェットは非常にシンプルで、それぞれが入力候補のリストを受け取り、選択された項目を返します。
precinct = st.select_slider("Precinct", list(cols.keys()), value='all' )
br_name = st.selectbox("Borough", ["ALL", "MANHATTAN", "QUEENS", "BRONX" , "BROOKLYN", "STATEN ISLAND" ])
ctype = st.radio("Type", ["ALL", "VIOLATION", "MISDEMEANOR" , "FELONY" ])これらの出力は、TQL文で使用することができます。
if br_name != "ALL":
tql = tql + " AND BORO_NM = '"+br_name+"'"
if ctype != "ALL":
tql = tql + " AND LAW_CAT_CD = '"+ctype+"'"出力ウィジェット
今回のプロジェクトで使用する棒グラフ、テキスト、地図など、いくつかの異なる出力ウィジェットが用意されています。
タイトルとテキスト
データを表示する前に、ダッシュボード全体の一体感を出すために、タイトルや補助テキストを表示することもできます。例えば、st.titleを使ってダッシュボードのタイトルを表示すしたり、st.writeを使ってテキストを表示することもできます。
ここでは、すべての入力ウィジェットの前に、タイトルを追加します。
st.title('NYC Crime Complaint Data')
このアプリケーションの目的を簡単に説明してください。
st.write (表示させたい犯罪データの情報を選択してください。完了すると、下部に棒グラフが表示されます。)
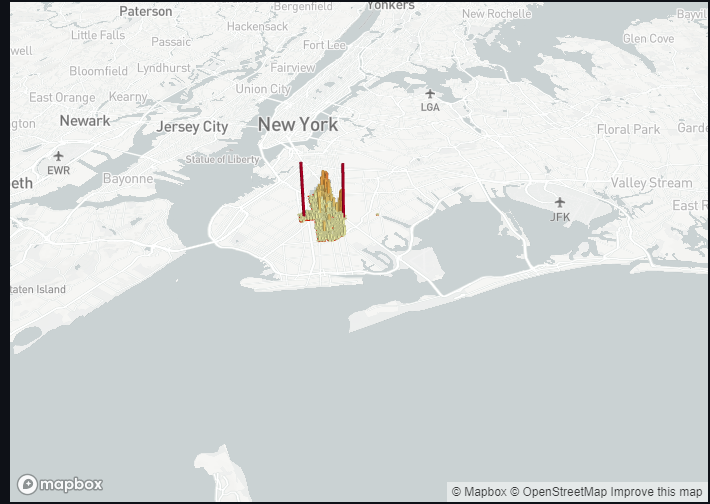
地図
データの地図を表示するには、pydeckのウィジェットを使用します。
if precinct != "all":
df = df.rename(columns={'Latitude': 'lat', 'Longitude': 'lon'})
st.pydeck_chart(pdk.Deck(
map_style='mapbox://styles/mapbox/light-v9',
initial_view_state=pdk.ViewState(
latitude=40.76,
longitude=-73.93,
zoom=10,
pitch=50,
),
layers=[
pdk.Layer(
'HexagonLayer',
data=df,
get_position='[lon, lat]',
radius=100,
get_elevation=500,
elevation_scale=4,
elevation_range=[0, 1000],
pickable=True,
extruded=True,
),
pdk.Layer(
'ScatterplotLayer',
data=df,
get_position='[lon, lat]',
get_color='[200, 30, 0, 160]',
get_radius=100,
),
],
))
else:
print("Can only draw maps for single precincts")まず始めに、レンダリングするデータを、「全区間」よりも小さいデータセットのみに限定する必要があります。すべてのデータポイントを描画しようとすると、スクリプト全体に負担がかかるためです。その後は、すでに設定してあるデータフレームやその他のオプションを入力します。
これで、特定の区間を選択すると、きれいな地図が表示されるはずです。
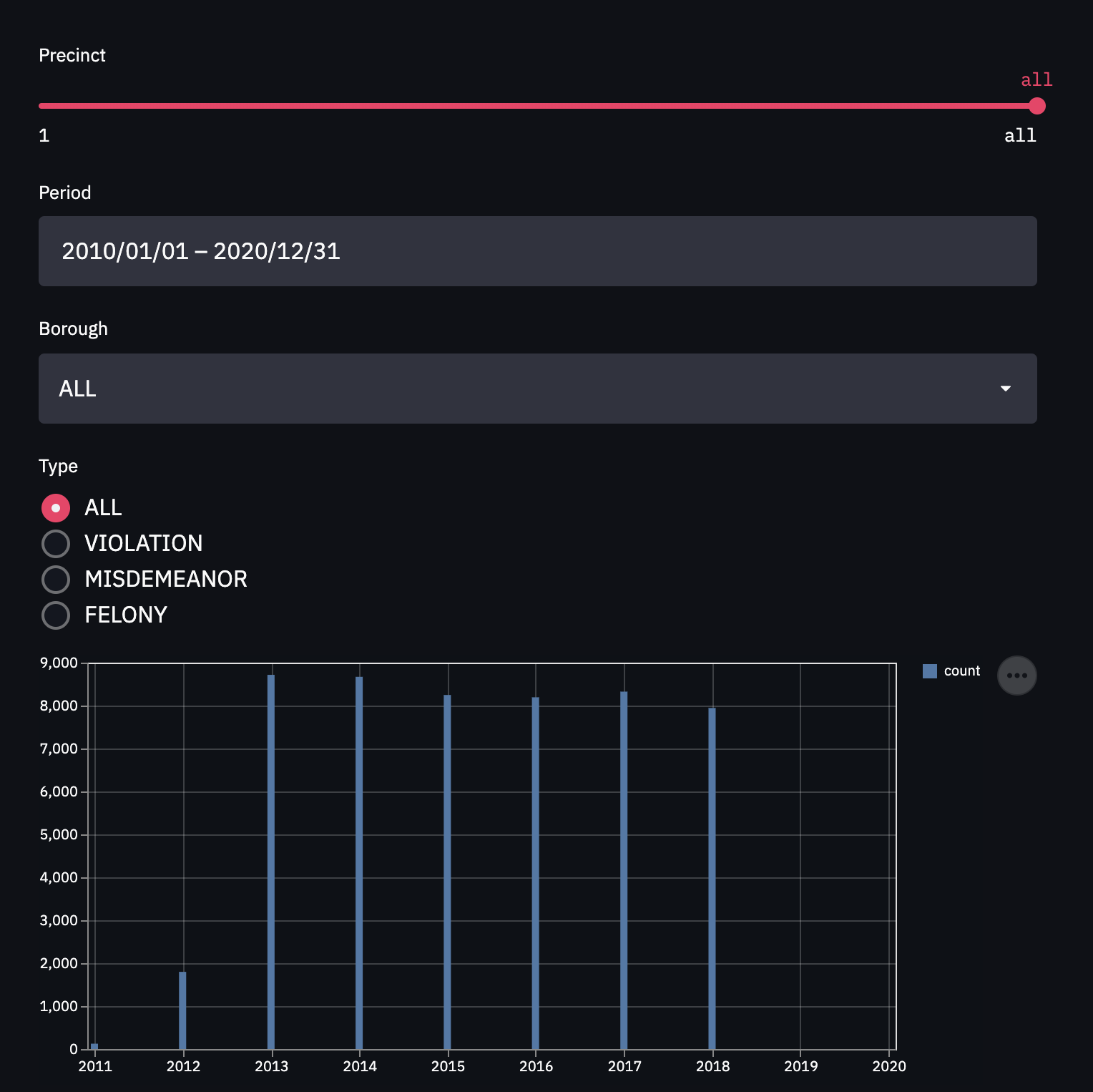
棒グラフ
bucket_sizeの時間における犯罪の苦情の件数を効果的に表示するためには、データをバケット化する必要があります。その前に、まず使用するバケットの数を決定する必要がありますが、これは時間 bucket_size に依存します。もしbucket_sizeが数週間であれば、月単位のバケットを使うのは意味がありませんし、その逆もしかりです。また、bucket_sizeが数年であれば、日単位や週単位のバケットを使ってもデータをうまく視覚化することができません。
bucket_size='Y'
if delta.days < 800:
bucket_size = 'M'
elif delta.days < 90:
bucket_size = 'D'
これで、CMPLNT_FR列をPandas Datetimeに変換して、データをバケットやグループに入れることができるようになりました。
df['CMPLNT_FR'] = pd.to_datetime(df['CMPLNT_FR'])
df = df.groupby([pd.Grouper(key='CMPLNT_FR',freq=bucket_size)]).size().reset_index(name='count')棒グラフの表示は、シンプルなワンライナーにします。
st.bar_chart(data=df)プログラムを実行する
すべての設定が完了したら、プログラムを実行します。
streamlit run app.py
そして、表示された外部URLに従うと、きれいなデータサイエンス・ダッシュボードをブラウザで見ることができます。
まとめ
作成されるダッシュボードの品質と必要なコード量を考慮すると、Streamlitはデータドリブンなダッシュボードを信じられないほど迅速かつ簡単に開発できることを示しました。GridDBの高いパフォーマンスとスケーラビリティを組み合わせることで、開発担当者は多額の投資や時間をかけずにデータセットを視覚化し、洞察を得ることができます。今回のプロジェクトで使用したソースコードは、GridDB.netのGitHubアカウントこちらに掲載されています。
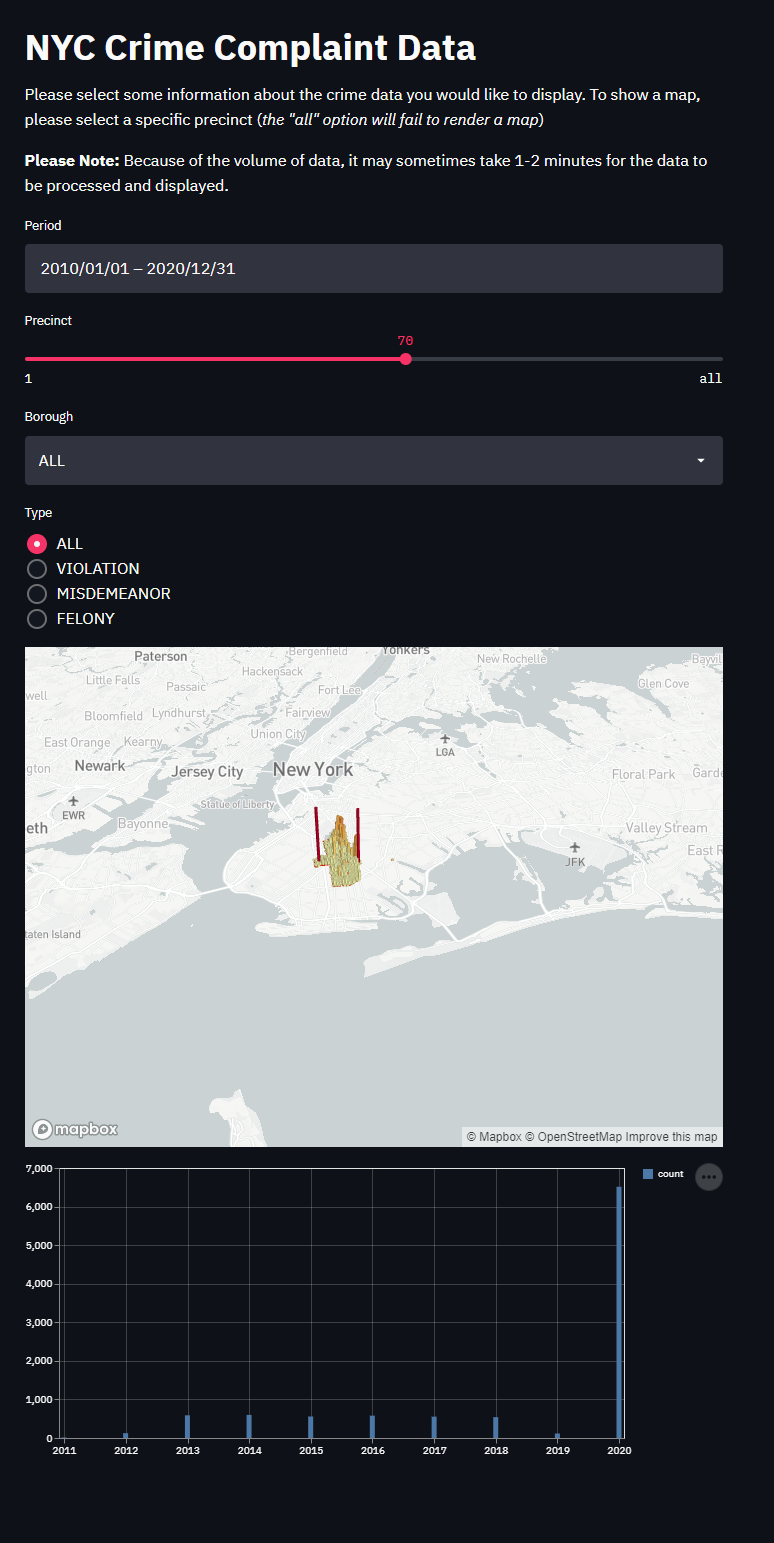
最後に、ダッシュボード全体のスクリーンショットはこのようになりました。
ブログの内容について疑問や質問がある場合は Q&A サイトである Stack Overflow に質問を投稿しましょう。 GridDB 開発者やエンジニアから速やかな回答が得られるようにするためにも "griddb" タグをつけることをお忘れなく。 https://stackoverflow.com/questions/ask?tags=griddb