はじめに
データ分析とは、生データから意味のあるデータを得るためのプロセスです。適切な分析を行わなければ、どんなデータセットも単なる情報の集まりになってしまいます。この記事では、データ可視化の手法を用いて、構造化されたデータを意味のあるデータに変換する方法を学びます。
前回の記事では、構造化された方法でデータベースにデータを保存する方法と、データベースからデータを取り出す方法を学びました。今回の記事では、データの可視化によって実現できることと、分析のニーズに合わせてデータベースからデータを取得する方法に焦点を当てます。
前提条件
このチュートリアルでは、プログラミング言語としてPythonを使用し、データ分析と視覚化のためにpandas、matplotlib、foliumライブラリを利用します。また、データベースとの連携には、GridDB Pythonコネクタを使用します。
さらに、GridDBインスタンスを設定し、Kaggleから入手したFormula 1 World Championship (1950 – 2020)データセットから必要なすべてのコレクションを作成する必要があります。
データ構造
以下は、データの可視化に使用するGridDBインスタンス内のコレクションです。
| フィールド名 | データ型 (GridDB) | 備考 |
|---|---|---|
| CircuitID | INTEGER | サーキットの識別子 |
| CircuitRef | STRING | |
| name | STRING | |
| location | STRING | サーキットがある都市 |
| country | STRING | |
| lat | FLOAT | |
| lng | FLOAT | |
| url | String | Wiki記事のURL |
| フィールド名 | データ型 (GridDB) | 備考 |
|---|---|---|
| raceid | INTEGER | レースの識別子 |
| year | STRING | |
| round | STRING | |
| circuitid | INTEGER | サーキットがある都市 |
| name | STRING | |
| raceTime | TIMESTAMP | |
| url | STRING | Wiki記事のURL |
基本的なデータの見せ方
データを分析したり可視化したりする前に、まずはデータベースからデータを取得する必要があります。ここでは、データの取得方法について少しおさらいします。GridDB は、データベースへの問い合わせを行うための TQL クエリ言語を提供しています。
データを取得するためには、接続を作成し、コレクションを取得し、コレクションオブジェクトに対してクエリを実行する必要があります。以下のコードブロックは、データベース内のコンテナを取得する方法を示しています。
$ sudo yum -y install griddb_nosql griddb-c-client
factory = griddb.StoreFactory.get_instance()
try:
# Create gridstore object
gridstore = factory.get_store(
host='239.0.0.1',
port=31999,
cluster_name='defaultCluster',
username='admin',
password='admin'
)
# Define the container names
circuits_container = "circuits"
races_container = "races"
# Get the containers
circuits_data = gridstore.get_container(circuits_container)
races_data = gridstore.get_container(races_container)
except griddb.GSException as e:
for i in range(e.get_error_stack_size()):
print("[", i, "]")
print(e.get_error_code(i))
print(e.get_location(i))
print(e.get_message(i))
現在、私たちは2つの異なるオブジェクトにデータを持っています。これらのデータを適切なフォーマットに変換して、簡単に分析できるようにする必要があります。ここで “Pandas “ライブラリの出番となり、データをPandas DataFramesに変換します。
そのためには、2つのコンテナ内のすべてのデータを選択し、それらのデータからリストを作成し、さらにそのリストをDataFrameに変換するクエリを書く必要があります。以下は、そのためのシンプルなTQLクエリです。
# Select all rows from circuits_container
query = circuits_data.query("select *")
rs = query.fetch(False)
# Create a list
retrieved_data= []
while rs.has_next():
data = rs.next()
retrieved_data.append(data)
# Convert the list to a pandas data frame
circuits_dataframe = pd.DataFrame(retrieved_data, columns=['circuitId', 'circuitRef', 'name', 'location', 'country', 'lat', 'lng', 'url'])
# Select all rows from races_container
query = races_data.query("select *")
rs = query.fetch()
# Create a list
retrieved_data= []
while rs.has_next():
data = rs.next()
retrieved_data.append(data)
# Convert the list to a pandas data frame
races_dataframe = pd.DataFrame(retrieved_data, columns=['raceID', 'year', 'round', 'circuitId', 'name', 'url', 'raceTime'])
HTMLテーブルの作成
データを表現する最もシンプルな方法の一つにテーブルがあります。pandasライブラリには、データフレームをHTMLテーブルに変換するためのto_html関数が用意されています。
races_dataframe.to_html('races_data.html')上記の関数は、シンプルなHTMLテーブルを作成します。しかし、テーブル内のデータを見栄えよく表示する必要があります。そのためには、データフレームにフォーマットを追加し、スタイルシートを添付した適切なHTMLページ内に、作成したHTMLテーブルを埋め込んでみましょう。
# Create the HTML Page Structure
# Include the Style Sheet
html_string = '''
<html>
<link rel="stylesheet" type="text/css" href="style.css"/>
<body>
<h1>Races Collection</h1>
{table}
</body>
</html>
'''
# Rename the Columns Headers
races_dataframe.rename(columns={'raceId': 'Race ID', 'circuitId': 'Circuit ID', 'raceTime': 'Race Time'}, inplace=True)
# Convert the Headers to Uppercase
races_dataframe.rename(str.upper, axis='columns', inplace=True)
# Write to HTML File
with open('races_table.html', 'w') as f:
# Pass the DataFrame to the HTML String
f.write(html_string.format(table=races_dataframe.to_html(index=False, render_links=True, escape=False, justify='left', classes='htmlfilestyle')))
CSSファイルです。
.htmlfilestyle {
font-size: 11pt;
font-family: Arial;
border-collapse: collapse;
border: 1px solid silver;
}
.htmlfilestyle td, th {
padding: 5px;
font-size: 12pt;
}
.htmlfilestyle tr:nth-child(even) {
background: #E0E0E0;
}
.htmlfilestyle tr:hover {
background: silver;
cursor: pointer;
}
これにより、与えられたデータフレームを使用してデータをよりよく表現する、整形されたHTMLテーブルが提供されます。
TQLを使う
GridDBが提供するTQLクエリ言語を利用することで、データベースから取得したデータセットをさらに絞り込むことができます。データセットの構造や値によって、分析や視覚化できる内容が異なります。GridDBの論理演算子、比較演算子、文字列演算子、数値演算子、配列演算子、空間演算子、時間演算子を利用することで、必要なデータを得るための効率的なクエリを行うことができます。ここでは、データセットのフィルタリングに使用できるいくつかのTQL文を見てみましょう。
races コレクション
モナコ・グランプリのレースだけを取得します。
races_data.query("select * where name = 'Monaco Grand Prix'")
さらに2010年と2015年の間のレースのみを取得します。
# Using year field query = races_data.query("select * where year >= 2009 AND year <= 2015 ORDER BY raceTime DESC")
# Using raceTime field races_data.query("select * where raceTime >= TIMESTAMP('2010-01-01T00:00:00.000Z') AND year <= TIMESTAMP('2015-12-31T23:59:59.000Z')")
過去5年間を除くレースを取得します。
# TIMESTAPADD function is used to exclude 5 years from the current time races_data.query("select * where raceTime < TIMESTAMPADD(YEAR, NOW(), -5)")
1990年に行われたレースの数を数えます。
query = races_data.query("select COUNT(*) where year = 2009")
rs = query.fetch(False)
# Obtain the calculated value
while rs.has_next():
data = rs.next()
count = data.get(griddb.Type.LONG)
print(count)
レコード数を100に制限します。
races_data.query("select * LIMIT 100")
circuits コレクション
ドイツ国内にあるサーキットを取得します。
circuits_data.query("select * where country = 'Germany'")
サーキット数を算出します。
circuits_data.query("select COUNT(*)")
rs = query.fetch(False)
# Obtain the calculated value
while rs.has_next():
data = rs.next()
count = data.get(griddb.Type.LONG)
print(count)
イギリス、フランス、スペインにあるサーキットを取得します。
circuits_data.query("select * where country = 'UK' OR country = 'France' OR country = 'Spain' ORDER BY name DESC")
名前に”Park”や”Speedway”を含むサーキットを取得します。
circuits_data.query("select * where name LIKE '%Park%' OR name LIKE '%Speedway%' ORDER BY name DESC")
TQLでデータを抽出する場合、2つの制限があります。1つは、集約操作を除き、SQLのように特定の列を選択することができないこと。もう1つは、GROUP BY、HAVING、DISTINCT、JOINなどのステートメントがサポートされていないことです。
しかし、GridDBでは、TQLの制限を超えて、SQLインターフェイスで上記の文をすべてサポートしています。もう一つの方法として、Pandas DataFramesを利用することができます。Pandasは、特定の列を選択したり、データフレームを結合したり、列をグループ化したりする機能を提供しており、上記の欠点を本質的に解消しています。GridDBとPandasライブラリを組み合わせることで、データを使って実現できることが大幅に広がり、より高度な分析が可能になります。TQLの詳細については、公式ドキュメントをご参照ください。
Pandasを使ったグラフの作成
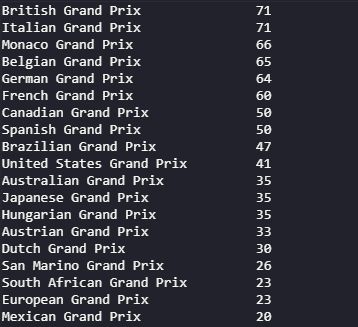
Pandasには、データフレームを使ってグラフを作成する機能が組み込まれています。ここでは、各会場で開催されたレースの数を示す棒グラフを作成する方法を見てみましょう。
value_counts関数を使うと、特定の列(この例ではデータセットの “name “列)のユニークな値を数えることができます。そして、カウントされたデータを格納する別の変数を作成し、それを使ってfigsize、title、x,yラベルのオプションで棒グラフをプロットします。kindパラメータは、チャートの種類を選択するために使用します。グラフは、デフォルトのバックエンドとしてmatplotlibライブラリを使用して生成されます。
# Print the count
print(races_dataframe['name'].value_counts())
# Obtain the count of each venue
plotdata = races_dataframe['name'].value_counts()
# Plot the data as a bar chart
plotdata.plot(kind="bar", figsize=(20,10), title="Race Locations", xlabel="Races", ylabel="No of Races")
以下の出力を得ることが出来ます。

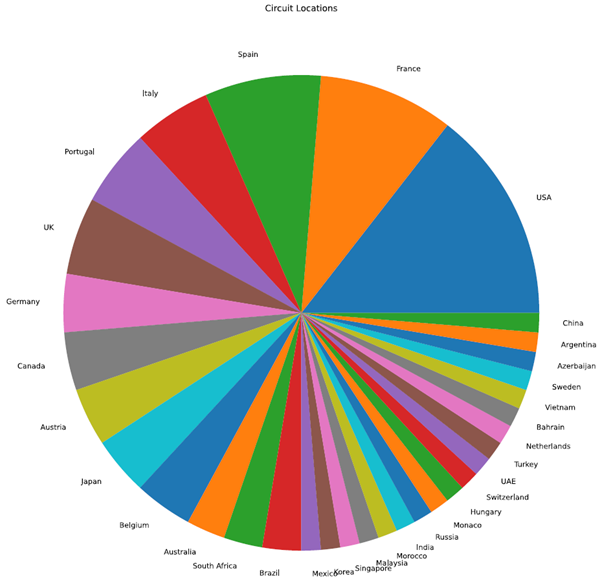
次に、サーキットのデータセットを使って円グラフを作成します。国の列を使って、各参加国に分布するレースサーキットの数を分析することができます。円グラフを作成するには、グラフの種類を “pie” に設定する必要があります。
# Print the count
print(circuits_dataframe['country'].value_counts())
# Obtain the count of each venue
plotdata = circuits_dataframe['country'].value_counts()
# Plot the data as a pie chart
# Disable the legend and ylabel
plotdata.plot(kind="pie", figsize=(30,15), title="Circuit Locations", legend=False, ylabel="")
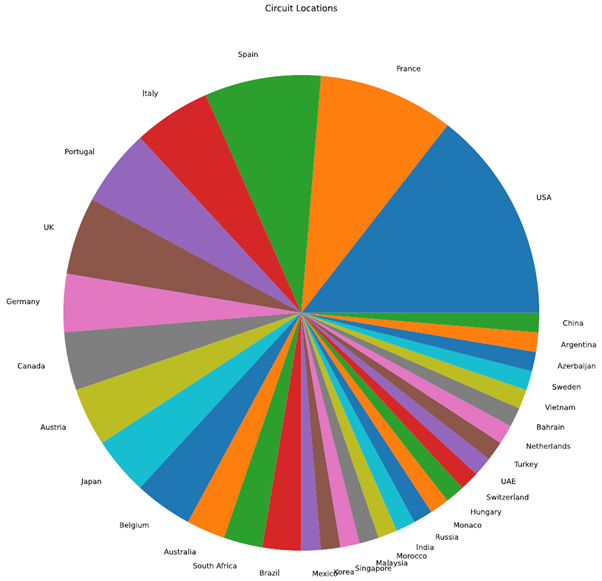
上記の例からわかるように、データフレームをプロットすることでデータを可視化することができます。これはプロッティングで実現できることのほんの一部であり、追加のフィルタやフォーマットを使ってさらに洗練させることも可能です。プロット機能の詳細については、公式ドキュメントを参照してください。
Matplotlibを使った表の作成
前の例では、pandas data framesを使ってHTMLテーブルを作成する方法を学びました。しかし、テーブルをより細かく制御する必要がある場合は、matplotlibライブラリを介してテーブルを生成するのが良いでしょう。
この例では、GridDBデータベースの “circuits “コレクションから10件のレコードを照会し、そのデータを使ってデータフレームを作成します。
circuits_data.query("select * LIMIT 10")
データフレームを基本データセットとして、次のコードブロックに示すようにテーブルを作成します。ここでは、サブプロットを持つプロットオブジェクトを作成し、データフレームの値を必要な列(cellTextとcolLabels)とフォーマットに割り当てます。そして、タイトルとフッターを追加し、最後に表をpng画像ファイルとして保存します。
# Create the plot object
fig, ax =plt.subplots(
figsize=(20, 6),
linewidth=2,
tight_layout={'pad':1})
# Turn off the axis
ax.axis('off')
# Set background color
ax.set_facecolor("#ffffff")
table = ax.table(
# Define cell values
cellText=circuits_dataframe.values,
# Define column headings
colLabels=circuits_dataframe.columns,
# Column Options - color and width
colColours=['skyblue']*8,
colWidths=[0.03,0.06,0.1,0.05,0.04,0.06,0.06,0.135],
loc="center")
# Set the font size
table.auto_set_font_size(False)
table.set_fontsize(10)
# Scale the table
table.scale(1.8, 1.8)
# Add title
plt.suptitle("Circuits Collection", size=25, weight='light')
# Add footer
plt.figtext(0.95, 0.05, "GridDB Data Collection", horizontalalignment='right', size=6, weight='light')
# Draw and save the table as a png
plt.draw()
plt.savefig('table.png',dpi=150)
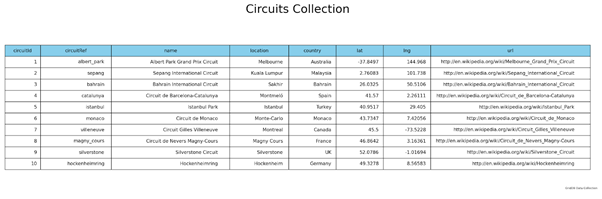
Matplotlibは、データビジュアライゼーションのための最も広く使用されているPythonライブラリです。Matplotlibは,シンプルな表やグラフから複雑な3Dグラフまで,可視化の各側面を完全に制御しながら作成することができます.Matplotlibに関する詳しい情報は,matplotlib ドキュメントを参照してください。
Foliumライブラリによる地図の作成
FoliumはPythonの可視化ライブラリで、地図の作成に使用できます。マップを作成するためにPythonとleaflet.jsを組み合わせています。この組み合わせにより、ユーザーはPythonで変換されたデータをインタラクティブなリーフレットマップにバインドすることができます。ここでは、GridDBの “circuits “コレクションから取得した緯度・経度データを用いて、世界地図上にレースサーキットの位置をマッピングしてみましょう。
以下のコードブロックでは、MakeCluster関数を使用して、世界地図オブジェクトと、すべてのサーキットの位置を含むクラスタを作成しています。次に、データフレームを繰り返し処理して、緯度(lat)と経度(lng)を抽出し、各場所に個別のマーカーを作成して、クラスタに追加します。さらに、各反復において名前と国のデータを抽出し、クリック可能なポップアップに含めます。
# Create map object
world_map= folium.Map()
# Create marker cluster
marker_cluster = MarkerCluster().add_to(world_map)
# Create marker for each coordinates
for i in range(len(circuits_dataframe)):
# Get latitude and longitude from data frame
latitude = circuits_dataframe.iloc[i]['lat']
longitude = circuits_dataframe.iloc[i]['lng']
# Set circle radius
radius=5
# Create the popup
popup_text = """Country : {}<br /> Circuit Name : {}<br />"""
popup_text = popup_text.format(
circuits_dataframe.iloc[i]['country'],
circuits_dataframe.iloc[i]['name'])
test = folium.Html(popup_text, script=True)
popup = folium.Popup(test, max_width=250,min_width=250)
# Add marker to marker_cluster
folium.CircleMarker(location=[latitude, longitude], radius=radius, popup=popup, fill =True).add_to(marker_cluster)
# View the Map
world_map
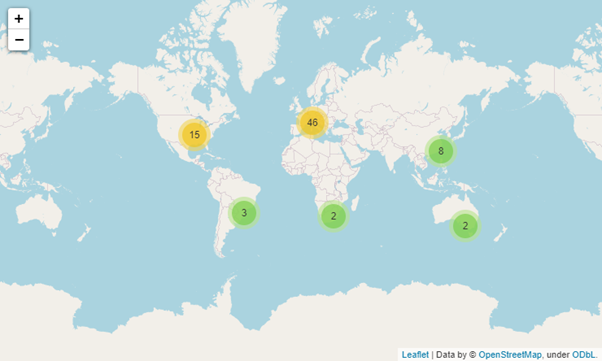
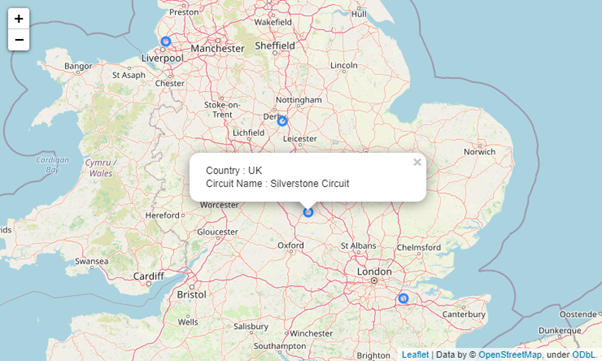
Foliumは強力かつシンプルなライブラリで、データを地図上に可視化するために簡単に適用することができます。詳細については、folium ドキュメントをチェックして、地図によるデータ可視化の旅を始めてください。
結論
本記事では、データビジュアライゼーションの基本を紹介しました。GridDBコレクションから取得したデータを組み合わせて、データを分析し、それらのデータをより理解するために、表、チャート、マップを作成して視覚化しました。Pandas、matplotlib、foliumなどは、Pythonで利用できるデータ分析・可視化のための強力なライブラリのほんの一部に過ぎません。データ分析は、人生をかけて学ぶことができる魅力的なテーマです。この記事を読んだ方が、データ分析とデータビジュアライゼーションの世界に深く足を踏み入れるきっかけになれば幸いです。
ソースコード
このブログで紹介したソースコードはこちらから取得できます。
ブログの内容について疑問や質問がある場合は Q&A サイトである Stack Overflow に質問を投稿しましょう。 GridDB 開発者やエンジニアから速やかな回答が得られるようにするためにも "griddb" タグをつけることをお忘れなく。 https://stackoverflow.com/questions/ask?tags=griddb