
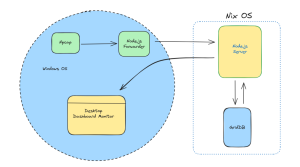



はじめに
GridDB Community Edition version 4.6がリリースされたことを受けて、私たちが最も期待している新機能をこのブログを読んでいる皆様に紹介したいと思います。今回は、新機能であるSQLアグリゲート機能と、新機能であるコマンドラインインターフェース(CLI)ツールを中心にご紹介します。この新リリースは、通常通り、 GitHub.com から無料で入手することができます。
インストールするには、ダウンロードして、Getting Started: Using RPM/YUM にある標準的な手順に従ってください。また、v4.6の新機能を最大限に活用するためには、GridDB CLIツールのインストールが必要となります。このコマンドラインツールはクラスタ運用管理用のコマンドインタプリタですが、ここでは単にgs_shと表記します。このツールの主な目的は、開発者がGridDBのクラスタやデータの運用を管理する手段を提供することです。また、新たにSQLアグリゲーションの機能が追加されました。ここでは説明しませんが、以下のページで紹介されています。https://docs.griddb.net/sqlreference/sql-commands-supported/#aggregate-functions
インストール
gs_shは、RPMのパッケージに含まれているので非常に簡単にインストールすることができます。
$ wget https://github.com/griddb/cli/releases/download/v4.6.0/griddb-ce-cli-4.6.0-linux.x86_64.rpm
$ sudo rpm -ivh griddb-ce-cli-X.X.X-linux.x86_64.rpm また、以下のようにして /usr/share/java/ ディレクトリに griddb-jdbc.jar をセットアップしてください。詳細はこちらを参照してください。https://griddb.net/en/blog/connecting-to-griddb-via-jdbc-with-sqlworkbench-j/。ここでは簡単にまとめてみました。
$ wget https://repo1.maven.org/maven2/com/github/griddb/gridstore-jdbc/4.5.0/gridstore-jdbc-4.5.0.jar
最新版のjdbcファイルを使用しているかどうかは、GitHubで確認できます。 インストールについては以上です。
クラスタ操作制御コマンドインタプリタ (gs_sh)
特徴 前述したように、このツールは開発者がGridDBクラスタやデータの運用を管理する手段を提供するためのものです。つまり、このツールを使用することで以下のことが可能になります。
- クラスタステータスの表示
- データベースとユーザーの管理
- コレクションとトリガーの表示
- インデックス設定、インデックス削除
- TQL/SQLを使った検索
使用方法
基礎編 それでは、早速使ってみましょう。まずは、シェルに直接入力してください。
$ gs_sh
gs> version
gs_sh-ce version 4.6.0動作の確認ができたところで、この機能を使用するための前提となる手順を行います。このセクションでは、デフォルトの gsadmユーザ以外の gs ユーザを新規に作成し、GridDB クラスタの定義をツールに伝える必要があります。
GridDBクラスタの定義
方法1:同期 ノードとクラスタを定義するにはいくつかの方法があります。既に GridDB インスタンスを使用して v4.6 に入っている場合は、既に定義されている GridDB クラスタを使用するため、この1つ目の方法が簡単です。この方法では、conf/gs_cluster.jsonの設定を同期するだけです。シェルに入って、ユーザ名とパスワードを設定した後、次の設定をsyncします。sync <IP Address> <Port Number> <Cluster var name> <node variables>
gs> setuser admin admin
gs> sync 127.0.0.1 10040 defaultCluster node0次のようにshowコマンドを実行して、詳細が正しく表示されていることを確認します。
gs> showNode variable:
node01=Node[10.0.1.6:10040,ssh=22]
Cluster variable: defaultCluster=Cluster[name=defaultCluster,mode=MULTICAST,transaction=239.0.0.1:31999,sql=239.0.0.1:41999,nodes=($node01)]
Other variables:
user=admin
password=*****
ospassword=注上記の設定は、https://docs.griddb.netのガイドで示されている「デフォルト」の設定です。
方法2:最初から設定する 2つ目の方法は、クラスタを起動する前にすべての設定を行うため、より複雑です。手順は以下の通りです。まず、現在のクラスタの構成を明示的に定義する必要があります。gsシェルに入って、以下のようにノードを定義します。
setnode <Node variable> <IP address> <Port no.> [<SSH port no.>] 具体的な例としては:
gs> setnode node0 192.168.0.1 10000
gs> setnode node1 192.168.0.2 10000Once done there, we can set any of the following cluster config: multicast, 上記の設定が済んだら、マルチキャスト、固定リスト、またはプロバイダ方式のクラスター設定のどれかを設定することができるようになります。今回の例では、マルチキャストに設定します。完全なコマンドは次のようになります。 setcluster <Cluster variable> <Cluster name> <Multicast address> <Port no.> [<Node variable> ...] 例:
gs> setcluster cluster0 name 200.0.0.1 1000 $node0
ノードを追加、削除したい場合は、
gs> modcluster cluster0 add $node1
gs> modcluster cluster0 remove $node1各GridDBノード環境(後述)に、adminユーザgsadm以外のユーザで接続できるようにするためには、新しくユーザーを設定する必要があります。 そのためには、 setuser <Username> <Password>
gs> setuser admin adminまた、一度に設定できるユーザーは1人だけですのでご注意ください。ユーザー、パスワードを変更したい場合は、上記のコマンドを再実行してください。
その他のコマンド、用途 独自の変数を設定して、重要な情報を手元に置いておくことができます。例えば、GS_PORTを宣言することができます。
gs> set GS_PORT 10000そして、showですべての変数やその他の便利なアイテムを表示することができます。
gs> showNode variable:
node0=Node[192.168.0.1:10000,ssh=22]
node1=Node[192.168.0.2:10000,ssh=22]
Cluster variable:
cluster0=Cluster[name=name,mode=MULTICAST,transaction=200.0.0.1:1000,nodes=($node0)]
Other variables:
user=admin
password=*****
ospassword=
GS_PORT=10000クラスタの定義が完了したら、その設定をスクリプトに保存することができます。
gs> save test.gshそして、読み込みます。
gs> load test.gshまた、注意点として、gs_shコマンドを実行する際には、適切な管理者権限を持っていることを確認してください。ログに書き込めないというエラーが出ると、.gshファイルの保存と読み込みがうまくいきません。スクリプトファイルを保存しておけば、次回シェルを起動したときに、プロセスを開始するときに実行するオプションの一つとして追加するだけで済みます。
$ gs_sh test.gshクラスターオペレーションコントロール ここでは、これらのコントロール機能で何ができるのかを簡単に説明します。
- 実行中のSQL処理を表示 (
showsql) - 実行中のイベントを表示 (
showevent) - 接続を表示 (
showconnection) - のキャンセル (
killsql <query ID>)
基本 例えば、現在実行中のクエリがあれば、それを入力するだけで表示することができます。
gs> showsql以下は出力例です。
=======================================================================
query id: e6bf24f5-d811-4b45-95cb-ecc643922149:3
start time: 2019-04-02T06:02:36.93900
elapsed time: 53
database name: public
application name: gs_admin
node: 192.168.56.101:10040
sql: INSERT INTO TAB_711_0101 SELECT a.id, b.longval FROM TAB_711_0001 a LEFT OU
job id: e6bf24f5-d811-4b45-95cb-ecc643922149:3:5:0
node: 192.168.56.101:10040
#---------------------------
データベースでのデータ操作 このブログの目的のために、私はこちらの
ブログのデータセットを使用しています。はじめに、操作する予定のクラスタに接続します。
gs> connect $cluster0ここで、クラスタ名が重要であることに注意してください。先に説明した同期手順に従って私の場合は以下のようにします。
gs> connect $defaultCluster接続の試行は成功しました(NoSQL)。 接続の試みは成功しました(NewSQL)。 接続が完了したので、いくつかのクエリを実行してみましょう。シェルでTQLコマンドを実行するには、
gs[public]> tql LosAngelesNO2 select *;
4,344 results. (0 ms)
gs[public]> get 1
timestamp,notwo
2019-01-01T00:00:00.000Z,1.4
The 1 results had been acquired.そしてSQLについては、
gs[public]> sql select * from LosAngelesNO2;
4,344 results. (1 ms)
gs[public]> get 10
timestamp,notwo
2019-01-01T00:00:00.000Z,1.4
2019-01-01T01:00:00.000Z,1.6
2019-01-01T02:00:00.000Z,3.5
2019-01-01T03:00:00.000Z,1.3
2019-01-01T04:00:00.000Z,1.3
2019-01-01T05:00:00.000Z,1.0
2019-01-01T06:00:00.000Z,1.9
2019-01-01T07:00:00.000Z,3.0
2019-01-01T08:00:00.000Z,3.4
2019-01-01T09:00:00.000Z,1.5
The 10 results had been acquired.最初のコマンドは検索で、2番目のコマンドは実際に結果を出力します。また、クエリをCSVファイルに保存することもできます。
gs[public]> getcsv test.csv 1000
The 1,000 results had been acquired.
The 1,000 results had been acquired.完了したら、ぶら下がっている接続をすべて閉じます。
gs[public]> tqlclose
gs[public]> queryclosegs[public]> disconnect
Disconnected connection attempt was successful.コンテナの管理 シェルを使ってコンテナの作成・削除・更新を行うこともできます。コレクションコンテナを作成するには、
createcollection <Container name> <Column name> <Column type> [<Column name> <Column type> ...]
gs[public]> createcollection test col01 stringそして、タイムシリーズ・コレクションです。
createtimeseries <Container name> <Compression method> <Column name> <Column type> [<Column name> <Column type> ...]
gs[public]> createtimeseries testTS NO colTS timestampそして、コンテナを落とします。
gs[public]> dropcontainer col01もう一つの便利なコンテナ機能は、showcontainerコマンドです。
gs[public]> showcontainer
Database : public
Name : LosAngelesNO2
Type : TIME_SERIES
Partition ID: 24
DataAffinity: -
Compression Method : NO
Compression Window : -
Row Expiration Time: -
Row Expiration Division Count: -
Columns:
No Name Type CSTR RowKey Compression
------------------------------------------------------------------------------
0 timestamp TIMESTAMP NN [RowKey]
1 notwo DOUBLE
コンテナの中を探して見つけるには、
gs[public]> searchcontainer LosAngelesNO2
LosAngelesNO2
gs[public]> searchcontainer LosAngeles%
LosAngelesNO2
LosAngelesCO
注 同様のコマンドが行にもあります。 putrow と removerow です。
インデックス インデックスの作成は簡単です。
createindex <Container name> <Column name> <Index type> ...
gs[public]> createindex LosAngelesNO2 notwo tree
gs[public]> showcontainer LosAngelesNO2
Database : public
Name : LosAngelesNO2
Type : TIME_SERIES
Partition ID: 24
DataAffinity: -
Compression Method : NO
Compression Window : -
Row Expiration Time: -
Row Expiration Division Count: -
Columns:
No Name Type CSTR RowKey Compression
------------------------------------------------------------------------------
0 timestamp TIMESTAMP NN [RowKey]
1 notwo DOUBLE
Indexes:
Name :
Type : TREE
Columns:
No Name
--------------------------
0 notwoそして、インデックスを削除するには、
gs[public]> dropindex LosAngelesNO2 notwo tree
gs[public]> showcontainer LosAngelesNO2
Database : public
Name : LosAngelesNO2
Type : TIME_SERIES
Partition ID: 24
DataAffinity: -
Compression Method : NO
Compression Window : -
Row Expiration Time: -
Row Expiration Division Count: -
Columns:
No Name Type CSTR RowKey Compression
------------------------------------------------------------------------------
0 timestamp TIMESTAMP NN [RowKey]
1 notwo DOUBLEまとめ 今回のブログで紹介できなかった機能はまだまだ他にもありますが、今回紹介した内容だけでも、GridDB Community Edition v4.6の最新のリリースに含まれるすべての新機能を使ってみたいと感じてもらえたのではないかと思います。GridDB Community Edition v4.6の全ての機能について詳しく知るには、GitHubの仕様一覧をご覧ください。
ブログの内容について疑問や質問がある場合は Q&A サイトである Stack Overflow に質問を投稿しましょう。 GridDB 開発者やエンジニアから速やかな回答が得られるようにするためにも "griddb" タグをつけることをお忘れなく。 https://stackoverflow.com/questions/ask?tags=griddb