
機械学習における任意のモデルの出力の品質は、その入力データと同じ程度にしかなりません。アルゴリズムを作成する際には、特定のデータを自由に与えられることが非常に重要になります。データは様々な基準を満たす必要があり、そのためにデータベースを使います。しかし、どんなデータベースでも良いというわけではなく、大量のデータを扱うには高速なデータ処理が必要となります。そこで、GridDB の登場です。GridDBは速度を追求した設計と、計算上有利なコンテナ スキーマや階層構造を使って複雑な構造を表現する可能性を備えています。
これから、phpとそのphp-ai/php-mlライブラリを使用してGridDBと接続した基本的な例を見てみましょう。もちろん、PythonやGridDBがコネクタを提供している他の言語を使用することも可能です。
環境設定, PHP & GridDB
最初の設定です。php v7.2以降、php-ai/php-mlライブラリ、GridDBサーバが必要です。
ローカルのワークステーションと同じように サーバーにもphp を設定し、データベース サーバーとクライアントの両方が共有言語と相互作用できるようにします。
CentOS上では、phpを次のように簡単にインストールすることができます。
yum install php7
yum install php7-devel
composer を使用して ml ライブラリを追加します。
composer require php-ai/php-ml
php-mbstring 拡張モジュールやより一般的なライブラリが必要な場合はこちらからインストールすることができます。
yum install php-mbstring yum groupinstall 'Development Tools'
GridDBのインストールには様々な方法があります。詳しい説明は
最も簡単なインストール方法は、dockerを使用することです。
docker pull griddbnet/griddb
以下のようにデータベースの準備ができたかどうかを確認してください。
su - gsadm gs_stat -u "user"/"password"
( “user” と “password” はあなたが設定したものに置き換えてください。)
コンテナの作成
データベースを立ち上げて実行したら、次にデータベース コンテナとそれに関連するレイアウト スキーマを作成しましょう。
include('griddb_php_client.php');
$factory = StoreFactory::get_default();
$container_name = "income_ml";
$gridstore = $factory->get_store(
array(
// Connection specifications.
"notification_address" => $argv[1],
"notification_port" => $argv[2],
"cluster_name" => $argv[3],
"user" => $argv[4],
"password" => $argv[5]
)
);
// Connect to the target container (create it if does not exist).
$gridstore->get_container("container_name");
// Place a collection into the container.
$collection = $gridstore->put_container($container_name,
array(
// Definition of the container layout scheme.
array("id" => GS_TYPE_INTEGER),
array("age" => GS_TYPE_INTEGER),
array("workclass" => GS_TYPE_STRING),
array("fnlwgt" => GS_TYPE_INTEGER),
array("education" => GS_TYPE_STRING),
array("family" => GS_TYPE_STRING),
array("occupation" => GS_TYPE_STRING),
array("relationship" => GS_TYPE_STRING),
array("race" => GS_TYPE_STRING),
array("gender" => GS_TYPE_STRING),
array("nation" => GS_TYPE_STRING),
array("income_status" => GS_TYPE_STRING),
),
GS_CONTAINER_COLLECTION);
データの挿入
コンテナが作成されたので、次にコンテナを埋めていきましょう。ここでは、最もシンプルで変更可能なメソッドの一つを使用します。GridDBのAPIをphp関数で呼び出し、対応する配列から値を渡します。
このプロジェクトを複製しやすい範囲にとどめるため、比較的小さなデータセットを選びます。 とはいえ、はるかに大きなモデルを訓練するために利用できるハードウェアと時間、そして GridDB の優れたスケーラビリティがあれば、かなり多くのデータを簡単に利用することができます。
for($i = 0; $i < $row_count; $i++){
// Creation of a new row.
$row_list[$i] = $collection->create_row();
// Setting the fields of the row.
$row_list[$i]->set_field_by_integer(0, $i);
$row_list[$i]->set_field_by_integer(1, $age_list[$i]);
$row_list[$i]->set_field_by_string(2, $emp_list[$i]);
$row_list[$i]->set_field_by_integer(3, $wgt_list[$i]);
$row_list[$i]->set_field_by_string(4, $edc_list[$i]);
$row_list[$i]->set_field_by_string(5, $fam_list[$i]);
$row_list[$i]->set_field_by_string(6, $job_list[$i]);
$row_list[$i]->set_field_by_string(7, $rel_list[$i]);
$row_list[$i]->set_field_by_string(8, $rce_list[$i]);
$row_list[$i]->set_field_by_string(9, $gnd_list[$i]);
$row_list[$i]->set_field_by_string(10, $cid_list[$i]);
$row_list[$i]->set_field_by_string(11, $inc_list[$i]);
// Place the new row in the container.
$collection->put_row($row_list[$i]);
}
データの修正
もし後からデータの一部が不要となった場合、簡単に削除することができます。同様に、データが欠けていることが分かった場合も、後から追加することができます。
カラムを削除したり追加したりするには、スキーマを更新した状態で再度put_container関数を呼び出し、最後の引数に “true “をセットして更新します。
下の図は、不要なカラムを削除したものです(上の図と比較すると、fnlwgt カラムが削除されています)。
$collection = $gridstore->put_container($containerName,
array(
// Definition of the new contianer layout scheme.
array("id" => GS_TYPE_INTEGER),
array("age" => GS_TYPE_INTEGER),
array("workclass" => GS_TYPE_STRING),
array("education" => GS_TYPE_STRING),
array("familiy" => GS_TYPE_STRING),
array("occupation" => GS_TYPE_STRING),
array("relationship" => GS_TYPE_STRING),
array("race" => GS_TYPE_STRING),
array("gender" => GS_TYPE_STRING),
array("nation" => GS_TYPE_STRING),
array("income_status" => GS_TYPE_STRING),
),
GS_CONTAINER_COLLECTION, true);
注意点として、カラムのタイプを変更することはできません。その代わりに、異なる名前の新しいカラムを作成してください。タイプの変更をサポートしていないのは、タイプを切り替えることでデータベースは強制的にタイプ変換を実行することになり、エラーが発生しやすいためです。
「データの挿入」で示したのと同じ方法で、行を追加で挿入することができます。
行を削除するには、まずその行を取得する必要があります。先ほどと同様に、まずコンテナを選択し、次に適切なTQLクエリを指定して行を取得します。クエリとフェッチコマンドを実行する前にauto-commitをfalseに設定しておく必要があるので注意してください。その後、選択された行が削除されます。この方法で、不完全なデータ エントリを持つすべての行を削除します。
$container_name = "income_ml";
$query_string = "SELECT * WHERE workclass='?' OR education='?' OR familiy='?'
OR occupation='?' OR relationship='?' OR race='?' OR gender='?' OR nation='?'";
$collection = $gridstore->get_container($container_name);
$collection->set_auto_commit(false);
$query = $collection->query($query_string);
$rows = $query->fetch($update);
while ($rows->has_next()) {
// Select a row.
$row = $collection->create_row();
$rows->get_next($row);
// Delete the selected row.
$rows->delete_current();
}
$collection->commit();
検索する代わりに行キーを指定することで行を削除することもできます。詳細は GridDBのドキュメントを参照してください。
データバイアスのない機械学習
GridDBを使うことで、データベース内のデータの概要を簡単に把握することができます。また、php用に存在する多くのチャートライブラリの一つを使用することで、可視化して理解することができます。このブログに掲載しているすべてのチャートのソースコードは、こちらにあります。さらに、FusionChartsのウェブサイトから、これらのチャートを作成するために必要なチャートライブラリをダウンロードし、関連するドキュメントを読むことができます。
このようなグラフを使ってより深く見てみることで、データが様々な意味で偏っていることが分かります。 例えば以下のグラフからは、特に、女性で高収入の人がかなり少ないと言えるでしょう。
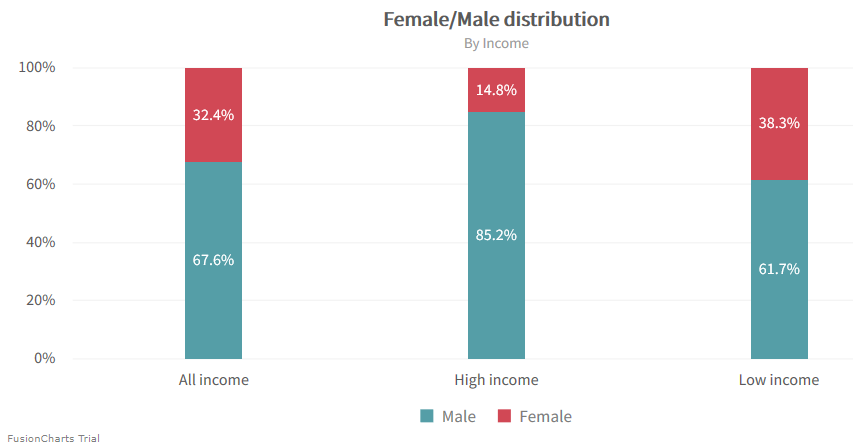
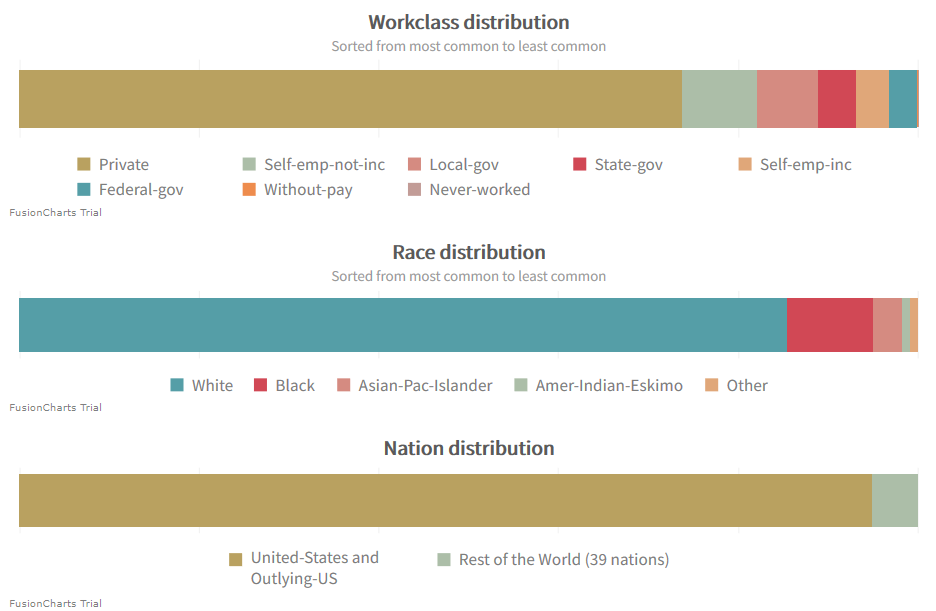
その他の問題のあるデータ・ポイントは、業種、人種、国籍です。これらはいずれも、大きな割合を占めるサブグループがあるという特徴があります。
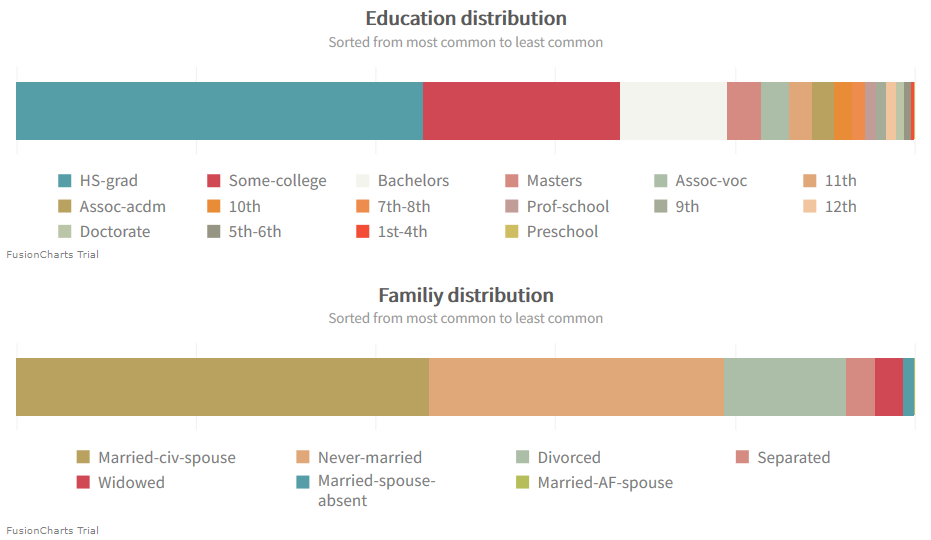
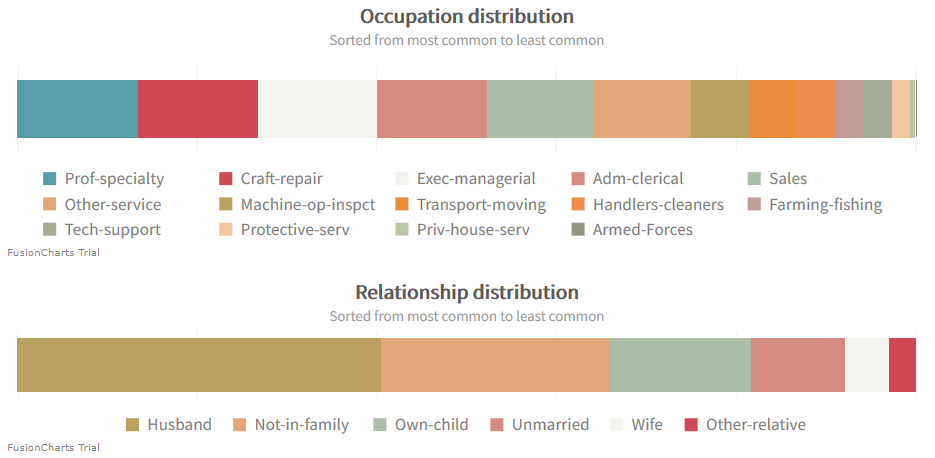
学歴、家族、職業、人間関係に関しては、より良い分布が見られます。
バイアスの調整
GridDBとTQLを利用して、機械学習アルゴリズムに投入するデータの分布を調整することができます。例えば、女性のデータポイントと男性のデータポイントのバランスを取りたいとします。そうするには$train_query_limit変数を定義し、クエリ要求を満たすいくつの行がフェッチされるかを指定します。これにより、両方の性別のデータ ポイントを同じ量だけ取得できるようになります。
$query_list[0] = "SELECT * WHERE (gender='Male') LIMIT " . $train_query_limit;
$query_list[1] = "SELECT * WHERE (gender='Female') LIMIT" . $train_query_limit;
データを取得するのは、データベースにデータを書き込むのと似ています。カラムはスキーマで設定されたのと同じ順番です。
データを取得する前に、php.ini の設定によっては、PHP のメモリ制限を増やす必要があるかもしれません。利用可能なメモリをより大きな値に設定するか、メモリ制限をなくすことも可能です。機械学習アルゴリズムでは後にさらに多くのメモリを必要とすることを考慮して、以下のコードでは制限を設けないように指定しています。
// Remove the memory limit temporarily.
ini_set('memory_limit', '-1');
// Loop through all rows returned by the query.
while ($rows->has_next()) {
// Update row.
$rows->get_next($row);
// Write fields into temporary variables.
$age = $row->get_field_as_integer(1);
$employement = $row->get_field_as_string(2);
$education = $row->get_field_as_string(3);
$family = $row->get_field_as_string(4);
$occupation = $row->get_field_as_string(5);
$relationship = $row->get_field_as_string(6);
$race = $row->get_field_as_string(7);
$gender = $row->get_field_as_string(8);
$country = $row->get_field_as_string(9);
$income_status = $row->get_field_as_string(10);
// Write to array.
...
}
データポイントを2つの配列に収集します。$samplesと呼ばれる入力データのための配列と、$targetsと呼ばれる期待される結果のための配列があり、機械学習アルゴリズムに送り込むことができます。
トレーニングと予測
ここで紹介する機械学習アルゴリズムはサポートベクターマシンで、ライブラリではSVC(サポートベクター分類)として参照されています。このブログではRBFカーネルを使用します。他のカーネルやアルゴリズムを使用する場合はphp-ai/php-mlライブラリにあります。
アルゴリズムがデータを理解するためには、データを特徴量の配列として表す必要があります。そのために、生データのベクトル化とtf-idf変換を行います。その後、トレーニング用データセットの一部を、モデルの性能を確かめるためのテスト用データセットとして別に保存しておきます。もし性能が十分でない場合は、アルゴリズム変数を調整します。
// Tokenizing the raw data.
$vectorizer = new TokenCountVectorizer(new WordTokenizer());
$vectorizer->fit($samples);
$vectorizer->transform($samples);
$tf_idf_transformer = new TfIdfTransformer();
$tf_idf_transformer->fit($samples);
$tf_idf_transformer->transform($samples);
// Setting up the train and test datasets.
$dataset = new ArrayDataset($samples, $targets);
$random_split = new StratifiedRandomSplit($dataset, 0.1);
// Selection of the algorithm and its kernel.
$classifier = new SVC(
Kernel::RBF, // kernel
1.0, // cost
3, // degree
null, // gamma
0.0, // coef 0
0.001, // tolerance
100, // cache size
true, // use shrinking
false // generate probability estimates
);
// Train and prediction.
$classifier->train($random_split->getTrainSamples(), $random_split->getTrainLabels());
$predicted_labels = $classifier->predict($random_split->getTestSamples());
// Accuracy score:
$accuracy = Accuracy::score($predicted_labels, $random_split->getTestLabels());
機械学習アルゴリズムの検証
テストデータセットで精度の高いスコアが出たら、次に検証用データセットでモデルを確認します。検証用データセットは、GridDBから追加のデータポイントを取得することで簡単に作成することができます。検証用データセットのデータポイントは、モデルにとって未知のものでなければならないため、選択したクエリが既に使用されているデータポイントを返さないようにするよう気を付けてください。
これは、例えばGridDBのインデックス、行キー、またはOFFSETキーワードなどで実現することができます。
// Train/Test dataset queries:
"SELECT * WHERE (gender='Male') LIMIT " . $train_query_limit;
"SELECT * WHERE (gender='Female') LIMIT " . $train_query_limit;
// Validation dataset queries:
"SELECT * WHERE (gender='Male') OFFSET " . $train_query_limit . " LIMIT " . $validation_query_limit;
"SELECT * WHERE (gender='Female') OFFSET " . $train_query_limit . " LIMIT " . $validation_query_limit;
トレーニング用データから作成した特徴量配列で変換することで、モデルは新しいデータセットを理解することができます。
// Apply the transformations to the validation data.
$vectorizer->transform($validation_samples);
$tf_idf_transformer->transform($validation_samples);
// Calculate accuracy score for the validation data:
$validation_predicted_labels = $classifier->predict($validation_samples);
$accuracy = Accuracy::score($validation_targets, $validation_predicted_labels;
モデルの検証
作成したモデルについてさらに詳しく確かめるために、他にもさまざまな検証用データセットを用いてテストしてみましょう。例えば、学歴によってグループ化された特定の科目を用いて検証することができます。この検証によって、モデルの予測能力や、所得に関連した特性の重要性についても分かることがあるかもしれません。
"SELECT * WHERE (education='HS-grad') LIMIT " . $validation_query_limit;
"SELECT * WHERE (education='Some-college') LIMIT " . $validation_query_limit;
"SELECT * WHERE (education='Bachelor') LIMIT " . $validation_query_limit;
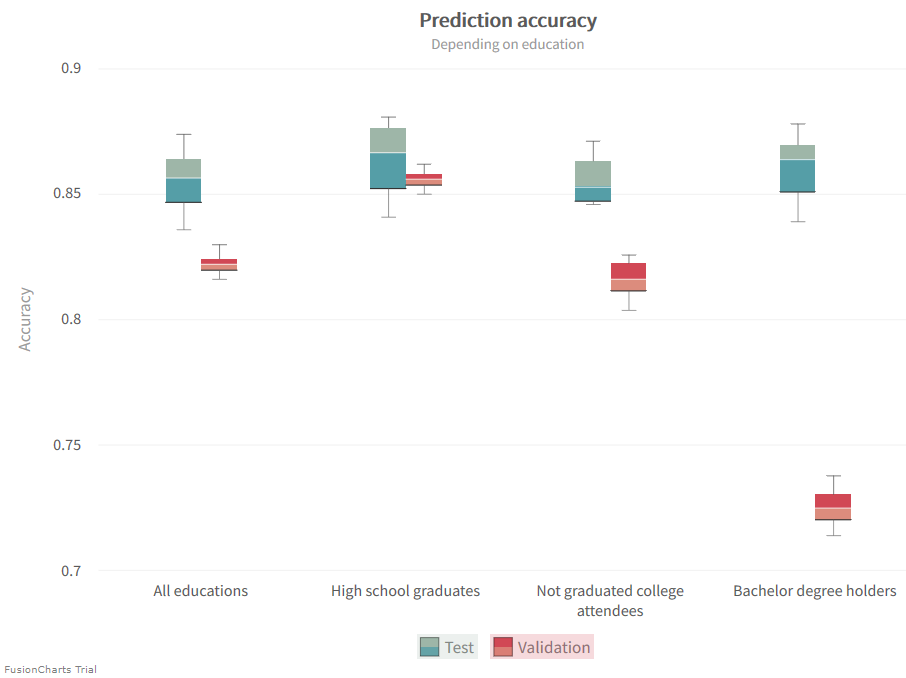
下のグラフには、達成された精度が示されています。テストの精度はほぼ一定ですが、検証の精度には大きなばらつきがあることがわかります。このことは、モデルが実際に学歴によって異なる分類を選択していることを示しています。すべての学歴を含む一般的なデータセットの精度を見てみると、テスト用データセットと検証用データセットの実際の違いがよく分かります。後者の検証用データセットでは、予測がそれほど正確ではありません。ベクタライザは,特徴配列を構築する際に,より大きなトレーニング用データセットの一部としてテスト用データセットを考慮に入れています。しかし、ベクタライザは検証用データセットの知識を持っていないので、必ずしもそれを完全に特徴配列自体にマッピングすることができません。この精度のギャップを考慮して、バイアスと分散を調整しましょう。
このモデルでは、高卒者のデータでは特に精度が高く、大卒者のデータでは精度が低くなりました。大卒者の場合は、指標としての学歴が過大評価されている可能性があり、特定の学歴に関して所得が高いか低いかがほぼ同程度になる場合に精度が落ちてしまいます。
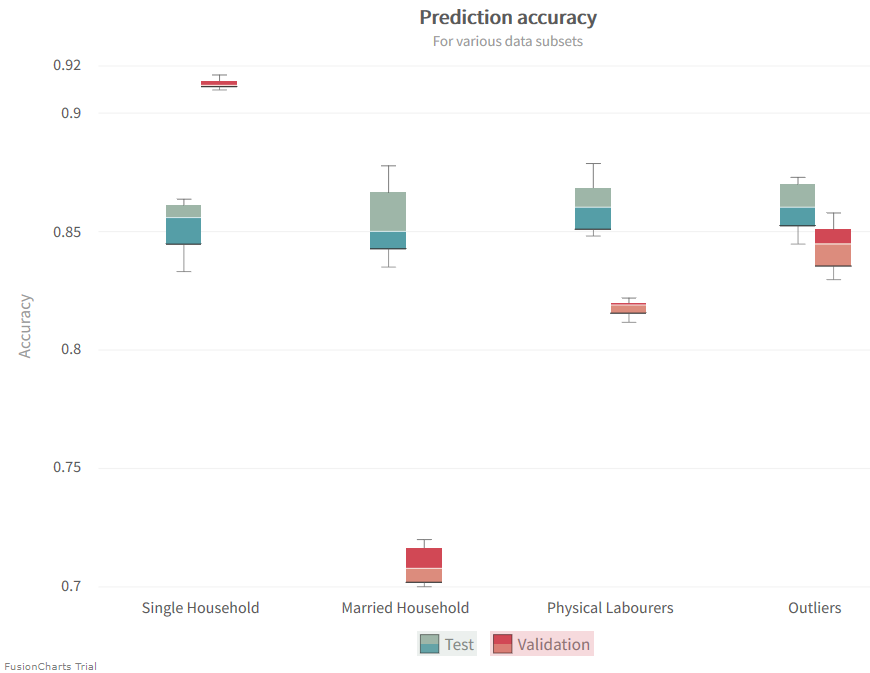
その他のデータサブセット
さて、他にどんなことが学べるのかについて、より複雑なデータベースクエリの助けを借りて見てみましょう。ここでは、基本的にいくつかのデータサブセットをグループ化します。これらをグループ化することは、前に実行した特定の選択と同様に役立つことがあります。
// Married households:
"SELECT * WHERE (familiy='Married-civ-spouse' OR familiy='Married-AF-spouse') LIMIT " . $validation_query_limit;
// Single households:
"SELECT * WHERE (familiy='Divorced' OR familiy='Never-married' OR familiy='Separated' OR familiy='Widowed') LIMIT " . $validation_query_limit;
// Physical laborers:
"SELECT * WHERE (occupation='Craft-repair' OR occupation='Handlers-cleaners' OR occupation='Farming-fishing' OR occupation='Priv-house-serv') LIMIT " . $validation_query_limit;
// Outliers of the dataset:
"SELECT * WHERE (NOT race='White' AND NOT nation='United-States' AND NOT nation='Outlying-US(Guam-USVI-etc)') LIMIT " . $validation_query_limit;
機械学習ではデータが違いを生む
If you have any questions about the blog, please create a Stack Overflow post here https://stackoverflow.com/questions/ask?tags=griddb .
Make sure that you use the “griddb” tag so our engineers can quickly reply to your questions.