はじめに フィッシングサイトとは何か?
好奇心のせいで、個人情報が悪者に流出してしまう危険にあうことがあります。知り合いから送られてきたメールにあるリンクを、ついクリックしそうになったことはありませんか?それはとても危険なことです。ハッカーは情報収集の方法をたくさん持っており、ソーシャルエンジニアリングによって信頼を得て、普通は単なる知り合いに頼まれてもしないはずのことをあなたにさせてしまう方法を熟知しているのですが、その一つがリンクをクリックさせることなのです。
フィッシングとは、ハッカーがパスワード、電子メール、名前などの情報を収集するために用いられる手法です。このプロセスが成功すると、あなたのデバイスは悪用されやすい状態になってしまいます。
フィッシングはどのように行われるのでしょうか?ハッカーは、Facebookがパスワードの変更を求めるページや、ログインを求めるページを複製します。ハッカーはバックエンドに、ユーザーが入力した内容を自分たちがアクセスできるデータベースに保存するように設定します。パスワードを変更する際には、新しいパスワードだけでなく、古いパスワードも入力することになります。しばらくして、おそらくWhatsAppで信頼を得た後、ハッカーはツールを使ってリンクを通常のFacebookリンクの形式にして、興味深いキャプションを付けてテストケースであるあなたに送ります。あなたはそのリンクをクリックして情報を入力し、ハッカーはその情報にアクセスします。次にFacebookにログインすると、あなたは自分のアカウントにアクセスできなくなっていることに気づくでしょう。これがフィッシングの仕組みです。
危険なウェブサイトを手動で検出する
今や、フィッシング・サイトを検知するツールを使うことは非常に重要です。しかし、フィッシング・リンクを見分けることができるだけでも安全性が高まるかもしれません。以下に、リンクに見られる欠点を挙げておきますので、怪しいウェブサイトかどうかを判断する際の参考にしてください。
- リンクが短くなっている
- リンクのスペルが間違っている
- リンク先に実在しない文字がある(キリル文字を使用している)
- 前に聞いたことがないウェブサイトであったり、ランク付けが低いものである
- リンクが非常に長く、合法的なリンクとオリジナルでないリンクの組み合わせを持っている
また、ウェブサイトにアクセスした後にも、フィッシングサイトを見分けるためのヒントがあります。
- ウェブサイト上でマウスの右クリックボタンが無効になっている
- マウスの右クリックボタンが無効になっていて、ページのソースを見ることができない
- ポップアップウィンドウ
前提条件
- このチュートリアルに必要なツールは以下の通りです。私はCentOSのコンピュータを使用しています。
- Python 3.8またはPython 3.9。最新版のPythonは、ウェブサイトから入手できます。
- Jupyter Notebook(IDLE for Pythonをすでに持っている場合はオプション)。Jupyter Notebookは、Pythonのコードを書くための環境で、コードやテキストを書くのに適したセルが用意されています。https://www.anaconda.org から Anaconda3 をダウンロードすると、Notebook を入手することができ、Jupyter Notebook や Spyder などのパッケージがPC にインストールされます。
データ
今回のモデルに使用するデータセットは、こちらのカリフォルニア大学アーバイン校(UCI)が提供する公式データセットウェブサイトです。このデータセットには、ウェブサイトを正規のものと偽のものに分類するのに役立つ多くの数値的特徴が含まれています。
データセットには2456個のインスタンスと30個の属性が含まれています。データを分析しようとするときには、常に欠損値をチェックするのが良い方法ですが、ウェブサイトには欠損値がないと書かれています。UCIのデータセットページにアクセスして、データセットを直接ダウンロードすることができます。
すべての機能を見るには、こちらからPhishing Website Features.docxファイルをダウンロードしてください。
ARFFファイルをCSVに変換する
UCIのウェブサイトからダウンロードしたデータセットはARFFファイルなので、Pythonのコードで使用できるようにCSVファイルに変換する必要があります。ダウンロードしたARFFデータセットファイルが、Pythonコードの入ったフォルダと同じ場所にあることを確認してください。
import glob as gb # This builtin module would allow us to select only the file with .arff extension
files = [f for f in gb.glob("*.arff")] # We are using "files" because this selects all the files with that extension
# This function would convert the ARFF file to CSV file
def convert(lines):
header = ""
file_content = []
data = not True
for line in lines:
if not data:
if "@attribute" in line:
attributes = line.split()
columnName = attributes[attributes.index("@attribute")+1]
header = header + columnName + ","
elif "@data" in line:
data = True
header = header[:-1]
header += "n"
file_content.append(header)
else:
file_content.append(line)
return file_content
for file in files:
with open(file, "r") as inp:
lines = inp.readlines()
output = convert(lines)
with open("dataset" + ".csv", "w") as out:
out.writelines(output)
GridDB Pythonクライアントを使用する
https://griddb.net/en/downloads/ にアクセスして GridDB Server をダウンロードし、ウェブサイトのインストール手順に従ってインストールしてください。なお、SWIGとC_ClientがインストールされていないとPythonのGridDB Clientをインストールすることができません。Windowsの場合はこちら、CentOSやUbuntuなどの利用可能なOSの場合はこちらにアクセスしてダウンロードしてください。
Python クライアントを使用する前に、事前にサーバーを起動して、ホスト、ポート、クラスター名、ユーザー名をメモしておいてください。
If you’re using Jupyter notebook, you may need to follow the instructions here to get GridDB running on your notebook. Jupyter notebookを使用している場合、Notebook上でGridDBを動作させるには、こちらの手順に従う必要があるかもしれません。
私たちはデータのコンテナとしてGridDBを使用します。空の引用符があるところに、あなたのGridDBサーバーの詳細を記入してください。
import griddb_python as griddb
factory = griddb.StoreFactory.get_instance()
your_host = ""
your_port = ""
your_cluster_name = ""
your_username = ""
your_password = ""
try:
gridstore = factory.get_store(host=your_host, port=your_port,
cluster_name=your_cluster_name, username=your_username,
password=your_password)
conInfo = griddb.ContainerInfo("Phishing Websites",
[
["having_IP_Address", griddb.Type.INTEGER],
["URL_Length", griddb.Type.INTEGER],
["Shortining_Service", griddb.Type.INTEGER],
["having_At_Symbol", griddb.Type.INTEGER],
["double_slash_redirecting", griddb.Type.INTEGER],
["Prefix_Suffix", griddb.Type.INTEGER],
["having_Sub_Domain", griddb.Type.INTEGER],
["SSLfinal_State", griddb.Type.INTEGER],
["Domain_registeration_length", griddb.Type.INTEGER],
["Favicon", griddb.Type.INTEGER],
["port", griddb.Type.INTEGER],
["HTTPS_token", griddb.Type.INTEGER],
["Request_URL", griddb.Type.INTEGER],
["URL_of_Anchor", griddb.Type.INTEGER],
["Links_in_tags", griddb.Type.INTEGER],
["SFH", griddb.Type.INTEGER],
["Submitting_to_email", griddb.Type.INTEGER],
["Abnormal_URL", griddb.Type.INTEGER],
["Redirect", griddb.Type.INTEGER],
["on_mouseover", griddb.Type.INTEGER],
["RightClick", griddb.Type.INTEGER],
["popUpWidnow", griddb.Type.INTEGER],
["Iframe", griddb.Type.INTEGER],
["age_of_domain", griddb.Type.INTEGER],
["DNSRecord", griddb.Type.INTEGER],
["web_traffic", griddb.Type.INTEGER],
["Page_Rank", griddb.Type.INTEGER],
["Google_Index", griddb.Type.INTEGER],
["Links_pointing_to_page", griddb.Type.INTEGER],
["Statistical_report", griddb.Type.INTEGER],
["Result", griddb.Type.INTEGER],
],
griddb.ContainerType.COLLECTION, True)
cont = gridstore.put_container(conInfo)
data = pd.read_csv("dataset.csv")
#Add data
for i in range(len(data)):
ret = cont.put(data.iloc[i, :])
print("Successfully added the data")
except griddb.GSException as e:
for i in range(e.get_error_stack_size()):
print("[", i, "]")
print(e.get_error_code(i))
print(e.get_location(i))
print(e.get_message(i))
import pandas as pd
dataset = pd.read_csv("dataset.csv")
データセットの先頭を印刷する(データの上位5レコードを表示する)
このデータセットについて理解しておくべきことは,すべての特徴が数値であるため,データをエンコードする必要がないということです。また、データセットには 1, -1, 0 という3つの値しかありませんが、これらはデータの真偽を表す形式に過ぎません。値が1であれば、その特徴についての条件(属性・列名)は真であり、値が0または-1であれば偽であるといえます。例えば、popUpWindow列に1の値があれば、popUpWindowがあったことを意味します。これらの値はすべて結果を決定し、Result列には1と-1の値があり、それぞれPhishing WebsiteとNot a Phishing Websiteを表しています。
Python IDLEを使用している場合は、print(dataset.head())を使用してください。
""" You can also decide to show the bottom five records of the data by
typing dataset.tail()"""
dataset.head()
dataset.shape # Number of rows and columns
(11055, 31)
dataset.describe() # Describing the data to gain insights from it
結果を予測するモデルを構築する
ここからは、Decision Trees Classifierを使用して、あるウェブサイトがフィッシングサイトであるかどうかを予測するモデルを構築します。
Decision Trees Classifierモデルを構築する
データセットには多くの列がありますが、他のすべての列の値が真である場合、最後の列のみが予測結果を表します。言い換えれば、最後の列は最初の列から最後の列までの他のすべての列に依存しており、これをDependent Featureと呼ばれます。他のすべての列はIndependent Featuresと呼ばれます。ここでは,独立特徴と従属特徴の値を格納するために、それぞれXとyという2つの変数を定義します。Xは Independent Variableと呼ばれ,yは Dependent Variableと呼ばれます。
値を選択するための構文は,data.iloc[number_of_rows_to_select, number_of_columns_to_select].valuesです。すべての行を選択しているので、Pythonではスライス演算子 : を使ってデータセットの値を最初の行から最後の行までスライスします。しかし、Xについては最後の列(結果)を除くすべての列が必要なので、最後の列を残してスライスします。yについては、最後の列だけが必要なので、スライスする必要はありません。
X = dataset.iloc[:, :-1].values
y = dataset.iloc[:, -1].values
print(X)
[[-1 1 1 ... 1 1 -1]
[ 1 1 1 ... 1 1 1]
[ 1 0 1 ... 1 0 -1]
...
[ 1 -1 1 ... 1 0 1]
[-1 -1 1 ... 1 1 1]
[-1 -1 1 ... -1 1 -1]]
print(y)
[-1 -1 -1 ... -1 -1 -1]
データセットをトレーニングセットとテストセットに分割する
from sklearn.model_selection import train_test_split as tts
X_train, X_test, y_train, y_test = tts(X, y, test_size=0.30, random_state=0)
データの70%を学習させ、残りの30%をフィッシングサイトかどうかを予測させます。したがって、機械学習によって約1719のウェブサイトを学習し、約739のウェブサイトを予測していることになります。
データを可視化する
GridDBはデータ可視化機能も備えており、こちらの説明に従って、GridDBとPythonのmatplotlibを使ってデータを可視化します。ここではSeabornを使用していますが、データセットには多数の属性があるため、可視化には非常に時間がかかります。
import seaborn as sns
sns.pairplot(dataset)
<seaborn.axisgrid.PairGrid at 0xeced8d0>
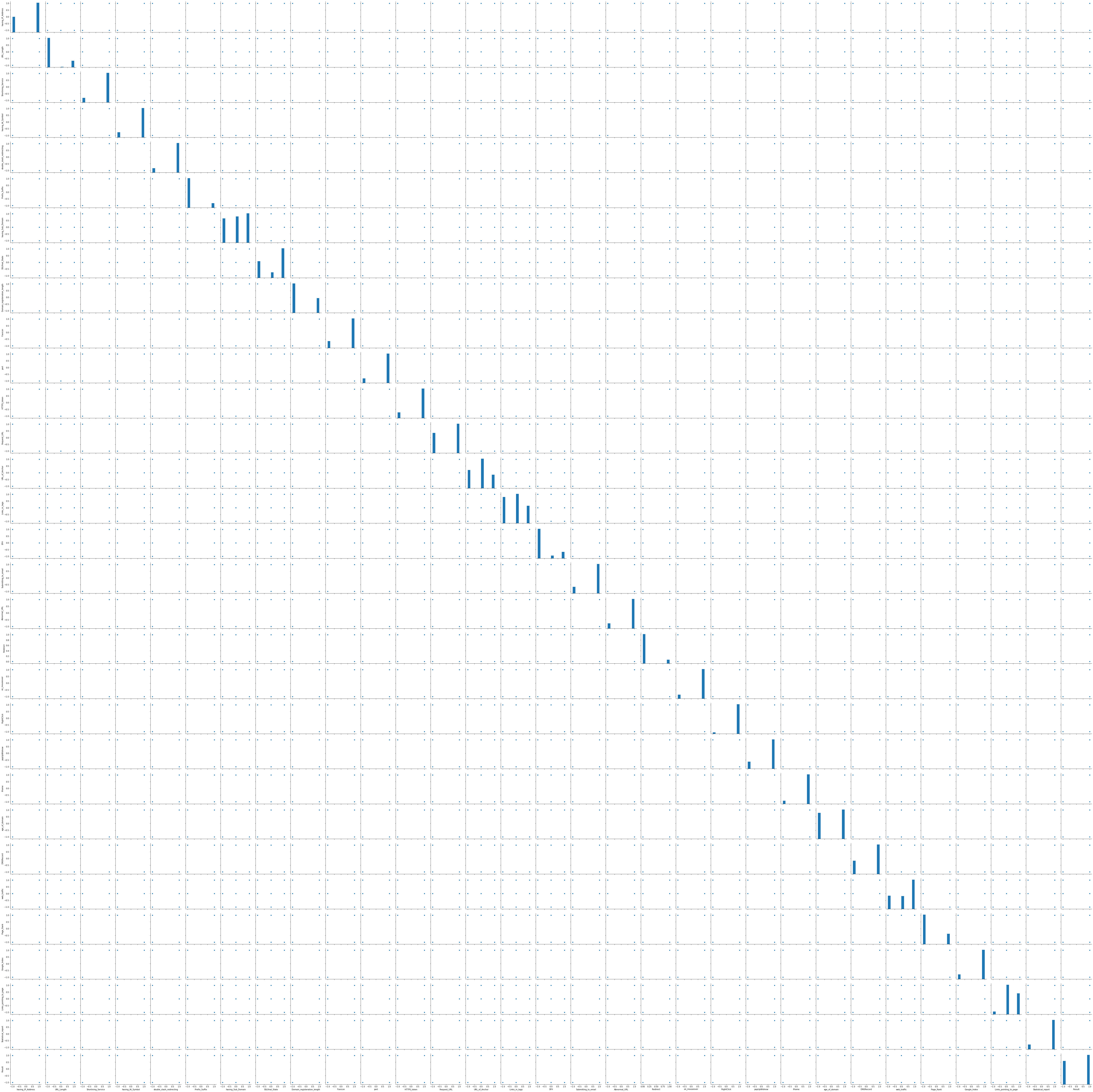
上記の可視化結果から、age_of_domain列がResult列と相関関係にあることがわかります。
フィッシングサイトからのリンクかどうかを分類するモデルを構築する
from sklearn.tree import DecisionTreeClassifier
dtClassifier = DecisionTreeClassifier()
dtClassifier.fit(X_train, y_train)
DecisionTreeClassifier(class_weight=None, criterion='gini', max_depth=None,
max_features=None, max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, presort=False,
random_state=None, splitter='best')
dty_pred = dtClassifier.predict(X_test)
print(dty_pred)
[-1 -1 -1 ... -1 1 1]
from sklearn.metrics import confusion_matrix
cMatrix = confusion_matrix(y_test, dty_pred)
print(cMatrix)
[[1426 72]
[ 48 1771]]
# Accuracy of the model
dtacc = dtClassifier.score(X_test, y_test)
dtacc *= 100
dtaccu = round(dtacc, 2)
dtaccuracy = str(dtaccu)+"%"
print(
f"""
The Accuracy of our model, using the Decision Tree Classifier
{dtaccuracy}
"""
)
The Accuracy of our model, using the Decision Tree Classifier
96.38%
まとめ
このモデルの使い方の例として、ウェブサイトのURLがあり、データセットに従ってウェブサイトの特徴を最後の1つを除いてすべて記入した後、モデルを使ってそれがフィッシングサイトかどうかを予測します。
このブログを読んで、機械学習にGridDBを使用すると便利であると感じていただけたら幸いです。
If you have any questions about the blog, please create a Stack Overflow post here https://stackoverflow.com/questions/ask?tags=griddb .
Make sure that you use the “griddb” tag so our engineers can quickly reply to your questions.