
隣接する多くの産業にまたがる自動車産業は、世界経済の柱であり、マクロ経済の成長と安定、そして先進国と発展途上国の技術進歩に大きく貢献しています。
世界の自動車産業は活況を呈しており、新しい変化をもたらすために、新しい電気自動車の生産に目を向けています。しかし、ここでは新しい発明や自動車についてではなく、化石燃料を使用した中古車市場に対してどのような要因が影響を及ぼしているのかを考察してみたいと思います。
GridDBは、拡張性と最適化に優れたインメモリNoSQLデータベースで、特に時系列データベースにおいて並列処理による性能向上と効率化が可能なため、中古車販売に影響を与える要因の分析に使用します。GridDBのNode.jpクライアントを利用することで、GridDBとNode.jsを接続し、リアルタイムにデータのインポートやエクスポートを行うことが可能です。さらに、Danfo.JSライブラリを使用して、データ分析用のデータフレームを操作し、興味深いビジュアライゼーションやデータの発見を実現します。
csv形式のデータセットはKaggleから入手したものです。このデータが何を表しているかは、後ほど「データ分析」の項で紹介します。
GridDBにデータセットを書き出す
はじめに、GridDB ノードモジュール griddb_node、danfojs-node、csv-parser を初期化します。griddb_nodeはGridDB上で作業できるようにノードを起動し、danfojs-nodeはデータ分析で使用するdfdという変数を初期化し、csv-parserは以下のようなcsvファイルを読み込んでデータセットをGridDBにアップロードしてくれます。
var griddb = require('griddb_node');
const dfd = require("danfojs-node")
const csv = require('csv-parser');
const fs = require('fs');
fs.createReadStream('./Dataset/UserCarData.csv')
.pipe(csv())
.on('data', (row) => {
lst.push(row);
console.log(lst);
})変数の初期化に続いて、GridDB コンテナを生成し、データベーススキーマを作成します。コンテナ内では、データセット内のカラムのデータ型を定義する必要があります。このコンテナを利用して、格納されているデータにアクセスし、GridDB へのデータ挿入を完了します。
const conInfo = new griddb.ContainerInfo({
'name': "usedcaranalysis",
'columnInfoList': [
["name", griddb.Type.STRING],
["Sales_ID", griddb.Type.INTEGER],
["name", griddb.Type.STRING],
["year", griddb.Type.INTEGER],
["selling_price", griddb.Type.INTEGER],
["km_driven", griddb.Type.INTEGER],
["Region", griddb.Type.STRING],
["State or Province", griddb.Type.STRING],
["City", griddb.Type.STRING],
["fuel", griddb.Type.STRING],
["seller_type", griddb.Type.STRING],
["transmission", griddb.Type.STRING],
["owner", griddb.Type.STRING],
["mileage", griddb.Type.DOUBLE],
["engine", griddb.Type.INTEGER],
["max_power", griddb.Type.DOUBLE],
["torque", griddb.Type.STRING],
["seats", griddb.Type.INTEGER],
["sold", griddb.Type.STRING]
],
'type': griddb.ContainerType.COLLECTION, 'rowKey': true
});
// Inserting Data into GridDB
for(let i=0;i<lst.length;i++){
store.putContainer(conInfo, false)
.then(cont => {
container = cont;
return container.createIndex({ 'columnName': 'name', 'indexType': griddb.IndexType.DEFAULT });
})
.then(() => {
idx++;
container.setAutoCommit(false);
return container.put([String(idx), lst[i]['Sales_ID'],lst[i]["name"],lst[i]["year"],lst[i]["selling_price"],lst[i]["km_driven"],lst[i]["Region"],lst[i]["State or Province"],lst[i]["City"],lst[i]["fuel"],lst[i]["seller_type"],lst[i]["transmission"],lst[i]["owner"],lst[i]["mileage"],lst[i]["engine"],lst[i]["max_power"],lst[i]["torque"],lst[i]["seats"],lst[i]["sold"]]);
})
.then(() => {
return container.commit();
})
.catch(err => {
if (err.constructor.name == "GSException") {
for (var i = 0; i < err.getErrorStackSize(); i++) {
console.log("[", i, "]");
console.log(err.getErrorCode(i));
console.log(err.getMessage(i));
}
} else {
console.log(err);
}
});
}GridDBからデータセットを読み出す
すでにコンテナ内にすべてのデータが保存されているので、あとはGridDBのSQLライクな問い合わせ言語であるTQLを使ってデータを取得するだけです。そこで、まず、obtained_dataという名前で、取得したデータを格納するコンテナを構築します。次に、query というカラムオーダーで行を抽出し、df というデータフレームに保存して、データの可視化や分析を行い、データのインポートを完了します。
# Get the containers
obtained_data = gridstore.get_container("usedcaranalysis")
# Fetch all rows - language_tag_container
query = obtained_data.query("select *")
# Creating Data Frame variable
let df = await dfd.readCSV("./out.csv")データ分析
データ分析を始めるには、最も基本的な手順から始めるのが良いです。まずはデータセットの列とそれらが表すもの、そして行と列の総数に注目します。
- Sales_ID : 販売時に付与される固有の識別番号
- name : 自動車を製造した会社名
- year : 販売された車のモデルイヤー
- selling_price : 車の販売価格
- km_driven : 総走行キロメートル数
- Region : 販売が行われた州の地区
- State or Province : 売却した州または都道府県名
- City : 販売を行った都市名
- fuel : 車の燃料の種類
- seller_type : ディーラーや個人など、販売者のタイプ
- transmission : 販売した車のトランスミッションの種類
- owner : 第一、第二など、所有権の連鎖のこと
- mileage : 自動車が出す燃費をkm/lで表したもの
- engine : エンジン排気量
- max_power : 販売した車の馬力
- torque :販売車のトルク(単位:Nm)
- seats : 販売した車の乗車定員
- sold : 車の売却が成功したかどうか
console.log(df.shape)
// Output
// [ 7906, 18 ]分析するデータ(Sales_IDを除く)は7906行、18列なので、7906台の車と17種類の要因があり、中古車販売がどのように影響されるかを見ることができます。ただし、車の販売は特定の車で提供される機能によって影響を受けると仮定しているので、地理的な制約を分析から除外することにします。販売された場所によって、その車の売れ行きを判断するのは不公平だからです。そのため、「Region」、「State or Province」、「City」の列はデータ分析から除外することにします。
それを確認した上で、分析を進めていきます。
はじめに、自動車販売に最も影響を与えるいくつかの要因について、要約統計と比較してみることにします。
df.loc({columns:['year', 'selling_price', 'km_driven', 'mileage', 'engine', 'max_power', 'seats']}).describe().round(2).print()
// Output
// ╔════════════╤═══════════════════╤═══════════════════╤═══════════════════╤═══════════════════╤═══════════════════╤═══════════════════╤═══════════════════╗
// ║ │ year │ selling_price │ km_driven │ mileage │ engine │ max_power │ seats ║
// ╟────────────┼───────────────────┼───────────────────┼───────────────────┼───────────────────┼───────────────────┼───────────────────┼───────────────────╢
// ║ count │ 7906.00 │ 7.90e+03 │ 7.90e+03 │ 7906.00 │ 7906.00 │ 7906.0 │ 7906.00 ║
// ╟────────────┼───────────────────┼───────────────────┼───────────────────┼───────────────────┼───────────────────┼───────────────────│───────────────────╢
// ║ mean │ 2013.98 │ 6.50e+05 │ 6.92e+04 │ 19.42 │ 1458.70 │ 91.58 │ 5.42 ║
// ╟────────────┼───────────────────┼───────────────────┼───────────────────┼───────────────────┼───────────────────┼───────────────────│───────────────────╢
// ║ std │ 3.86 │ 8.13e+05 │ 5.67e+04 │ 4.04 │ 503.89 │ 35.74 │ 0.96 ║
// ╟────────────┼───────────────────┼───────────────────┼───────────────────┼───────────────────┼───────────────────┼───────────────────│───────────────────╢
// ║ min │ 1994.00 │ 2.99e+04 │ 1.00e+00 │ 0.00 │ 624.00 │ 32.80 │ 2.00 ║
// ╟────────────┼───────────────────┼───────────────────┼───────────────────┼───────────────────┼───────────────────┼───────────────────│───────────────────╢
// ║ median │ 2015.00 │ 4.50e+05 │ 6.00e+04 │ 19.30 │ 1248.00 │ 82.00 │ 5.00 ║
// ╟────────────┼───────────────────┼───────────────────┼───────────────────┼───────────────────┼───────────────────┼───────────────────│───────────────────╢
// ║ max │ 2020.00 │ 1.00e+07 │ 2.36e+06 │ 42.00 │ 3604.00 │ 400.00 │ 14.00 ║
// ╟────────────┼───────────────────┼───────────────────┼───────────────────┼───────────────────┼───────────────────┼───────────────────│───────────────────╢
// ║ variance │ 1.49e+01 │ 6.62e+11 │ 3.22e+09 │ 1.63e+01 │ 2.54e+09 │ 1.28e+03 │ 9.20e-01 ║
// ╚════════════╧═══════════════════╧═══════════════════╧═══════════════════╧═══════════════════╧═══════════════════╧═══════════════════╧═══════════════════╝上記のサマリーテーブルのカウントは、計算した行数と一致し、データセットにNull値がないことを示しています。その他の特徴として、車の年式が1994年から2020年までと、会社に関係なく幅広いことが分かります。更に、販売されている車の燃費が良く、平均20km/lであることが分かります。これは、人々が車を購入する際に重要視する特徴です。一方、燃費にこだわらないのであれば、3600ccまでの大きなエンジンを搭載した車が最も馬力(400馬力)を出しています。
要約すると、上記のすべての要素が特定の車の販売価格を決定します。例えば、走行距離が伸びれば、エンジンなどの修理が必要になる可能性があるため、走行距離の多い車は買いたくなくなるので、販売価格はほぼ間違いなく下がります。以下のグラフは、これらの要因のいくつかが互いにどのように関連しているかを示しています。
## Scatter Plot between engine and max_power
let cols = [...cols]
cols.pop('engine')
let data = [{
x: df['engine'].values,
y: df['max_power'].values,
type: 'scatter',
mode: 'markers'}];
let layout = {
height: 400,
width: 700,
title: 'Engine vs Max_power',
xaxis: {title: 'Engine Size'},
yaxis: {title: 'Max Power'}};
// There is no HTML element named `myDiv`, hence the plot is displayed below.
Plotly.newPlot('myDiv', data, layout); engineとmax_powerの2列をプロットすると以下のようになります。
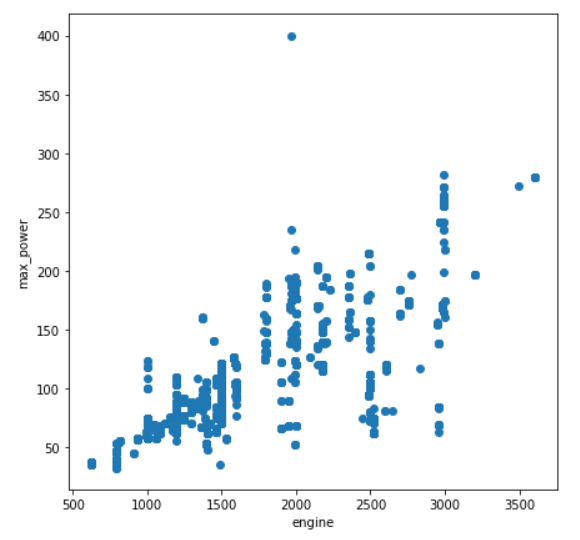
上のプロットは、2つの変数が互いに正の相関関係を持つことを示しており、これは、エンジンサイズが大きくなればなるほど、エンジンによる出力が大きくなることを意味し、理にかなっていると言えるでしょう。
## Scatter Plot between km_driven and selling_price
let cols = [...cols]
cols.pop('year')
let data = [{
x: df['km_driven'].values,
y: df['selling_price'].values,
type: 'scatter',
mode: 'markers'}];
let layout = {
height: 400,
width: 700,
title: 'Km Driven vs Selling Price',
xaxis: {title: 'Km Driven'},
yaxis: {title: 'Selling Price'}};
// There is no HTML element named `myDiv`, hence the plot is displayed below.
Plotly.newPlot('myDiv', data, layout); 次にkm_drivenとselling_priceの2列をプロットしてみましょう。
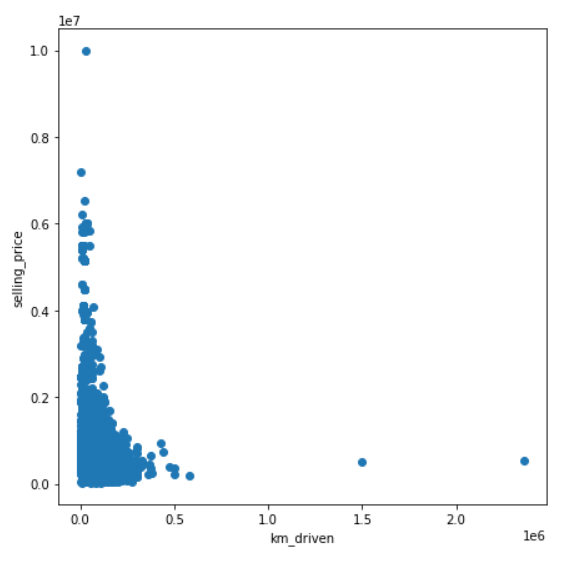
上のプロットによると、2つの変数は負の相関関係を持ち、つまり、車の走行キロ数が多いほど、その車の販売価格は低くなることが分かります。これは、人々が走行距離の少ない中古車を好むことを示しています。恐らく、走行距離の少ない車は、走行距離の多い車よりも修理の必要が少なく、高い販売価格に繋がる可能性があるからでしょう。
では棒グラフを使って、自動車メーカーの売上高を見てみましょう。
棒グラフ
## Distribution of Column Values
const { Plotly } = require('node-kernel');
let cols = df.columns
for(let i = 0; i < cols.length; i++)
{
let data = [{
x: cols[i],
y: df[cols[i]].values,
type: 'bar'}];
let layout = {
height: 400,
width: 700,
title: 'Car Manufacturers Sales' +cols[i],
xaxis: {title: cols[i]}};
// There is no HTML element named `myDiv`, hence the plot is displayed below.
Plotly.newPlot('myDiv', data, layout);
}
df.plot("plot_div").bar()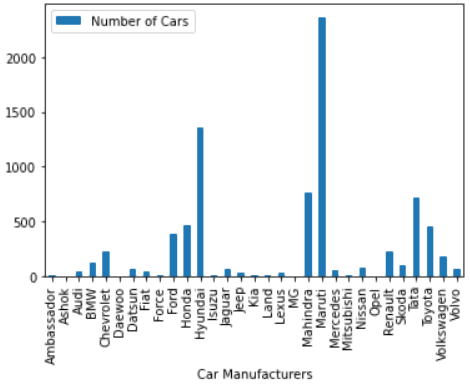
上の棒グラフによると、Marutiは競合他社を大きく上回っています。
最後に、これらの変数がどのように関連し、どれが最も中古車販売に影響を与えるかを検証します。以下の相関図がその助けとなります。
相関関係
correlogram(data)相関図は以下の通りです。
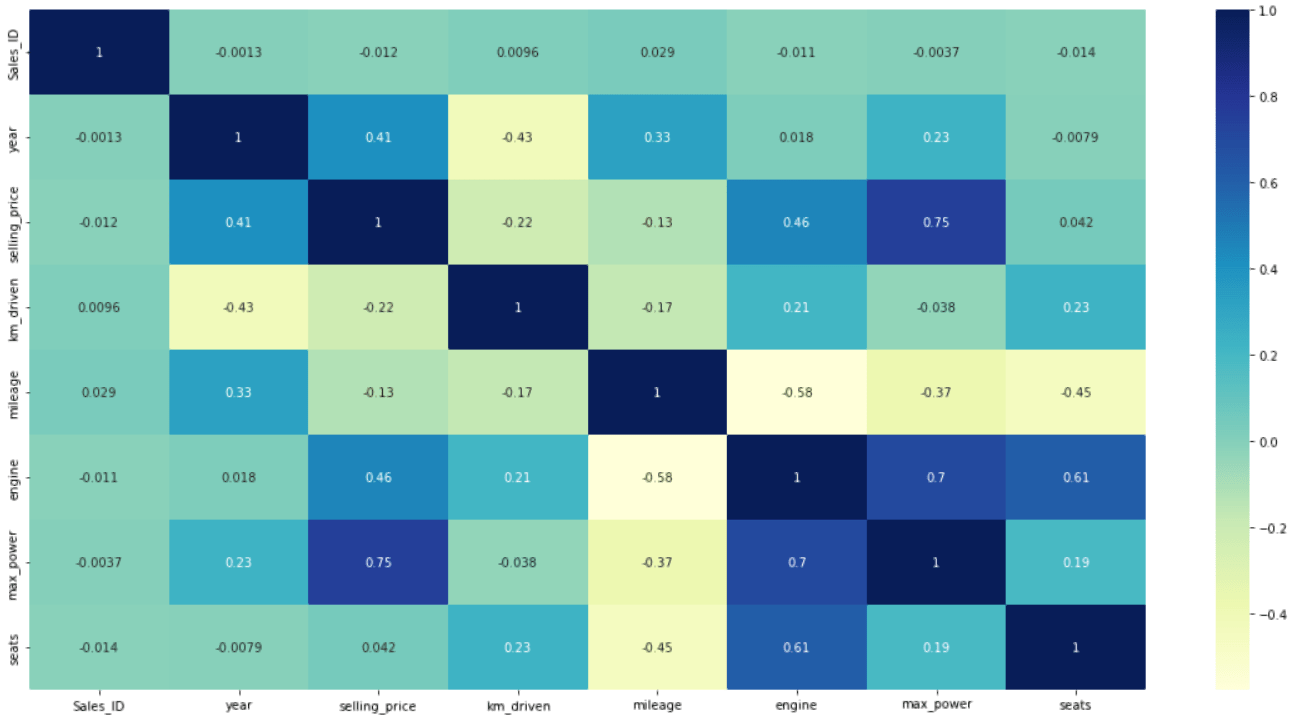
変数の値は上の相関プロットで示され、値が大きいほど、両者の関係は強いのです。例えば、相関プロットで0.5より大きい値は、0.5より小さい値よりも2つの変数がより密接に関連していることを示します。その結果、販売価格と最大価格は最も高い値(0.75)を示し、この2つが車の販売価格、ひいては車の販売台数を決定する上で最も重要な変数であることが分かります。しかし、同じ変数は当然最も強い相関を持つので、相関プロットでは上の対角線は無視します。
結論
当初は走行距離が中古車販売に最も重要な要素と考えていたが、車の最大出力と販売価格が販売に最も影響を与えることが判明しました。
最後に、今回のデータ分析には、高速なアクセスと効率的なデータの読み書き・保存を可能にするGridDBを使用しました。
If you have any questions about the blog, please create a Stack Overflow post here https://stackoverflow.com/questions/ask?tags=griddb .
Make sure that you use the “griddb” tag so our engineers can quickly reply to your questions.