In this blog post, we demonstrate how GridDB’s batch operations (multi-put and multi-query) can improve the performance of your application.
Multi Put
Batch write operations are used in many scenarios; bulk loading of previously recorded data, receiving multiple sensor readings from an edge device in one input or the purposeful caching of incoming data within the data collector to improve efficiency. Batch query operations are used to merge data from multiple containers or to perform multiple aggregations efficiently.
Single Container
In our first example, we write 10000 rows one at a time to a single container:
blob = bytearray([65, 66, 67, 68, 69, 70, 71, 72, 73, 74])
conInfo = griddb.ContainerInfo("col01",
[["name", griddb.Type.STRING],
["status", griddb.Type.BOOL],
["count", griddb.Type.LONG],
["lob", griddb.Type.BLOB]],
griddb.ContainerType.COLLECTION, True)
col = gridstore.put_container(conInfo)
i=0
start = datetime.datetime.utcnow().timestamp()
while i < 10000:
row = [str(uuid.uuid1()), False, random.randint(0, 1048576), blob]
col.put(row)
i=i+1
print("single put took "+ str(datetime.datetime.utcnow().timestamp() - start) +" seconds")However we can optimize that; instead of writing one row 10000 times, we write 1000 rows 10 times:
col = gridstore.put_container(conInfo)
i=0
start = datetime.datetime.utcnow().timestamp()
rows=[]
while i < 10000:
rows.append([str(uuid.uuid1()), False, random.randint(0, 1048576), blob])
if i != 0 and i% 1000 == 0:
col.multi_put(rows)
rows=[]
i=i+1
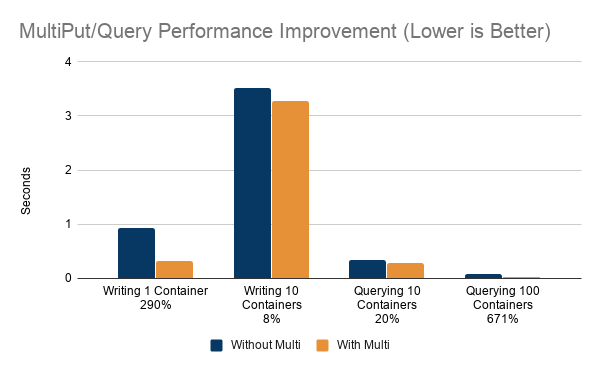
print("multiput put took "+ str(datetime.datetime.utcnow().timestamp() - start) +" seconds")The single put took 0.92 seconds while multiput put took 0.32 seconds, a 290% improvement.
Multiple Containers
In general, writing to multiple containers with multi-put is done when you're streaming platform such as Kafka and data for multiple sensors is in the collection of records fetched from Kafka in your Sink connector or Consumer application.
start = datetime.datetime.utcnow().timestamp()
for no in [0, 1, 2, 3, 4, 5, 6, 7, 8, 9 ]:
col = cols[no]
i=0
rows=[]
while i < 10000:
rows.append([str(uuid.uuid1()), False, random.randint(0, 1048576), blob])
if i != 0 and i% 1000 == 0:
col.multi_put(rows)
rows=[]
i=i+1
print("single container multi put took "+ str(datetime.datetime.utcnow().timestamp() - start) +" seconds")Now to write multiple containers with multi-put, gridstore.multi_put() where the map
start = datetime.datetime.utcnow().timestamp()
i=0
entries={}
for no in [0, 1, 2, 3, 4, 5, 6, 7, 8, 9 ]:
rows=[]
i=0
while i < 10000:
rows.append([str(uuid.uuid1()), False, random.randint(0, 1048576), blob])
i=i+1
entries["col0"+str(no)] = rows
gridstore.multi_put(entries)
print("multi container multi put took "+ str(datetime.datetime.utcnow().timestamp() - start) +" seconds")The single container multi put took 3.92 seconds while the multi container multi put improved performance by 25% and took 3.13 seconds.
Now, why is the multiple container test so much slower and rate of improvement down? Well, first of all it is writing 10x as much data and that explains the overall difference but the reduced improvement can be explained by the size of the data transfer. The first single container, single put test has very small data transfer sizes and thus the overhead per record is very high while the single-container, multi-put has a larger data transfer size and the overhead per record is already low. Multi-puting to multiple containers does not significantly reduce the overhead.
Multi Query
Multi-queries are typically used when data from multiple containers is used in a single report.
10 Containers
Executing a single container at a time looks like this:
start = datetime.datetime.utcnow().timestamp()
for no in [0, 1, 2, 3, 4, 5, 6, 7, 8, 9 ]:
col = gridstore.get_container("col0"+str(no))
query = col.query("select *")
rs = query.fetch(False)
while rs.has_next():
data = rs.next()
print("single container query took "+ str(datetime.datetime.utcnow().timestamp() - start) +" seconds")gridstore.fetch_all() is used to query multiple containers:
queries=[]
col={}
start = datetime.datetime.utcnow().timestamp()
for no in [0, 1, 2, 3, 4, 5, 6, 7, 8, 9 ]:
col[no] = gridstore.get_container("col0"+str(no))
query = col[no].query("select *")
if query != None:
queries.append(query)
gridstore.fetch_all(queries)
for query in queries:
rs = query.get_row_set()
while rs.has_next():
data = rs.next()
print("multi container query took "+ str(datetime.datetime.utcnow().timestamp() - start) +" seconds")The single container query took 0.34 seconds and multi container query took 0.28 seconds an improvement of 20%.
100 Containers
Now, let's try querying 100 containers with a query that returns 1 row each, without multi-put it looks like this:
start = datetime.datetime.utcnow().timestamp()
for no in [0, 1, 2, 3, 4, 5, 6, 7, 8, 9,
0, 1, 2, 3, 4, 5, 6, 7, 8, 9,
0, 1, 2, 3, 4, 5, 6, 7, 8, 9,
0, 1, 2, 3, 4, 5, 6, 7, 8, 9,
0, 1, 2, 3, 4, 5, 6, 7, 8, 9,
0, 1, 2, 3, 4, 5, 6, 7, 8, 9,
0, 1, 2, 3, 4, 5, 6, 7, 8, 9,
0, 1, 2, 3, 4, 5, 6, 7, 8, 9,
0, 1, 2, 3, 4, 5, 6, 7, 8, 9,
0, 1, 2, 3, 4, 5, 6, 7, 8, 9 ]:
col = gridstore.get_container("col0"+str(no))
query = col.query("select * limit 1")
rs = query.fetch(False)
while rs.has_next():
data = rs.next()
print("single container query took "+ str(datetime.datetime.utcnow().timestamp() - start) +" seconds")With multi-query:
queries=[]
col={}
start = datetime.datetime.utcnow().timestamp()
for no in [0, 1, 2, 3, 4, 5, 6, 7, 8, 9,
0, 1, 2, 3, 4, 5, 6, 7, 8, 9,
0, 1, 2, 3, 4, 5, 6, 7, 8, 9,
0, 1, 2, 3, 4, 5, 6, 7, 8, 9,
0, 1, 2, 3, 4, 5, 6, 7, 8, 9,
0, 1, 2, 3, 4, 5, 6, 7, 8, 9,
0, 1, 2, 3, 4, 5, 6, 7, 8, 9,
0, 1, 2, 3, 4, 5, 6, 7, 8, 9,
0, 1, 2, 3, 4, 5, 6, 7, 8, 9,
0, 1, 2, 3, 4, 5, 6, 7, 8, 9 ]:
if col.get(no) == None:
col[no] = gridstore.get_container("col0"+str(no))
query = col[no].query("select * limit 1")
if query != None:
queries.append(query)
gridstore.fetch_all(queries)
for query in queries:
rs = query.get_row_set()
while rs.has_next():
data = rs.next()
print("multi container query took "+ str(datetime.datetime.utcnow().timestamp() - start) +" seconds")The single container query took 0.04 seconds while the multiple container query took 0.01 seconds which is 671% faster.
Aggregations
Without multiple
start = datetime.datetime.utcnow().timestamp()
for no in [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]:
col = gridstore.get_container("col0"+str(no))
for agg in [ "min", "max", "avg", "count", "stddev"]:
query = col.query("select "+agg+"(count) ")
rs = query.fetch(False)
while rs.has_next():
data = rs.next()
print("single aggregation query took "+ str(datetime.datetime.utcnow().timestamp() - start) +" seconds")With Multi-Query:
queries=[]
col={}
start = datetime.datetime.utcnow().timestamp()
for no in [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]:
if col.get(no) == None:
col[no] = gridstore.get_container("col0"+str(no))
for agg in [ "min", "max", "avg", "count", "stddev"]:
query = col[no].query("select min(count)")
if query != None:
queries.append(query)
gridstore.fetch_all(queries)
for query in queries:
rs = query.get_row_set()
while rs.has_next():
data = rs.next()
print("multi aggregation query took "+ str(datetime.datetime.utcnow().timestamp() - start) +" seconds")The single aggregation queries took 0.08 seconds, while multi aggregation queries took 0.06 seconds, an improvement of 39%.
To Conclude
Multi-put and query can drastically improve the performance of your GridDB application but care must be taken to confirm the improvements.
The amount of data put or queried determines the factor that multi-put/query improve performance. If each put or query transfers large amounts of data the amount of performance gained will be diminished. My experience is that requests that transfer more data than the GridDB data block size, which is by default 64kb will no longer keep gaining performance. Queries that require extra computation (where-clauses, order by, or aggregations) can also affect multi-query performance.