
Introduction
Clustering is a popular data mining task. It involves the division of data items into a number of meaningful groups or clusters. Clustering helps us to identify any underlying relationships between data items, which is good for decision making.
Although there are many clustering algorithms, K-Means is the most popular and simplest clustering algorithm. It works by dividing a data set into k groups. Similar items are put in the same group while dissimilar items are put into different groups. In this article, we will be discussing how to implement the K-Means algorithm using Java and GridDB.
What is K-Means Algorithm?
K-Means is a clustering algorithm that assigns data items to their nearest clusters. It requires you to specify one property, the number of clusters, usually denoted as k.
The following pseudocode describes how the algorithm works:
Step 1: Select `k` initial centroids.
REPEAT:
Step 2: Create `k` clusters by assigning each data point to the nearest cluster centroid.
Step 3: Recompute the new centroids for each cluster.
Until the centroids don't change.
The user is required to specify the value of k, which is the number of clusters to be formed. The algorithm then selects k observations from the dataset to be the centroids for the clusters.
The next step involes going through all the data items and assorting them clusters, while ensuring that every observation is assigned to its closest centroid.
The new centroids for the clusters are then recomputed. This is done by getting the mean of all the observations in a cluster, and the result of the operation becomes the new centroid. The above steps are then repeated until the centroids don’t change any more.
Next, I will be showing you how to implement the K-Means algorithm in Java. We will be using GridDB as the storage database.
Implementing K-Means in Java
In this section, we will be implementing the K-Means algorithm using Java and GridDB. We will use a dataset that shows the annual income of different individuals and their corresponding spending scores.
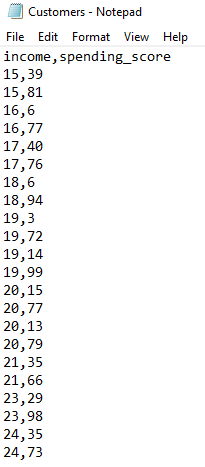
We will first write the data into GridDB, and then pull it from there for analysis using the K-Means algorithm.
Import Packages
First, let’s import the packages that we will need to use:
import java.io.IOException;
import java.util.Collection;
import java.util.Properties;
import java.util.Scanner;
import com.toshiba.mwcloud.gs.Collection;
import com.toshiba.mwcloud.gs.GSException;
import com.toshiba.mwcloud.gs.GridStore;
import com.toshiba.mwcloud.gs.GridStoreFactory;
import com.toshiba.mwcloud.gs.Query;
import com.toshiba.mwcloud.gs.RowKey;
import com.toshiba.mwcloud.gs.RowSet;Write Data into GridDB
The data has been stored in a CSV file named “Customers.csv”, but we need to move it to a GridDB container. First, let’s create the container schema as a static class:
public static class Customers{
@RowKey String income;
String spending_score;
}See the above class as a container or a SQL table with two columns.
We should now establish a connection to GridDB. We should create a Properties instance using the specifics of our GridDB installation, including the name of the cluster to connect to, the name of the user who needs to connect, and the password for that user. Use the following code:
Properties props = new Properties();
props.setProperty("notificationAddress", "239.0.0.1");
props.setProperty("notificationPort", "31999");
props.setProperty("clusterName", "defaultCluster");
props.setProperty("user", "admin");
props.setProperty("password", "admin");
GridStore store = GridStoreFactory.getInstance().getGridStore(props);The above are the details of my GridDB installation. Change them to reflect your specifics.
Since we will be using the Customers container, let us first select it:
Collection<String, Customers> coll = store.putCollection("col01", Customers.class);We have created an instance of the container Customers and given it the name coll. We will be using this instance to refer to the container.
Store the Data in GridDB
The following java code will help us to read the data from the “Customers.csv” file and store it into GridDB:
File file1 = new File("Customers.csv");
Scanner sc = new Scanner(file1);
String data = sc.next();
while (sc.hasNext()){
String scData = sc.next();
String dataList[] = scData.split(",");
String income = dataList[0];
String spending_score = dataList[1];
Customers customers = new Customers();
customers.income = income;
customers.spending_score = spending_score;
coll.append(customers);
}The code reads data from the “Customers.csv” file and creates a customers object. It has then appended the customers object into the GridDB container. The comma (,) has been used as the delimiter for the .csv dataset.
Retrieve the Data from GridDB
We can now pull the data from GridDB and analyze it using the K-Means algorithm. The following code will help you to query GridDB for the data:
Query<customers> query = coll.query("select *");
RowSet</customers><customers> rs = query.fetch(false);
RowSet res = query.fetch();</customers>The select * statement helps us to query for all the data from the database container.
Cluster the Data
Now that the data has been pulled from the database, we can cluster it using the K-Means algorithm. We will create two clusters from the data, thus, the value of k will be set to 2.
We will also initialize two points to act as the initial centroids for the two cluster centroids. The code will calculate the distance between each data item and the centroids, then assign each data item to its closest cluster.
The code will stop the iterations when the cluster centroids stop changing.
Here is the code:
int x,j,k=2;
int cluster1[][] = new int[18][10];
int cluster2[][] = new int[20][80];
float mean1[][] = new float[1][2];
float mean2[][] = new float[1][2];
float temp1[][] = new float[1][2], temp2[][] = new float[1][2];
int sum11 = 0, sum12 = 0, sum21 = 0, sum22 = 0;
double dist1, dist2;
int i1 = 0, i2 = 0, itr = 0;
System.out.println("nNumber of clusters: "+k);
// Set random means
mean1[0][0] = 18;
mean1[0][1] = 10;
mean2[0][0] = 20;
mean2[0][1] = 80;
// Loop untill the new mean and previous mean are the same
while(!Arrays.deepEquals(mean1, temp1) || !Arrays.deepEquals(mean2, temp2)) {
//Empty the partitions
for(x=0;x<10;x++) {
cluster1[x][0] = 0;
cluster1[x][1] = 0;
cluster2[x][0] = 0;
cluster2[x][1] = 0;
}
i1 = 0; i2 = 0;
//Find the distance between mean and the data point and store it in its corresponding partition
for(x=0;x<10;x++) {
dist1 = Math.sqrt(Math.pow(res[x][0] - mean1[0][0],2) + Math.pow(res[x][1] - mean1[0][1],2));
dist2 = Math.sqrt(Math.pow(res[x][0] - mean2[0][0],2) + Math.pow(res[x][1] - mean2[0][1],2));
if(dist1 < dist2) {
cluster1[i1][0] = res[x][0];
cluster1[i1][1] = res[x][1];
i1++;
}
else {
cluster2[i2][0] = res[x][0];
cluster2[i2][1] = res[x][1];
i2++;
}
}
//Store the previous mean
temp1[0][0] = mean1[0][0];
temp1[0][1] = mean1[0][1];
temp2[0][0] = mean2[0][0];
temp2[0][1] = mean2[0][1];
//Find the new mean for new partitions
sum11 = 0; sum12 = 0; sum21 = 0; sum22 = 0;
for(x=0;x<i1;x++) {
sum11 += cluster1[x][0];
sum12 += cluster1[x][1];
}
for(x=0;x<i2;x++) {
sum21 += cluster2[x][0];
sum22 += cluster2[x][1];
}
mean1[0][0] = (float)sum11/i1;
mean1[0][1] = (float)sum12/i1;
mean2[0][0] = (float)sum21/i2;
mean2[0][1] = (float)sum22/i2;
itr++;
}
System.out.println("Cluster1:");
for(x=0;x<i1;x++) {
System.out.println(cluster1[x][0]+" "+cluster1[x][1]);
}
System.out.println("nCluster2:");
for(x=0;x<i2;x++) {
System.out.println(cluster2[x][0]+" "+cluster2[x][1]);
}
System.out.println("nFinal Mean: ");
System.out.println("Mean1 : "+mean1[0][0]+" "+mean1[0][1]);
System.out.println("Mean2 : "+mean2[0][0]+" "+mean2[0][1]);
System.out.println("nTotal Iterations: "+itr);Compile and Run the Code
First, login as the gsadm user. Move your .java file to the bin folder of your GridDB located in the following path:
/griddb_4.6.0-1_amd64/usr/griddb-4.6.0/bin
Next, run the following command on your Linux terminal to set the path for the gridstore.jar file:
export CLASSPATH=$CLASSPATH:/home/osboxes/Downloads/griddb_4.6.0-1_amd64/usr/griddb-4.6.0/bin/gridstore.jar
Next, run the following command to compile your .java file:
javac Kmeans.java
Run the .class file that is generated by running the following command:
java Kmeans
The code will show you the data points that have been clustered to each of the two clusters, the mean of each cluster, and the number of iterations that have been made as shown below. The data points put in the same cluster are more similar to each other than to the data points put in the other cluster.
Number of clusters: 2
Cluster1:
15 39
16 6
17 40
18 6
19 3
Cluster2:
15 89
16 77
17 76
18 94
19 72
Final Mean:
Mean1 : 17.0 18.8
Mean2 : 17.0 81.6
Total Iterations: 2
Congratulations!
That’s how to implement the K-Means algorithm using Java and GridDB.