In the last few years, the time-series database category has experienced the fastest growth. Both established and emerging technology sectors have been producing an increasing amount of time-series data.
The quantity of sessions in a given period of time is known as web traffic, and it varies greatly depending on the time of day, day of the week, and other factors. The amount of web traffic a platform can handle is determined by the size of the servers that host the platform.
Based on historical visitor volume data or historical web traffic data, you can dynamically allocate many servers. And that brings us to the data science challenge, which is basically analysing and forecasting the volume of sessions or web traffic based on past data.
The outline of the tutorial is as follows:
- Dataset overview
- Importing required libraries
- Loading the dataset
- Analysing with data visualization
- Forecasting
- Conclusion
Prerequisites and Environment setup
The full jupyter file and be found in our GitHub repo:
$ git clone –branch web-forecasting https://github.com/griddbnet/Blogs.git
This tutorial is carried out in Anaconda Navigator (Python version – 3.8.5) on Windows Operating System. The following packages need to be installed before you continue with the tutorial –
-
Pandas
-
NumPy
-
re
-
Matplotlib
-
Seaborn
-
griddb_python
-
fbprophet
You can install these packages in Conda’s virtual environment using conda install package-name. In case you are using Python directly via terminal/command prompt, pip install package-name will do the work.
GridDB Installation
While loading the dataset, this tutorial will cover two methods – Using GridDB as well as Using Pandas. To access GridDB using Python, the following packages also need to be installed beforehand:
- GridDB C-client
- SWIG (Simplified Wrapper and Interface Generator)
- GridDB Python Client
1. Dataset Overview
The dataset consists of approximately 145k time series. Each of these time series represent a number of daily views of a different Wikipedia article, starting from July, 1st, 2015 up until December 31st, 2016.
https://www.kaggle.com/competitions/web-traffic-time-series-forecasting/data
2. Importing Required Libraries
%matplotlib inline
import pandas as pd
import numpy as np
import re
import seaborn as sns
from fbprophet import Prophet
import griddb_python as griddb
import matplotlib.pyplot as plt
plt.style.use('fivethirtyeight')
import warnings
warnings.filterwarnings("ignore")3. Loading the Dataset
You can download the dataset for yourself here: https://www.kaggle.com/competitions/web-traffic-time-series-forecasting/data?select=train_1.csv.zip
Let’s proceed and load the dataset into our notebook.
3.a Using GridDB
Toshiba GridDB™ is a highly scalable NoSQL database best suited for IoT and Big Data. The foundation of GridDB’s principles is based upon offering a versatile data store that is optimized for IoT, provides high scalability, tuned for high performance, and ensures high reliability.
To store large amounts of data, a CSV file can be cumbersome. GridDB serves as a perfect alternative as it in open-source and a highly scalable database. GridDB is a scalable, in-memory, No SQL database which makes it easier for you to store large amounts of data. If you are new to GridDB, a tutorial on reading and writing to GridDB can be useful.
Assuming that you have already set up your database, we will now write the SQL query in python to load our dataset.
The read_sql_query function offered by the pandas library converts the data fetched into a panda data frame to make it easy for the user to work.
sql_statement = ('SELECT * FROM train_1.csv)
df1 = pd.read_sql_query(sql_statement, cont)Note that the cont variable has the container information where our data is stored. Replace the credit_card_dataset with the name of your container. More info can be found in this tutorial reading and writing to GridDB.
When it comes to IoT and Big Data use cases, GridDB clearly stands out among other databases in the Relational and NoSQL space. Overall, GridDB offers multiple reliability features for mission-critical applications that require high availability and data retention.
3.b Using pandas read_csv
We can also use Pandas’ read_csv function to load our data. Both of the above methods will lead to the same output as the data is loaded in the form of a pandas dataframe using either of the methods.
df = pd.read_csv('train_1.csv', parse_dates=True) df.head()4. Analysing with data visualization
Is Traffic Influenced by Page Language?
How the various languages used in Wikipedia might affect the dataset is one thing that might be interesting to examine. I’ll search for the language code in the wikipedia URL using a straightforward regular expression.
train_1 = dfdef get_language(page):
res = re.search('[a-z][a-z].wikipedia.org',page)
if res:
return res[0][0:2]
return 'na'
train_1['lang'] = train_1.Page.map(get_language)
from collections import Counter
print(Counter(train_1.lang))Counter({'en': 24108, 'ja': 20431, 'de': 18547, 'na': 17855, 'fr': 17802, 'zh': 17229, 'ru': 15022, 'es': 14069})
lang_sets = {}
lang_sets['en'] = train_1[train_1.lang=='en'].iloc[:,0:-1]
lang_sets['ja'] = train_1[train_1.lang=='ja'].iloc[:,0:-1]
lang_sets['de'] = train_1[train_1.lang=='de'].iloc[:,0:-1]
lang_sets['na'] = train_1[train_1.lang=='na'].iloc[:,0:-1]
lang_sets['fr'] = train_1[train_1.lang=='fr'].iloc[:,0:-1]
lang_sets['zh'] = train_1[train_1.lang=='zh'].iloc[:,0:-1]
lang_sets['ru'] = train_1[train_1.lang=='ru'].iloc[:,0:-1]
lang_sets['es'] = train_1[train_1.lang=='es'].iloc[:,0:-1]
sums = {}
for key in lang_sets:
sums[key] = lang_sets[key].iloc[:,1:].sum(axis=0) / lang_sets[key].shape[0]So then how does the total number of views change over time? I’ll plot all the different sets on the same plot.
days = [r for r in range(sums['en'].shape[0])]
fig = plt.figure(1,figsize=[13,8])
plt.ylabel('Views per Page')
plt.xlabel('Day')
plt.title('Pages in Different Languages')
labels={'en':'English','ja':'Japanese','de':'German',
'na':'Media','fr':'French','zh':'Chinese',
'ru':'Russian','es':'Spanish'
}
for key in sums:
plt.plot(days,sums[key],label = labels[key] )
plt.legend()
plt.show()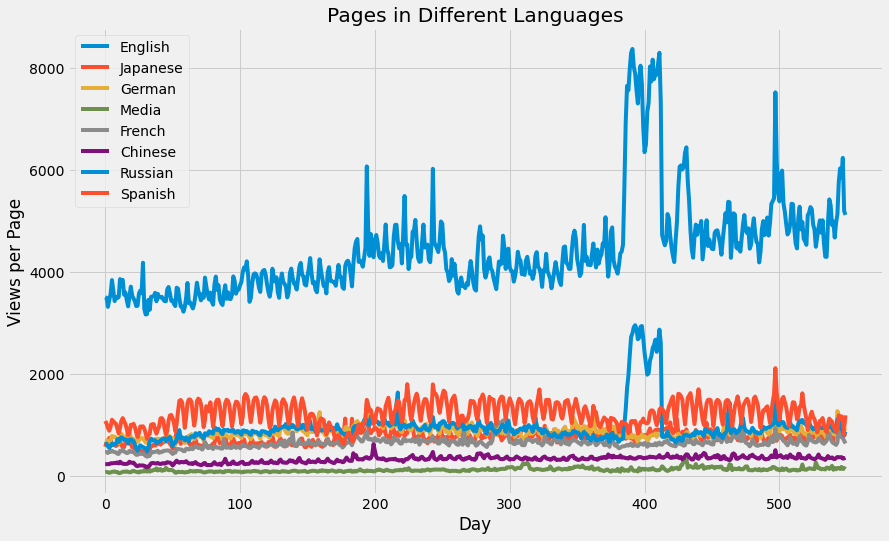
English shows a much higher number of views per page, as might be expected since Wikipedia is a US-based site.
df1 = df.T
df1 = df1.reset_index()df1.head()df1=df1[:550]column_header = df1.iloc[0,:].values
df1.columns = column_header
df1 = df1.drop(0, axis = 0)
df1 = df1.rename(columns = {"Page" : "Date"})df1["Date"] = pd.to_datetime(df1["Date"], format='%Y-%m-%d')
df1 = df1.set_index("Date")# Finding number of access types and agents
access_types = []
agents = []
for column in df1.columns:
access_type = column.split("_")[-2]
agent = column.split("_")[-1]
access_types.append(access_type)
agents.append(agent)# Counting access types
from collections import Counter
access_dict = Counter(access_types)
access_dictCounter({'all-access': 74315, 'desktop': 34809, 'mobile-web': 35939})
access_df = pd.DataFrame({"Access type" : access_dict.keys(),
"Number of columns" : access_dict.values()})
access_dfagents_dict = Counter(agents)
agents_dictCounter({'spider': 34913, 'all-agents': 110150})
agents_df = pd.DataFrame({"Agent" : agents_dict.keys(),
"Number of columns" : agents_dict.values()})
agents_dfdf1.columns[86543].split("_")[-3:]
"_".join(df1.columns[86543].split("_")[-3:])
projects = []
for column in df1.columns:
project = column.split("_")[-3]
projects.append(project)project_dict = Counter(projects)
project_df = pd.DataFrame({"Project" : project_dict.keys(),
"Number of columns" : project_dict.values()})
project_dfdef extract_average_views(project):
required_column_names = [column for column in df1.columns if project in column]
average_views = df1[required_column_names].sum().mean()
return average_views
average_views = []
for project in project_df["Project"]:
average_views.append(extract_average_views(project))project_df["Average views"] = average_views
project_df['Average views'] = project_df['Average views'].astype('int64')
project_dfproject_df_sorted = project_df.sort_values(by = "Average views", ascending = False)plt.figure(figsize = (10,6))
sns.barplot(x = project_df_sorted["Project"], y = project_df_sorted["Average views"])
plt.xticks(rotation = "vertical")
plt.title("Average views per each project")
plt.show()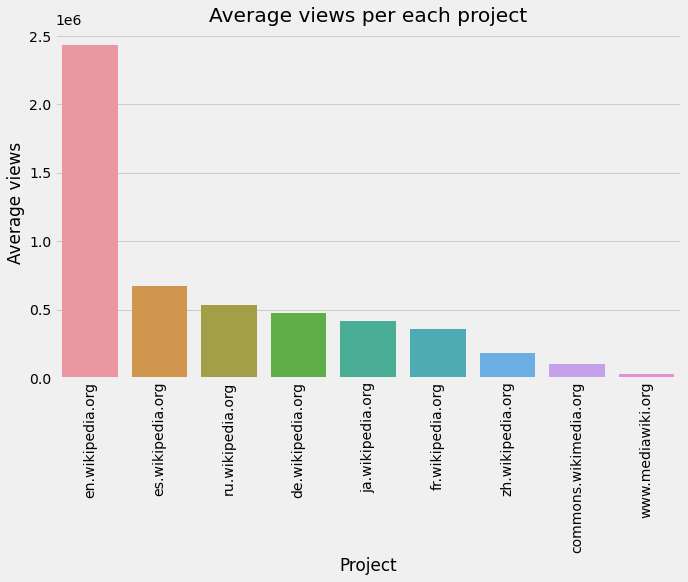
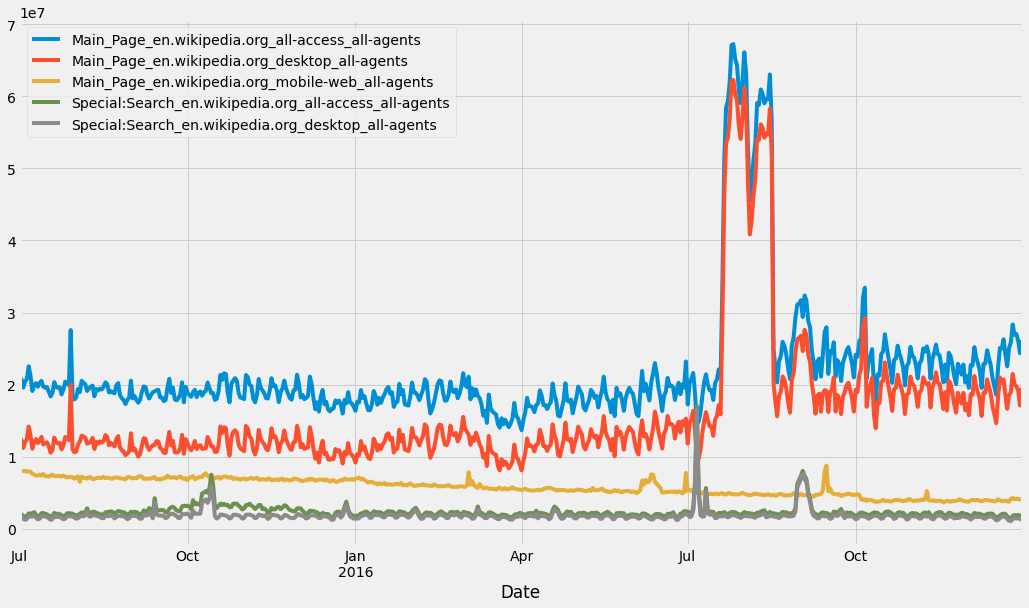
Popular pages in “en.wikipedia.org”
en_wikipedia_org_columns = [column for column in df1.columns if "en.wikipedia.org" in column]
top_pages_en = df1[en_wikipedia_org_columns].mean().sort_values(ascending = False)[0:5]
df1[top_pages_en.index].plot(figsize = (16,9))<AxesSubplot:xlabel='Date'>
5. Forecasting
train = dftraintrain=pd.melt(df[list(df.columns[-50:])+['Page']], id_vars='Page', var_name='date', value_name='Visits')list1 = ['lang']
train = train[train.date.isin(list1) == False]traintrain['date'] = train['date'].astype('datetime64[ns]')
train['weekend'] = ((train.date.dt.dayofweek) // 5 == 1).astype(float)
median = pd.DataFrame(train.groupby(['Page'])['Visits'].median())
median.columns = ['median']
mean = pd.DataFrame(train.groupby(['Page'])['Visits'].mean())
mean.columns = ['mean']
train = train.set_index('Page').join(mean).join(median)
train.reset_index(drop=False,inplace=True)
train['weekday'] = train['date'].apply(lambda x: x.weekday())
train['year']=train.date.dt.year
train['month']=train.date.dt.month
train['day']=train.date.dt.daymean_g = train[['Page','date','Visits']].groupby(['date'])['Visits'].mean()
means = pd.DataFrame(mean_g).reset_index(drop=False)
means['weekday'] =means['date'].apply(lambda x: x.weekday())
means['Date_str'] = means['date'].apply(lambda x: str(x))
#create new columns year,month,day in the dataframe bysplitting the date string on hyphen and converting them to a list of values and add them under the column names year,month and day
means[['year','month','day']] = pd.DataFrame(means['Date_str'].str.split('-',2).tolist(), columns = ['year','month','day'])
#creating a new dataframe date by splitting the day column into 2 in the means data frame on sapce, to understand these steps look at the subsequent cells to understand how the day column looked before this step
date = pd.DataFrame(means['day'].str.split(' ',2).tolist(), columns = ['day','other'])
means['day'] = date['day']*1means.drop('Date_str',axis = 1, inplace =True)import seaborn as sns
sns.set(font_scale=1)
date_index = means[['date','Visits']]
date_index = date_index.set_index('date')
prophet = date_index.copy()
prophet.reset_index(drop=False,inplace=True)
prophet.columns = ['ds','y']
m = Prophet()
m.fit(prophet)
future = m.make_future_dataframe(periods=30,freq='D')
forecast = m.predict(future)
fig = m.plot(forecast)INFO:fbprophet:Disabling yearly seasonality. Run prophet with yearly_seasonality=True to override this.
INFO:fbprophet:Disabling daily seasonality. Run prophet with daily_seasonality=True to override this.
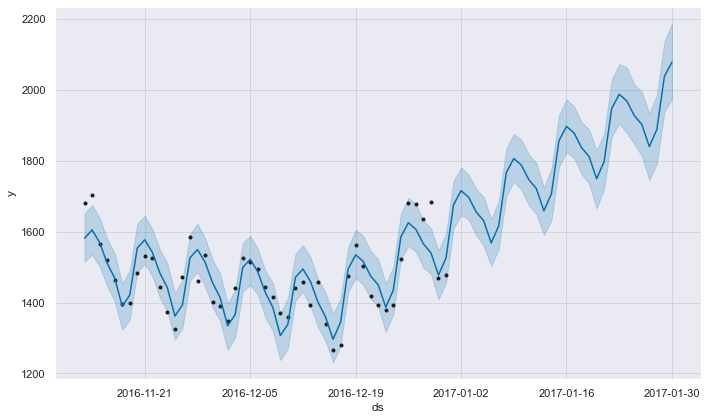
6. Conclusion
In this tutorial we analysed and forecasted web traffic using Python and GridDB. We examined two ways to import our data, using (1) GridDB and (2) Pandas. For large datasets, GridDB provides an excellent alternative to import data in your notebook as it is open-source and highly scalable.
If you have any questions about the blog, please create a Stack Overflow post here https://stackoverflow.com/questions/ask?tags=griddb .
Make sure that you use the “griddb” tag so our engineers can quickly reply to your questions.