
Introduction
Most websites make their data available to users via APIs. However, there are websites that have not developed such APIs. To access data from such sites, we use web scraping.
Web scraping is a technique used to extract data from website content. The data is normally extracted from the HTML elements of the respective website.
Suppose you’re looking for a job as a Java Programmer in Washington DC. It means that you’ll have to invest a lot of time to look for the job. Searching for a job manually is boring and time-consuming.
To make the process easier and save time, you can automate it by creating a web scraper using Jsoup. The work of the web scraper will be to scrape data about jobs from job listing websites of your choice and store it in a database such as GridDB.
Web scraping can speed up the data collection process and save you time. In this article, I will be showing you how to scrape data from websites using Jsoup in Java and store the data in GridDB.
Perquisites
What is Jsoup?
Jsoup is a Java library that is made up of methods for extracting and manipulating HTML document content. Jsoup is open source and it was developed by Jonathan Hedley in 2009. If you are good in jQuery, then working with Jsoup should be a walk in the park for you. This is what you can do with Jsoup:
-
Scraping and parsing HTML from a file, URL, or string
-
Finding and extracting data using CSS selectors or DOM traversal
-
Manipulating HTML elements, text, and attributes
-
outputting tidy HTML
How to Add Jsoup to your Project
To use the Jsoup library, you MUST add it to your Java project. You need to download its jar file from Jsoup site and then reference it in your Java project. Below is the URL to the Jsoup site:
https://jsoup.org/download
In Eclipse, follow the steps given below:
Step 1: Right click the project name on the Project Explorer and choose “Properties..” from the menu that pops up.
Step 2: Do the following on the Properties dialog:
-
Select the Java Build path from the list given on the left
-
Click the “Libraries” tab
-
Click the “Add external JARS…” button then navigate to where you have stored the Jsoup jar file. Click the “Open” button.
Step 3: Click “OK” to close the dialog box.
However, it’s possible to use the Jsoup library directly from the terminal of your operating system as you will see later in this article.
Import the Packages
We should first import all the libraries that will be needed in the project. This is shown below:
import java.io.IOException;
import java.util.Collection;
import java.util.Properties;
import java.util.Scanner;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import com.toshiba.mwcloud.gs.Collection;
import com.toshiba.mwcloud.gs.GSException;
import com.toshiba.mwcloud.gs.GridStore;
import com.toshiba.mwcloud.gs.GridStoreFactory;
import com.toshiba.mwcloud.gs.Query;
import com.toshiba.mwcloud.gs.RowKey;
import com.toshiba.mwcloud.gs.RowSet;Next, I will be showing you how to fetch content from a web page using Jsoup.
How to Fetch the Page
To work with the DOM, you should have a parsable document markup. Jsoup uses the org.jsoup.nodes.Document object to represent web pages.
The first step towards fetching a web page is establishing a connection to the resource. Next, you should call the get() function to retrieve the contents of the web page.
In this article, we will be scraping the Java sub-reddit on the following url:
https://www.reddit.com/r/java/
Let us fetch the page:
Document subreddit = Jsoup.connect("https://www.reddit.com/r/java/").get();Some websites don’t allow crawling using unknown user agents. To prevent the web scraper from being blocked, let us use the Mozilla user agent:
Document subreddit = Jsoup.connect("https://www.reddit.com/r/java/").userAgent("Mozilla").data("name", "jsoup").get();We have created a Document container and given it the name subreddit to store the HTML contents of the web page.
If you print out the contents of subreddit container, you should get the HTML contents of the web page, that is, the Java sub-reddit. Simply run the following command:
System.out.println(subreddit);In our case, we are only interested in fetching the titles of posts and the time each post was created. We will use HTML tags for this. All titles have been stored within an <h3> tag and given a class name as shown below:
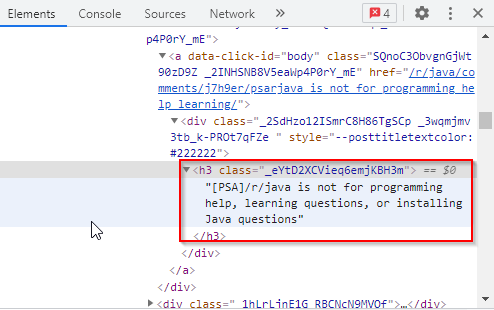
The times the posts were created have been stored within an <a> tag and given a class name as shown below:
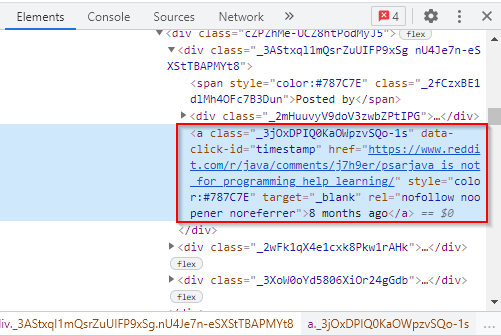
We will use the above HTML tags to scrape the title posts and the times they were created from the website. The following is the Java code for scraping the titles:
Elements titles = subreddit.select("h3[class]._eYtD2XCVieq6emjKBH3m");
for (Element title : titles)
{
System.out.println("Title: " + title.text());
}We have created an element named titles in which all the titles will be stored. We have then created a for loop to iterate over all the items stored in the element and print them out. This will help us to access individual titles of posts.
The following is the Java code for scraping the times the posts were created:
Elements times = subreddit.select("a[class]._3jOxDPIQ0KaOWpzvSQo-1s");
for (Element time : times) {
System.out.println("Time Posted: " + time.text());
}We have created an element named times to store all the times extracted from the site. A for loop has then been used to iterate over the items stored in the element and print them out.
Let us put the code together by nesting the for loops and surround it by a try and catch block to catch any exceptions that may be thrown when scraping the website. This is shown below:
try {
for (Element title : titles) {
for (Element time : times) {
System.out.println("Title: " + title.text());
System.out.println("Time Posted: " + time.text());
}
}
catch (IOException e) {
e.printStackTrace();
}
}If you run the code at this point, you should see the text that has been scraped from the site, including post titles and the times they were created.
Store Scraped Data in GridDB
Now that we’ve managed to successfully scrape data from the site, it’s time to store it in GridDB.
First, let’s create the container schema as a static class:
public static class Post{
@RowKey String post_title;
String when;
}The above class represents a container in our cluster. You can see it as a SQL table.
To establish a connection to GridDB, we’ve to create a Properties instance using the particulars of our GridDB installation, including the name of the cluster to connect to, the name of the user who needs to connect, and the password for that user. The following code demonstrates this:
Properties props = new Properties();
props.setProperty("notificationAddress", "239.0.0.1");
props.setProperty("notificationPort", "31999");
props.setProperty("clusterName", "defaultCluster");
props.setProperty("user", "admin");
props.setProperty("password", "admin");
GridStore store = GridStoreFactory.getInstance().getGridStore(props);For us to start running queries, we have to get the respective container. Remember that we created a container named Post. Let us get it:
Collection<String, Post> coll = store.putCollection("col01", Post.class);We have created an instance of the container and given it the name coll. This is what we will be using to refer to the container.
Next, let us create indexes for each of the two columns of the container:
coll.createIndex("post_title");
coll.createIndex("when");
coll.setAutoCommit(false);Note that we’ve also set autocommit to false. This means that we will have to commit changes manually.
Next, we will create an instance of our container, that is, Post and use that instance to prepare and insert data into the container. This is shown below:
Post post = new Post();
post.post_title = title.text();
post.when = time.text();
coll.put(post);
coll.commit();We have also committed the changes made to the database, hence, they cannot be undone.
Compile the Code
First, login as the gsadm user. Move your java file and the .jar file for Jsoup to the bin folder of your GridDB located in the following path:
/griddb_4.6.0-1_amd64/usr/griddb-4.6.0/bin
Next, run the following command on your Linux terminal to set the path for the gridstore.jar file:
export CLASSPATH=$CLASSPATH:/home/osboxes/Downloads/griddb_4.6.0-1_amd64/usr/griddb-4.6.0/bin/gridstore.jarNext, navigate to the above directory and run the following command to compile your WebScraping.java file:
javac -cp jsoup-1.13.1.jar WebScraping.javaRun the .class file that is generated by running the following command:
java WebScrapingCongratulations!
That’s how to scrape data from a website using Jsoup in Java and insert data into GridDB.