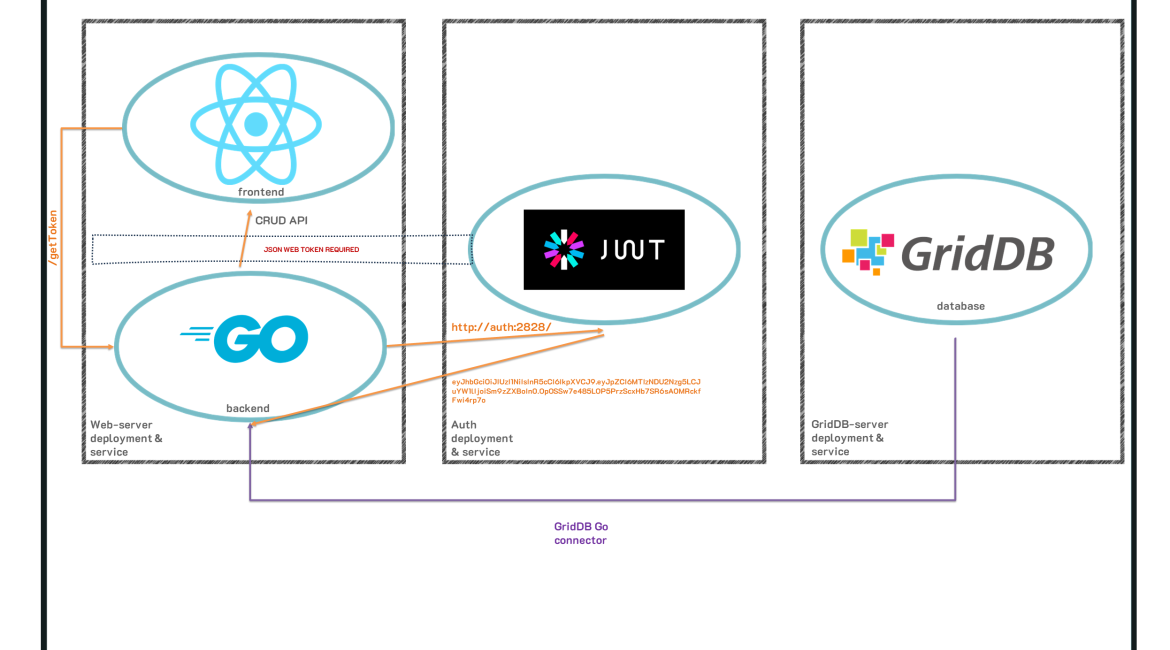
前回の記事では、マイクロサービス・アーキテクチャを利用したGridDBアプリケーションの作り方を紹介しました。GridDBサーバ、Todoアプリケーションを提供するGoウェブサーバ、JSONウェブトークンバックの認証サービスです。その全過程と全ソースコードについては、こちらをご覧ください: ブログ
このような前回の取り組みを踏まえ、次の論理的なステップは docker compose から kubernetes クラスタに移行することだと考えました。具体的には、シングルノードのローカルkubernetesクラスタを使用して、以前に構築した3つのコンテナを実行することを目指しています。kubernetesについてよく知らないかもしれないが、これはコンテナ・オーケストレーション・システムであり、アプリケーションを簡単にデプロイできるようにすることを目的としています。
簡潔に言うと、3つのdockerコンテナをpodのクラスタとしてkubernetesで実行できるように変換します。kubernetesは、ネットワーク、ホスト名、永続ストレージなどすべてを処理します。完了する頃には、ローカルマシンでもクラウドプロバイダーでも実行可能な、完全にスケーラブルで堅牢なアプリケーションが完成しており、最終的には本番グレードのアプリケーションの準備が整うことになります。
概要
このプロジェクトの本題に入る前に、全体的な設計と概要、前提条件について説明しましょう。
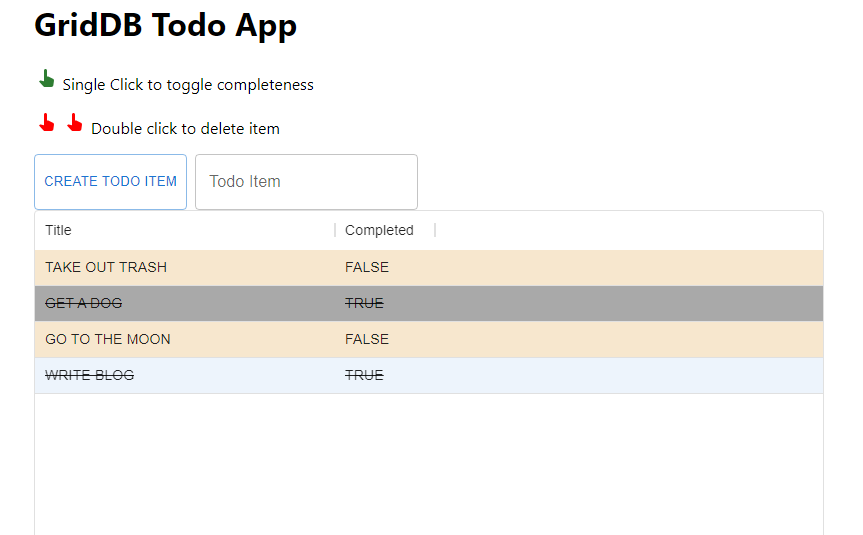
以下は、これから作るアプリのスクリーンショットです。永続的なストレージ、ウェブトークンを必要とするエンドポイント、kubernetesで構築されたシンプルなTodoアプリです。
前提条件
次のセクションでは、kubernetesソフトウェアのインストールについて説明します。
ソースコードはここからダウンロードできます:
$ git clone https://github.com/griddbnet/Blogs.git --branch kubernetes仕組み
前に説明したように、前回の記事で構築したdockerコンテナを使い、kubernetesサービスに変換する。こうすることで、kubernetesがネットワーキングやスケーリングを処理し、コンテナに障害が発生した場合は自動的にコンテナを復旧させる、より堅牢なシステムを手に入れることができます。今回はシリーズなので、kubernetesクラスタを形成するために使用するコンテナのソースコードについては、前回のブログを読んでほしいです。
仕組みとしては、3つのkubernetes podsを作成し、それぞれがdockerコンテナ(Web-server、認証、GridDB)に対応します。これらのポッドと一緒に、各ポッドはネットワーキングを担当する独自のサービスを取得します。Podはすべて互いに依存しており、安全な方法で通信する必要があるため、ネットワーキングのルールを指示する独自のサービスが必要になります。これについては後で詳しく説明します。最後に、マシンのシャットダウンなどでもデータが持続するように、永続ストレージを作成します。
これで、3つのポッド、3つのサービス、永続ボリューム、永続ボリュームのクレームが完成し、ブラウザからポート8080でWeb todoアプリケーションにアクセスできるようになります。
kubernetes のインストール
クラスタの作成を始める前に、ローカルのシングルノードkubernetesクラスタを選択する必要があります。この記事では、軽量でシンプルなk3sを使用します
k3s
をインストールします:
$ curl -sfL https://get.k3s.io | sh - 注:仮想マシンでこのシステムを実行する場合は、システム要件をメモしておいてください。また、一般的にコンテナ・イメージは想像以上に容量を消費するので、十分な大きさの仮想ディスクを用意してください。私のVMでは、4つのvCPU、2GBのRAM、40GBの仮想ディスクを使用しました。
また、kubectlコマンドを使う際にsudoを使わなくて済むように、以下のコマンドを入力することをお勧めします:
$ export KUBECONFIG=~/.kube/config
$ echo "export KUBECONFIG=~/.kube/config" >> ~/.bashrc
$ mkdir ~/.kube 2> /dev/null
$ sudo k3s kubectl config view --raw > "$KUBECONFIG"
$ chmod 600 "$KUBECONFIG"ここで行っているのは、kubectlの設定をユーザーホームディレクトリ内にコピーして、kubectlを使用するパーミッションが制限されないようにすることです。
これで、様々なkubernetesインフラストラクチャを作成するプロセスを開始できます。
Kubernetesクラスタの作成
このセクションでは、todoアプリケーションで作成したdockerイメージを使用し、それらをkubernetesのポッドとサービスに変換します。このプロセスは、クラスタに関するすべての指示を含むyamlファイル形式の特別なkubernetes設定ファイルを使用して行われます。各マイクロサービスを1つ1つ確認しながら進めていきます。
しかしその前に、アプリのイメージをkubernetesのyamlファイルが見つけられる場所に置くという小さなステップがあります。
Dockerレジストリ
kubernetes yamlファイルを作成する際、ローカルでビルドされたアプリケーションのイメージを参照したくなるかもしれませんが、kubernetesはこのファイルにアクセスできません。代わりに、dockerイメージをdockerhubにプッシュするか、ローカルのdocker registryコンテナをスピンアップしてそこにアップロードする必要があります。この記事では、ローカルの docker レジストリを使用する方法を説明します。
まず、docker registryイメージをプルして実行してみましょう。
$ docker run -d -p 5000:5000 --name registry registry:2
このコマンドは、ローカルマシンにまだイメージがない場合、イメージを取得し、バックグラウンドで実行します。docker ps`で確認できます。
これで、dockerイメージをレジストリにプッシュすることができました。
例として、イメージのビルド、タグ付け、ローカルレジストリへのプッシュのプロセスを示します。これらをもう一度確認します。
$ docker build . -t web-server:01
$ docker tag web-server:01 localhost:5000/web-server:01
$ docker push localhost:5000/web-server:01Kubernetes GridDBオブジェクト
まず、すべてのデータを格納するGridDBサーバーのkubernetesオブジェクトを作成しましょう。
GridDB画像の作成とタグ付け
イメージの作成とタグ付けを行おう。
griddb-server`ディレクトリに移動し、イメージをビルドします。
$ docker build . -t griddb-serverそして、タグを付けてローカルのdockerレジストリにプッシュします。
$ docker tag griddb-server:01 localhost:5000/griddb-server:01
$ docker push localhost:5000/griddb-server:01これはその名の通り、Dockerfileにあるコンテンツのイメージを作成し、ローカルのレジストリに保存します。
Kubernetes a Pod/デプロイメントの作成 (GridDB)
次に yaml ファイルでローカルの GridDB イメージを参照します。まず、設定ファイル全体を転記します。
apiVersion: apps/v1
kind: Deployment
metadata:
name: griddb-server-deployment
spec:
replicas: 1
selector:
matchLabels:
app: griddb-server
template:
metadata:
labels:
app: griddb-server
spec:
volumes:
- name: griddb-pv-storage
persistentVolumeClaim:
claimName: griddb-server-pvc
containers:
- name: griddbcontainer
image: localhost:5000/griddb-server:01
imagePullPolicy: IfNotPresent
ports:
- containerPort: 10001
volumeMounts:
- mountPath: "/var/lib/gridstore/data"
name: griddb-pv-storage
securityContext:
runAsUser: 0
runAsGroup: 0
env:
- name: NOTIFICATION_MEMBER
value: '1'
- name: GRIDDB_CLUSTER_NAME
value: "myCluster"まず始めに、次のセクションに注目してみよう:spec.template.spec.containers. ここでは、ローカルレジストリにプッシュしたイメージを参照するようにイメージを設定している。imagePullPolicyにはIfNotPresent` を設定し、kubernetes クラスタにローカルレジストリからプルし、docker hub を参照しないように指示します。
もう一つのセクションは securityContext と env です。特にここでは、コンテナを Fixed_List モードで実行するように指示し、クラスタ名をデフォルトの名前に設定しています。また、Fixed_List モードで実行するプロセスの一環として、griddb の設定ファイルを編集する必要があるため、設定ファイルの変更を保存するのに十分なパーミッションを持つ root ユーザーとして実行する必要があります。
これで、kubernetesにこのポッドの作成を指示すると、kubernetesはこのポッドが常に稼働していることを保証する。エラーが発生してコンテナがクラッシュすると、kubernetesはその状況を認識し、ポッドを削除して新しいポッドをスピンアップします。非常に堅牢なので、ポッドを再起動したい場合は、ポッドを削除してKubernetesに自動再起動させるのがその方法です。
一番最後に指摘すべきことは、一番上にある Kindです。podを作成するkubernetesオブジェクトの種類をdeploymentに設定しています。ここでPod`を選択するAPI設定もあるが、それはニッチな状況に追いやられることがほとんどです。
先に説明したように、ネットワークを処理するサービスも作成する必要があります。
Kubernetes a Service(GridDB)の作成
同じファイルに、---で区切ってサービス情報を記述しましょう。
---
apiVersion: v1
kind: Service
metadata:
name: griddb-server
labels:
app: griddb-server
spec:
type: ClusterIP
ports:
- port: 10001
name: griddb-server
targetPort: 10001
selector:
app: griddb-serverつまり、クラスタ内の他のオブジェクト/ポッドにポートを公開することになります。この場合、GridDBにFixed_Listモードでアクセスするために使用するポート10001を共有します。ここでの良い点は、この単一のファイルを指すことで、kubernetesクラスタにオブジェクトを作成するように指示するだけで、これら両方のオブジェクトを作成できることです。
$ kubectl create -f griddb-server.yaml次に、これらのオブジェクトが実行されていることを確認します。
$ kubectl get pods
$ kubectl get svcこれらのコマンドは両方とも、それぞれのリスペクト・オブジェクトが実行されていることを示すはずである。そしてそれぞれのログを取得します:
$ kubectl logs <pod name></pod>また、対象物のより詳細な情報を見ることもできます:
$ kubectl describe pod <pod name>
$ kubectl describe svc <svc name></svc></pod>では、アプリケーションの他の2つの部分について、このプロセスを繰り返してみましょう。
Kubernetes Webサーバーオブジェクト
このマイクロサービスは、実際のTodoアプリのサーバになります。そのため、Web-serverディレクトリにGridDB APIを作成し、javascriptのフロントエンドから呼び出されるエンドポイントを提供するコードがあります。
まず、web-serverディレクトリに移動し、上記で説明したように、画像のビルド、タグ付け、プッシュを行います。次に、オブジェクトの作成を見てみましょう。
Kubernetes a Pod/デプロイメント(Web-Server)の作成
これらのyamlファイルはどれも大体同じなので、あまり説明せずにデプロイ部分を貼り付けます。
apiVersion: apps/v1
kind: Deployment
metadata:
name: web-server-deployment
spec:
replicas: 1
selector:
matchLabels:
app: web-server
template:
metadata:
labels:
app: web-server
spec:
containers:
- name: webcontainer
image: localhost:5000/web-server:01
imagePullPolicy: IfNotPresent
ports:
- containerPort: 8000ここにはまだ見たことのないものはありません。
少し面白くなるのはサービスオブジェクトです。
Kubernetesのサービス(ウェブサーバー)の作成
これまでのサービスとの違いは、typeになります。
---
apiVersion: v1
kind: Service
metadata:
name: web-server
labels:
app: web-server
spec:
type: LoadBalancer
ports:
- port: 8080
name: web-server
targetPort: 8000
selector:
app: web-serverここでは ClusterIP の代わりに LoadBalancer を使っていることに注目してほしい。ロードバランサーとは何かについては、こちらを参照してください: https://en.wikipedia.org/wiki/Load_balancing_(コンピューティング)。このケースでは、ロードバランサータイプを使用して、ウェブアプリがkubernetesクラスタの外部で検出できるようにしています: 8080.
Kubernetes認証オブジェクト
このサービスは、ウェブサーバーサービスが作成したエンドポイントを使用する際に必要となるJSONウェブトークンを発行することで認証を処理します。このオブジェクトのkubernetesクラスタへの展開は以前の取り組みと同じなので、ここでは説明しません。以下にファイル全体を示します:
apiVersion: apps/v1
kind: Deployment
metadata:
name: auth-deployment
spec:
replicas: 1
selector:
matchLabels:
app: auth
template:
metadata:
labels:
app: auth
spec:
containers:
- name: authcontainer
image: localhost:5000/auth:latest
imagePullPolicy: IfNotPresent
ports:
- containerPort: 2828
---
apiVersion: v1
kind: Service
metadata:
name: auth
labels:
app: auth
spec:
type: ClusterIP
ports:
- port: 2828
name: auth
targetPort: 2828
selector:
app: authKubernetes 永続ストレージ・オブジェクト
GridDBインスタンスの永続ストレージを作成するには、永続ボリューム用のファイルを作成し、さらに永続ボリュームのクレーム用のファイルを作成する必要があります。この後、PVとPVCが作成され、結合されます。その後、デプロイメントにそのボリュームを使用するように指示します。すべてがうまくいけば、ホストマシンがダウンしたり、メンテナンスのために再起動が必要になったりしても、データは持続します。
永続ボリューム
まずPVに入りましょう:
apiVersion: v1
kind: PersistentVolume
metadata:
name: griddb-server-pv
spec:
storageClassName: standard
accessModes:
- ReadWriteOnce
capacity:
storage: 2Gi
volumeMode: Filesystem
hostPath:
path: "/var/lib/gridstore/data"ここでは、データのパスとして使用するストレージクラス名、種類、ホストマシン上のパスを設定しています。ホストをデータのソースとして使用するのは開発目的だけで、本番環境ではazureクラウドストレージなどを設定することになるでしょう。
$ kubectl create -f pv.yaml永続的ボリュームの主張
次にボリュームクレームを作成しましょう。このkubernetesオブジェクトは、必要な特徴にマッチするボリュームを探し出し、見つけたら自動的にそのボリュームにバインドし、デプロイ/ポッドにマウントできるようにします。
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: griddb-server-pvc
spec:
storageClassName: standard
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1Gi最も重要なことは、2つのアイテムの storageClassName が一致することである。
$ kubectl create -f pvc.yamlそして、ボリューム情報をgriddb-serverデプロイメントに追加しよう。
spec:
volumes:
- name: griddb-pv-storage
persistentVolumeClaim:
claimName: griddb-server-pvc
containers:
- name: griddbcontainer
image: localhost:5000/griddb-server:latest
imagePullPolicy: IfNotPresent
ports:
- containerPort: 10001
volumeMounts:
- mountPath: "/var/lib/gridstore/data"
name: griddb-pv-storageこれで、griddb-serverデプロイメントに永続ストレージとクレームの両方をマウントしていることがわかります。
svcを削除して、変更を反映させるために作り直すことができます。
$ kubectl delete deployment griddb-server-deployment
$ kubectl create -f griddb-server.yamlgriddb-serverのsvcを混乱させることを心配する必要はない — 既に存在しているので、kubernetesは単に拒否するだけです。
結論
これで、ホストマシンのipアドレスにアクセスして8080ポートにアクセスし、GridDBの永続的なバッキングを備えた、非常に堅牢でスケーラブルなTodoアプリをチェックアウトすることができます。
If you have any questions about the blog, please create a Stack Overflow post here https://stackoverflow.com/questions/ask?tags=griddb .
Make sure that you use the “griddb” tag so our engineers can quickly reply to your questions.