
このブログの内容は以下の動画でもご覧になることができます。
GridDBには、ユニークなキーコンテナーデータモデルが存在します。このモデルでは、キーは列指向テーブルであるコンテナを指し、コンテナキーは多くの場合コンテナ名となります。 コンテナによって異なるスキーマと行キータイプを持つことができますが、SQLタイプのテーブルとは異なり、コンテナには、あるコンテナの値が別のコンテナと固定の関係を持つというような制約はありません。
通常、1つのデバイス、センサー、または入力からのデータは1つのコレクションに保存されます。 このブログ記事では、コンテナとは何か、コンテナでできることとできないことについて説明します。 また、GridDBアプリケーション内でのデータの一般的な編成方法についても説明します。
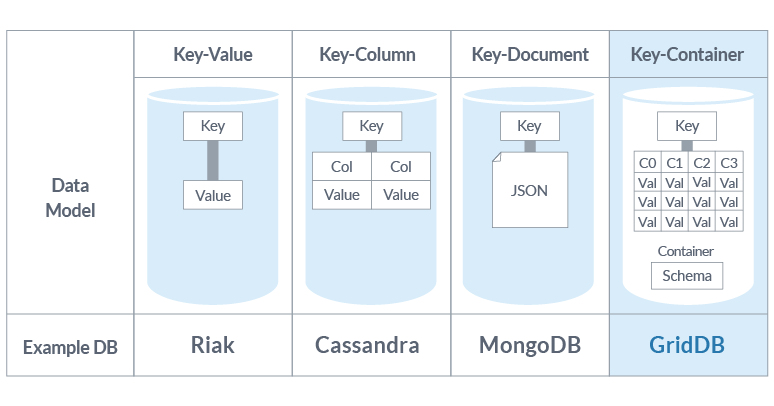
GridDBと他のNoSQLデータベースと比較すると、上図のような違いがあります。RedisのようなKey-Valueデータベースではキーは任意の値を指し、その値の属性は通常インデックス付けまたはクエリできないのに対し、MongoDBなどのKey-Documentデータベースのキーはドキュメントを指し、異なるドキュメントが異なる構造を持つことができます。
コンテナ
GridDBには2つのコンテナタイプがあります。任意のタイプの行キーを持つことができるコレクションと、常に行キーとしてタイムスタンプを持つTimeSeriesです。 これらのコンテナは他にもいくつかのユニークな機能を備えています。
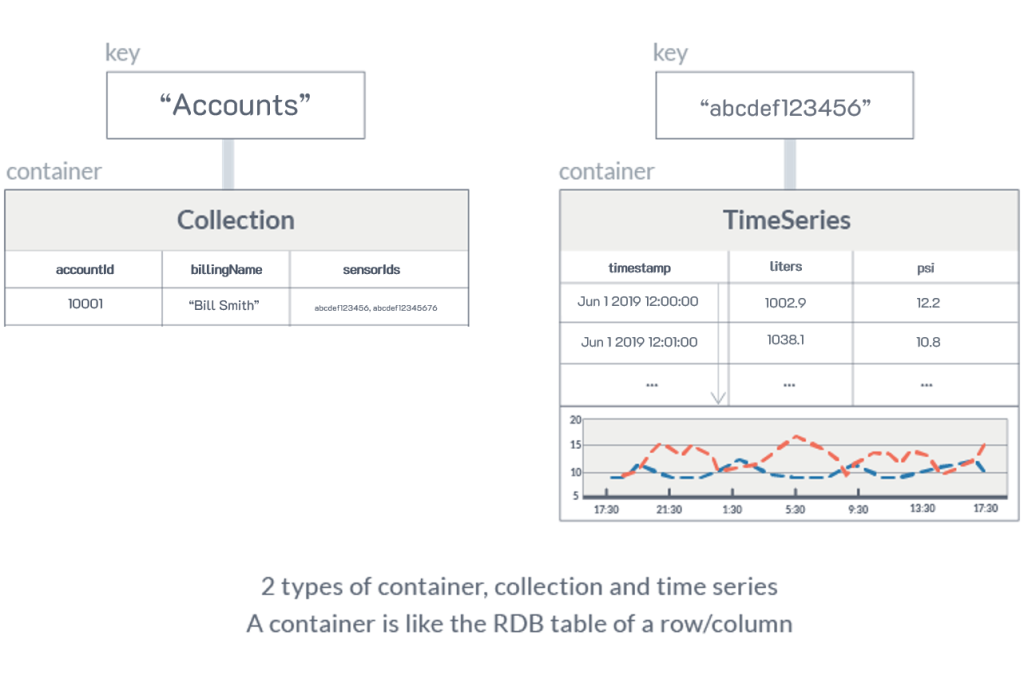
Javaでは、コンテナはタイムスタンプ、単純な文字列、数値、ジオメトリタイプ(詳細はこちら)などの変数の静的クラスによって定義されます。文字列と数値のblobまたは配列がすべてサポートされています(全リストはこちら)。他のすべての言語では、コンテナはContainerInfoオブジェクトによって定義されますが、現時点では配列とジオメトリタイプをサポートしていない言語もあります。
コレクションでは、行キーは一意にもそれ以上にもでき、Javaの型の前に@RowKey属性を配置するか、他の言語のContainerInfoオブジェクトのrow_keyパラメーターを配置することによって決められます。
データモデリング
Key-Containerモデルでは、各デバイス、アプリケーション、センサー、アカウント、またはデータセットが独自のコンテナーを取得し、通常、各タイプのデバイスに同じスキーマが使用されます。 一意のIDはコンテナキーの一部であり、コレクションを使用して多くのコンテナキーを構成することができます。
個々のコンテナのアドホッククエリへの書き込みは、そのコンテナだけをロックすればよいため非常に高速です。多数のコンテナに対する総クエリ時間は、大抵は、Key-Columnまたはリレーショナルデータモデルよりも速くなります。
ここで、水道会社のセンサー記録および請求アプリケーションの例を見てみましょう。
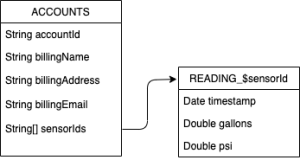
上記のER図は、Javaでは次のクラスで表されます。
static class AccountRecord {
@RowKey String accountId;
String billingName;
String billingAddress;
String billingEmail;
String[] sensorIds;
}
static class SensorReading {
@RowKey Date timestamp;
double liters;
double psi;
}
以下の図は、GridDBがデータを異なるコンテナに配置する方法と、同じデータがリレーショナルデータベースではどのように表されるかを示しています。
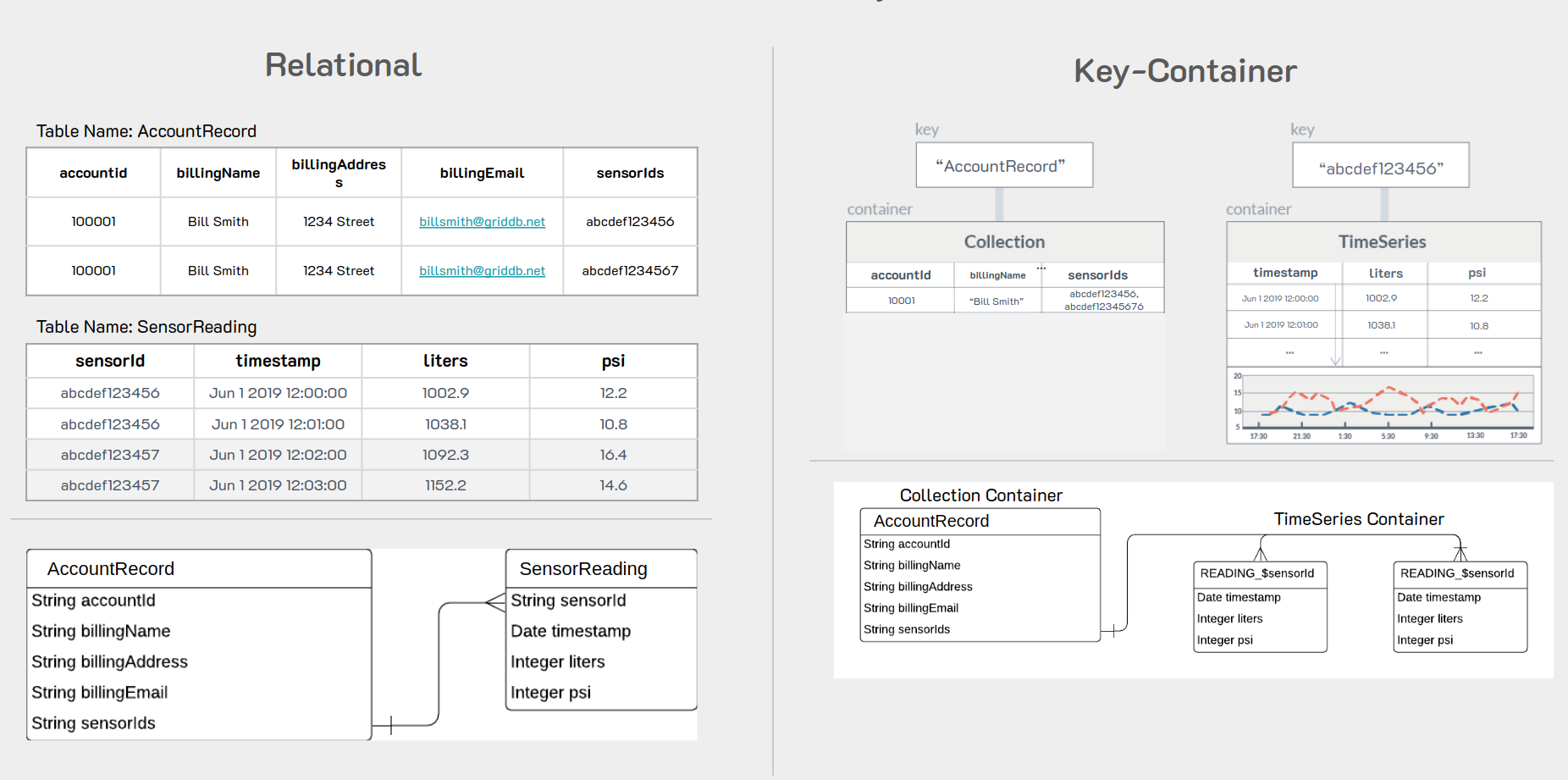
リレーショナルデータベースでは、すべてのセンサーが1つのテーブルに読み込まれることに注意してください(注:RDMBSではより効率的な方法である、すべてのセンサーを1つのテーブルに挿入する方法を採用しています)。 アプリケーションが数万のセンサーにスケールアウトしてしまうため、センサーを格納しているRDBMSテーブルはすぐに扱いにくくなり、大幅な速度低下のため有意義な作業を行うことができなくなります。
時間が経つにつれて、各センサーは適切なSENSOR_ $ sensorIdコンテナーにデータをプッシュし、顧客はアカウントに適用されるsensorIdとともにACCOUNTSコンテナーに書き込まれます。 請求書を作成する際、請求書作成アプリケーションはアカウントの行を繰り返し処理し、各READING_ $ sensorIdコンテナーを読み取って請求書を計算します。
GridDBの斬新なキーコンテナデータモデルにより、開発において、多数の個別入力のデータ(時系列か否かに関わらず)を、集約および反復可能な多数のコンテナに簡単かつ効率的にモデル化することができます。ぜひGridDBを使ってデータモデリングをしてみてください。