
GridDB Cloudの完全無料版リリースに伴い、その無料サービスと、数秒で利用開始可能な別の無料クラウドサービスであるGrafana Cloudを組み合わせることにしました。この記事では、GridDB Cloudの共有インスタンスからGrafana Cloudに時系列データを表示する手順を解説します。
GridDB Cloudに不慣れな方は、こちらのクイックスタートガイドをご参照ください: GridDB Cloud クイックスタートガイド — その記事では、GridDB Cloudへの登録方法、利用開始方法、基本的な内容(誰が、何をする、いつ、どこで、なぜ)について説明しています。Grafanaについてもご存知ない場合は、以下のドキュメントでその機能と強みを確認できます:https://grafana.com/docs/grafana/latest/introduction/。
GrafanaがGridDBの体験をどのように向上させるか興味がある方は、以前執筆した記事を参照ください:GrafanaとGridDBを使ってジオメトリデータのヒートマップを作成する。Grafanaの高度な可視化ツールは、データ分析やデータの詳細な分析に創造的なアプローチを可能にします。
この記事の目的はシンプルです:両社のクラウドサービスを利用して、GridDBデータをGrafana Cloudに表示する方法を示すことです。このプロセスをステップバイステップで説明し、途中で発生する特有の注意点も解説していきます。さっそく始めましょう!
実装
まず、この記事で使用する Grafana ダッシュボードのリンクです:https://imru.grafana.net/public-dashboards/8a9f9f8ed9d34582aecca867a50c9613。ソースコードは以下から入手できます:
$ git clone https://github.com/griddbnet/Blogs.git --branch 4_grafana_cloud
事前準備
この記事を再現するには、以下の無料アカウントへのアクセスが必要です: GridDB Cloud、 Grafana Cloud.
技術概要
GrafanaからGridDB Cloudのデータにクエリを実行するには、Grafanaから直接GridDB Cloudに対してHTTPリクエストを送信します。また、無料のGridDB Cloudインスタンスとのあらゆるインタラクションは、Web APIインターフェース経由で行われます。このトピックは、上記リンクのクイックスタートガイドおよびこの記事で詳細に説明されています: GridDB WebAPI. もちろん、公式ドキュメントもご確認ください:GridDB_Web_API_Reference.
GridDBのファイアウォールを回避するために、クエリの形成方法とallowlistの作成方法の詳細は、次の数節で説明します。
GrafanaのIPアドレスをGridDBのallowlistに追加する
Grafana CloudインスタンスがGridDB Cloudによって「安全」と認識されるHTTPリクエストを送信できるようにするには、GridDB Cloudインスタンスにすべての潜在的なIPアドレスを追加する必要があります。Grafanaのドキュメントを確認すると、これらのシナリオ向けにこれらのリストが用意されていることがわかります:https://grafana.com/docs/grafana-cloud/account-management/allow-list/。必要なリストは「 ‘Hosted Grafana’, そして、さっと確認すると、リストは100行を優に超えています。では、これらのすべてをGridDB Cloud管理ポータルに効率的に追加するにはどうすればいいでしょうか?
幸いなことに、このシナリオは以前の記事で既に遭遇しています: GridDB CloudとMicrosoft Azureを使用してサーバーレスのIoT Hubを作成する. この問題を解決するため、私たちはシンプルなBashスクリプトを作成しました。このスクリプトは.txtファイルを入力として受け取り、GridDB Cloudのオンラインポータル内のallowlistに各IPアドレスを追加します。ソースコードと手順は、そのブログの記事内に記載されています。 “ホワイトリストのIPアドレス” セクション。以下がスクリプトです:
#!/bin/bash
file=$1
#EXAMPLE
#runCurl() {
#curl 'https://cloud57.griddb.com/mfcloud57/dbaas/web-api/contracts/m01wc1a/access-list' -X POST -H 'User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10.15; rv:133.0) Gecko/20100101 Firefox/133.0' -H 'Accept: application/json, text/plain, */*' -H 'Accept-Language: en-US,en;q=0.5' -H 'Accept-Encoding: gzip, deflate, br, zstd' -H 'Content-Type: application/json;charset=utf-8' -H 'Access-Control-Allow-Origin: *' -H 'Authorization: Bearer eyJ0eXAiOiJBY2Nlc3MiLCJIUzI1NiJ9.eyJzdWIiOiJkMTg4NjlhZC1mYjUxLTQwMWMtOWQ0Yy03YzI3MGNkZTBmZDkiLCJleHAiOjE3MzEwMTEyMTMsInJvbGUiOiJBZG1pbiIsInN5c3RlbVR5cGUiOjF9.B1MsV9-Nu8m8mJbsp6dKABjJDBjQDdc9aRLffTlTcVM' -H 'Origin: https://cloud5197.griddb.com' -H 'Connection: keep-alive' -H 'Referer: https://cloud5197.griddb.com/mfcloud5197/portal/' -H 'Sec-Fetch-Dest: empty' -H 'Sec-Fetch-Mode: cors' -H 'Sec-Fetch-Site: same-origin' -H 'Priority: u=0' -H 'Pragma: no-cache' -H 'Cache-Control: no-cache' --data-raw $1
#}
runCurl() {
<paste VALUE HERE> $1
}
while IFS= read -r line; do
for ip in ${line//,/ }; do
echo "Whitelisting IP Address: $ip"
runCurl $ip
done
done < "$file"</paste>Grafana CloudからGridDB Cloudへのクエリ
GrafanaはデフォルトでサービスへのHTTPリクエストを送信する機能を備えていますが、私が確認した限りでは、特定のサービス(例:Prometheus)向けに設計されており、HTTP GETリクエストに限定されています。当社の場合、GridDB CloudへのすべてのリクエストはPOSTリクエストを必要とするため、この問題の解決策としてInfinityプラグインを導入しました。
インストール後、これをデータソースとして追加できます。
Infinityをデータソースとして使用する方法
Grafana Cloud インスタンス内で、[Connections] → [Data Sources] を選択します。Infinity データソースを正しくインストールしていれば、このセクションにオプションとして表示されますので、選択してください。ここから、GridDB Cloud の接続に必要な情報をすべて追加できます。基本認証情報を入力し、ポータルのホスト名を許可されたホストリストに追加する必要があります。
追加後、最後に「ヘルスチェック」セクションをクリックし、Web API + 「/checkConnection」(例:https://cloud5197.griddb.com:443/griddb/v2/gs_clustermfcloud5197/dbs/ZV8YUlQ8/checkConnection)を簡単な正常性チェックおよびヘルスチェックとして追加します。保存 & テストをクリックします。
これでGridDBクラウドデータベースにクエリを実行できるはずです! 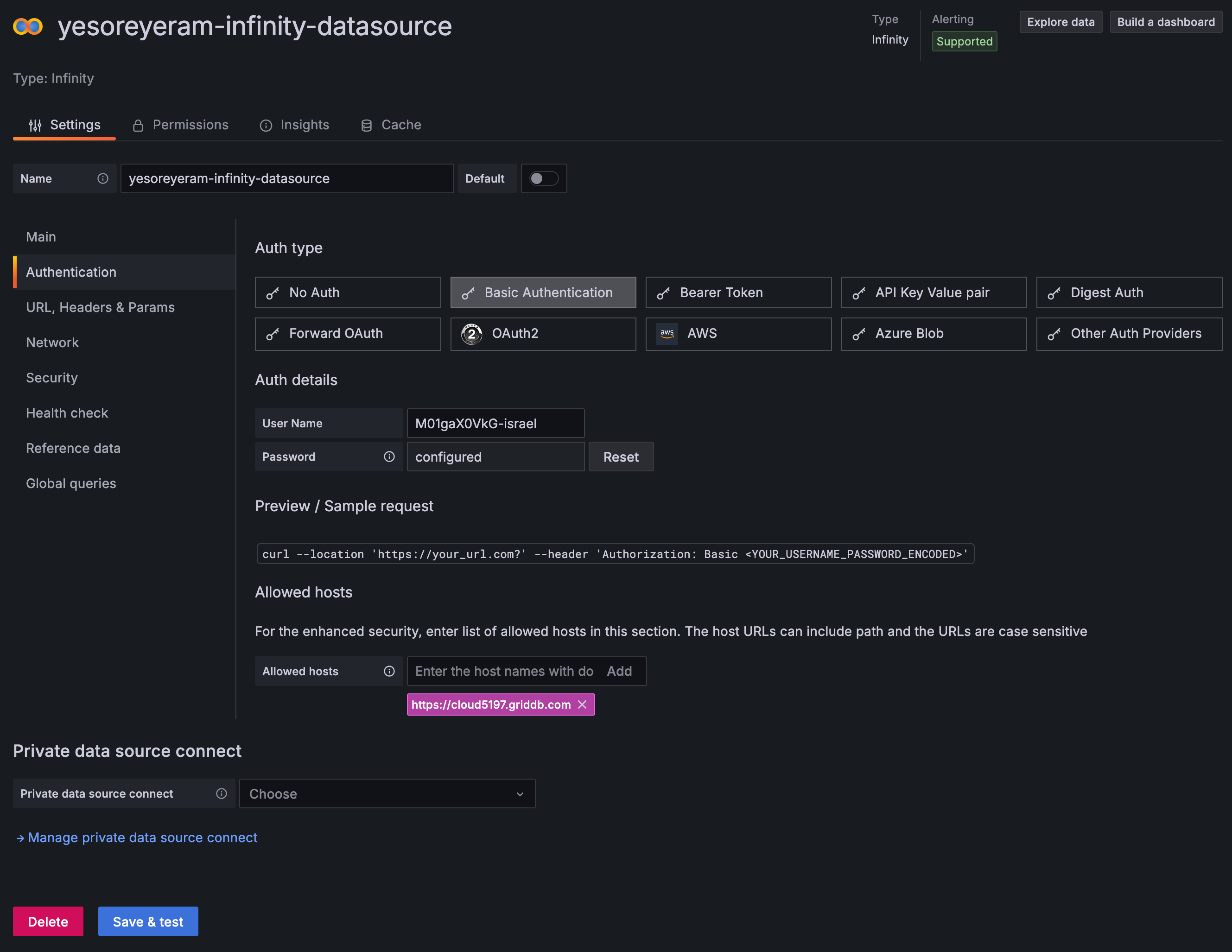
活用可能な時系列データの取り込み
データクエリを実行する前に、まずGridDB Cloudに正常に動作するデータが存在することを確認しましょう。このガイドに沿って進めている方で、新たにアカウントを作成した場合は、Kaggleで入手可能なIoTサンプルデータをインポートするためのクイックスタートガイドに従ってください。ガイドの該当セクションへの直接リンクはこちらです: https://griddb.net/en/blog/griddb-cloud-quick-start-guide/#ingest. ここでは、csv ファイルをインポートし、コンテナ名を device1 と指定しています。
HTTP リクエストの構成
サービス間で通信できるようになったので、必要なデータを取得しましょう。Grafana Cloudのメニューから「ダッシュボード」を選択し、右上角の「新規」をクリックし、最後に「可視化を追加」を選択します。
ここから「Infinity」を選択すると、空白のグラフとクエリを入力する領域が表示されます。
![]()
では、いくつかのオプションをご紹介します:
Type: JSON
Parser: Backend
Source: URL
Format: Data Frame
Method: POST注:以下に、この先で作成するクエリの全体像を示すスクリーンショットを掲載します(スクリーンショットは、すべての単語の意味が理解できた後に、最後に再度表示されます)
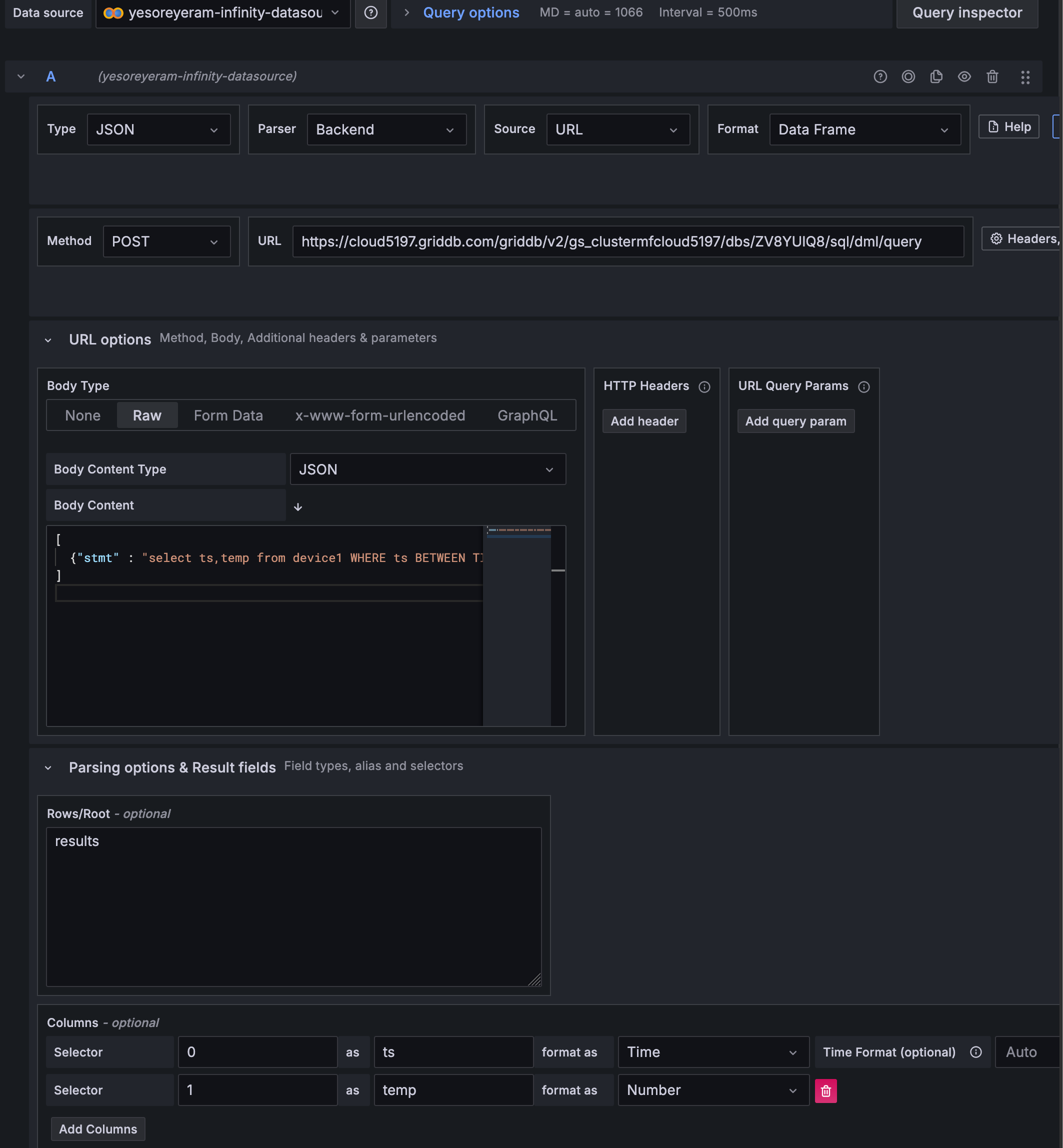
パースとフォーマットの特性により、GridDB Cloudから受け取るデータを適切に命名しラベル付けすることが可能です。これは、GridDB Cloudがリクエストに対してデータを返す方法が独特であるためです。JSON形式でデータ行を返す代わりに(正直なところ、1,000行あれば不要なデータが大量に発生します)、GridDB Cloudは情報をJSONファイルとして返しますが、実際のデータ行は配列形式で格納されており、スキーマは別のJSONキー名(columns)の下にリストされています。
URLについては、上記のリンクでWeb APIリクエストの構成方法をご確認ください。以下に、今回使用する2つのURLを記載します:
- SQL:
https://cloud5197.griddb.com/griddb/v2/gs_clustermfcloud5197/dbs/ZV8YUlQ8/sql/dml/query - API:
https://cloud5197.griddb.com:443/griddb/v2/gs_clustermfcloud5197/dbs/ZV8YUlQ8/containers/device1/rows
各ケースでは、返されるデータのセレクターが異なり、リクエストとして送信するボディペイロードも異なります。まず、SQL クエリを確認しましょう。
シンプルな SQL 選択クエリの作成
まず、URL を上記のクエリと一致するように設定します。フォーマットは次のとおりです: https://[cloud-portal-name].griddb.com/griddb/[clustername]/dbs/[database-name]/sql/dml/query。その後、リクエストの本文内に SQL クエリを記述します。
これを正しくパースするため、フォーマットをデータフレームに設定し、パースオプション & 結果フィールド の JSONata/行セレクター ボックスに「results」と入力し、列を追加 をクリックします。最初はデータセットからいくつかの列を取得したいので、列を次のように設定します:
Selector: 0 #array index
as: ts
format-as: Time次に、グラフで追跡したい列を選択します。ここではtemperatureを見てみましょう。
Selector: 7
as: temperature
format-as: Number最後に、これはPOSTリクエストであるため、リクエスト本文内に何かを送信する必要があります。ただし、今回はSQLクエリを送信します。メソッドドロップダウンメニューのすぐ下に「ヘッダー、本文、リクエストパラメーター」というボタンがあります。このボタンをクリックします。
そのサブメニューで、ボディタイプを「Raw」に設定し、ボディコンテンツタイプを「JSON」に設定します。大きなテキストボックスに、実際のボディ(この場合はSQLクエリ)を入力できます:
[
{"stmt" : "select * from device1 LIMIT 1000"}
]注:クエリに制限を設定することを強くおすすめします。そうしないと、Grafanaがすべてのデータポイントを表示しようとして正常に動作しない可能性があります。
上記のグラフで必要に応じて「データにズームイン」をクリックすると、データが表示されます!
より高度なSQLクエリ(範囲によるグループ化、集計)
GridDB 5.7の登場により、より複雑なSQLクエリを実行できるようになり、SELECT文に限定されなくなりました。例えば、SQLの「範囲によるグループ化」を使用すると、指定した時間範囲内の集計操作を実行できます。例えば、以下のクエリが該当します: select ts,temp from device1 WHERE ts BETWEEN TIMESTAMP('2020-07-12T01:00:25.984Z') AND TIMESTAMP('2020-07-12T01:22:29.050Z') GROUP BY RANGE (ts) EVERY (1, SECOND) FILL (LINEAR). このクエリをInfinityプラグインに直接入力して結果を確認できます(ヒント: 列選択を調整したり、グラフを再読み込みする必要があるかもしれません)。
その他のSQL集計クエリも実行可能です。制限はありません。詳細については、GridDB SQLドキュメントをご参照ください: https://griddb.org/docs-en/manuals/GridDB_SQL_Reference.html
Group By Range機能は、データセットが十分に密集していなくても、密集したグラフを作成するのに非常に便利です!
API クエリ
SQL を省略し、API のみを使用して、リクエストの本文にシンプルな JSON オプションを指定してクエリを実行できます。URL は次のように構築されます: https://[cloud-portal-name].griddb.com/griddb/[clustername]/dbs/[database-name]/containers/[container-name]/rows
URLを入力し、ボディのコンテンツタイプをJSONに設定し、ボディの内容に以下の組み合わせのいずれかを入力してください:
{
"offset" : 0,
"limit" : 100,
"condition" : "temp >= 30",
"sort" : "temp desc"
}ご覧のとおり、データセットの条件と並べ替えオプションを設定します。列オプションは同じままですが、データの出力結果が「行」と呼ばれるようになったため、Parsing Options & Result Fields セクションでそのオプションを変更してください。列セレクターは同じままにしておいて構いません。
結論
データクエリとデータの追加が完了したら、もちろんダッシュボードを保存して後で利用できます。以上です!手順に従って進めた場合、GridDB CloudとGrafana Cloudを連携させてデータを表示する方法を習得できました。
If you have any questions about the blog, please create a Stack Overflow post here https://stackoverflow.com/questions/ask?tags=griddb .
Make sure that you use the “griddb” tag so our engineers can quickly reply to your questions.