
以前のブログで、サンプルIoTデータセットをPostgreSQLからGridDBに移行する方法について説明しました。その際、GridDBの公式インポート・エクスポートツールを使用し、ツールの使用方法と、PostgreSQLからGridDBに移行するべき理由についても説明しました。その内容はこちらのブログでご覧いただけます。GridDBインポート・エクスポートツールを使ってPostgreSQLからGridDBへ移行する。
今回は、PostgreSQLからGridDBに移行する際に、インポート・エクスポートツールではなくApache Airflowを使う方法を紹介します。ご存じない方のために説明すると、Airflowはワークフローをプログラム的に作成、スケジュール、監視するためのプラットフォームです。Airflowは、Pythonのコードを使ってワークフローをスケジュールすることができます。これらのワークフローは通常、小さなタスクに分割され、選択した順序で実行されるように並べ替えることができます。
今回のブログでは、前回のブログと同じデータセットをAirflowを使って移行します。また、PostgeSQLからGridDBへ定期的に新しい行を移行するためのDAG ( Directed Acyclic Graph ) をスケジュールし、2つのデータベースが常に同等であることを確認します。(少なくともスケジュールした間隔以降はそうなるでしょう。)
このプロジェクトの技術的な手順を始める前に、まずAirflowをマシンにインストールし、すべての前提条件も揃えておきましょう。
準備とインストール
このセクションでは、前述のように、このプロジェクトをあなたのマシンにインストールする方法について説明します。Airflowの良いところは、インストール、共有、およびインストールの拡張を簡単に実現するためのdockerイメージを提供していることです。この記事は、DockerコンテナでAirflowを使用することから動作しますが、それについては後で詳しく説明します。
前提条件
このブログの手順をフォローするには、以下のものが必要です。
他のデータベースやライブラリはすべてdockerコンテナでインストールします。
ソースコードを取得する
このプロジェクトのすべてのソースコードを取得するには、以下のリポジトリGitHubをクローンしてください。
$ git clone https://github.com/griddbnet/Blogs.git --branch apache_airflowクローン化されると、プロジェクトを始めるのに必要なdockerファイルやコードが入ったフォルダができます。
Dockerコンテナについて
まず、上記で共有されたリポジトリに含まれるDockerfileを確認し、プロジェクトを実行する前に docker-compose ファイルについて説明します。
Airflowイメージを拡張するためのDockerfile
まず、Dockerfile.airflowというファイルがあることに気がついたかもしれません。このファイルは、オリジナルの apache/airflow イメージを 拡張 して、このプロジェクトに必要な Python ライブラリをいくつか追加しています。
ファイルはこのようになります。
FROM apache/airflow:latest-python3.10
COPY requirements.txt /requirements.txt
USER root
RUN apt-get update \
&& apt-get install -y --no-install-recommends \
default-jre wget build-essential swig \
&& apt-get autoremove -yqq --purge \
&& apt-get clean \
&& rm -rf /var/lib/apt/lists/*
RUN wget https://repo1.maven.org/maven2/com/github/griddb/gridstore-jdbc/5.1.0/gridstore-jdbc-5.1.0.jar -P /usr/share/java
# Install GridDB c_client
WORKDIR /
RUN wget --no-check-certificate https://github.com/griddb/c_client/releases/download/v5.0.0/griddb-c-client_5.0.0_amd64.deb
RUN dpkg -i griddb-c-client_5.0.0_amd64.deb
USER airflow
RUN pip install --user --upgrade pip
RUN pip install --no-cache-dir --user -r /requirements.txt
RUN pip install --no-cache-dir apache-airflow-providers-common-sql
RUN pip install --no-cache-dir apache-airflow-providers-jdbc
RUN pip install --no-cache-dir griddb-python
ENV JAVA_HOME=/usr/share/java/gridstore-jdbc-5.1.0.jarまず、今回のプロジェクトでは、JDBCとGridDB Pythonクライアントをインストールします。このプロジェクトの残りで実際にJDBCを使用することはありませんが、JDBCはSQLをフルに使用することができ、将来のプロジェクトで便利になる可能性があるため含まれています。JDBCを使った接続については、後ほど詳しく説明します。
GridDB Pythonクライアントをインストールするためには、python3.10が必要であり、そのためにapache/airflow:latest-python3.10を拡張することにしました。GridDB Python Clientをインストールすることで、TQL経由でGridDBにアクセスし、Pythonスクリプトで直接GridDBを利用する作業ができるようになります 。これはPostgreSQLではなくGridDBを使う大きなメリットの1つであると言えるでしょう。
GridDBイメージを拡張するためのDockerfile
次にここで紹介したいのは、Dockerfile.griddbというファイルです。以下はその内容です。
from griddb/griddb
USER root
# Install GridDB c_client
WORKDIR /
RUN wget --no-check-certificate https://github.com/griddb/c_client/releases/download/v5.0.0/griddb-c-client_5.0.0_amd64.deb
RUN dpkg -i griddb-c-client_5.0.0_amd64.deb
RUN wget --no-check-certificate https://github.com/griddb/cli/releases/download/v5.0.0/griddb-ce-cli_5.0.0_amd64.deb
RUN dpkg -i griddb-ce-cli_5.0.0_amd64.deb
USER gsadmGridDBの基本イメージを拡張し、他のGridDBライブラリの前提条件としてGridDB C-Clientを追加しています。また、必要に応じてDBに簡単に問い合わせができるようにGridDB CLIツールも追加しています。
AirflowのDocker-Composeファイル
このファイルにはAirflowツールを実行するために必要なすべての異なるサービス・コンテナが含まれています。このファイルには、Airflowツールの実行に必要なすべての異なるサービス・コンテナが含まれています。docker-composeを使用することの良い点は、ファイル内のすべてのサービスが自動的に共有ネットワークスペースに配置されることです。それだけでなく、自分たちで拡張したイメージも含めて、1つのコマンドですべてのサービスを立ち上げたり、下げたりすることができ、とても便利です。
ファイルが本当に大きいので、ここではその一部を紹介します。
---
version: '3'
x-airflow-common:
&airflow-common
image: ${AIRFLOW_IMAGE_NAME:-extending_airflow:latest}
environment:
&airflow-common-env
AIRFLOW__CORE__EXECUTOR: CeleryExecutor
AIRFLOW__DATABASE__SQL_ALCHEMY_CONN: postgresql+psycopg2://airflow:airflow@postgres/airflow
# For backward compatibility, with Airflow <2.3
AIRFLOW__CORE__SQL_ALCHEMY_CONN: postgresql+psycopg2://airflow:airflow@postgres/airflow
AIRFLOW__CELERY__RESULT_BACKEND: db+postgresql://airflow:airflow@postgres/airflow
AIRFLOW__CELERY__BROKER_URL: redis://:@redis:6379/0
AIRFLOW__CORE__FERNET_KEY: ''
AIRFLOW__CORE__DAGS_ARE_PAUSED_AT_CREATION: 'true'
AIRFLOW__CORE__LOAD_EXAMPLES: 'true'
AIRFLOW__API__AUTH_BACKENDS: 'airflow.api.auth.backend.basic_auth'
_PIP_ADDITIONAL_REQUIREMENTS: ${_PIP_ADDITIONAL_REQUIREMENTS:-}
volumes:
- ./dags:/opt/airflow/dags
- ./logs:/opt/airflow/logs
- ./plugins:/opt/airflow/plugins
user: "${AIRFLOW_UID:-50000}:0"
depends_on:
&airflow-common-depends-on
redis:
condition: service_healthy
postgres:
condition: service_healthy
griddb-server:
build:
context: .
dockerfile: Dockerfile.griddb
expose:
- "10001"
- "10010"
- "10020"
- "10040"
- "20001"
- "41999"
environment:
NOTIFICATION_MEMBER: 1
GRIDDB_CLUSTER_NAME: myCluster
postgres:
image: postgres:13
environment:
POSTGRES_USER: airflow
POSTGRES_PASSWORD: airflow
POSTGRES_DB: airflow
volumes:
- postgres-db-volume:/var/lib/postgresql/data
- ./dags:/var/lib/postgresql/dags
ports:
- 5432:5432
healthcheck:
test: ["CMD", "pg_isready", "-U", "airflow"]
interval: 5s
retries: 5
restart: always
airflow-webserver:
<<: *airflow-common
command: webserver
ports:
- 8080:8080
healthcheck:
test: ["CMD", "curl", "--fail", "http://localhost:8080/health"]
interval: 10s
timeout: 10s
retries: 5
restart: always
depends_on:
<<: *airflow-common-depends-on
airflow-init:
condition: service_completed_successfullyこのファイルには、今回紹介する2つのデータベースを含む様々なコンテナを実行するための手順が含まれています。また、GridDBサービスがローカルの Dockerfile.griddb ファイルから直接ビルドされています。Airflowがこのリポジトリに独自のDockerfileを持っているにもかかわらず、同じ扱いを受けていないことに気がついた方もいるかもしれません。
その理由は、オリジナルの Airflow compose オーケストレーションファイルでは、多くの異なるサービス間でこのファイルとの一貫性を保つために x-airflow-common 環境変数を使用しているからです。このようなdocker-composeファイルの構築とうまくやるためには、composeファイルがこのプロジェクトの目的のためにその構築済みのイメージを使用できるように、ローカルにイメージを構築する必要があります。
Dockerコンテナを実行する
上で述べた通り、まず最初に Dockerfile.airflow イメージのビルドを行い、それが完了したら、docker-compose コマンドを使ってすべてを一度に実行することができるようになります。
$ docker build -f Dockerfile.airflow . --tag extending_airflow:latestこのイメージがビルドされると、ローカル環境($ docker images)に extending_airflow:latest イメージが表示されるようになります。
これで準備ができ、すべてのサービスを実行することができるようになりました。
$ docker-compose up -d[+] Running 8/8
⠿ Container griddb-airflow Running 0.0s
⠿ Container airflow-redis-1 Healthy 18.6s
⠿ Container postgres-airflow Healthy 18.6s
⠿ Container airflow-airflow-init-1 Exited 37.2s
⠿ Container airflow-airflow-triggerer-1 Started 37.9s
⠿ Container airflow-airflow-scheduler-1 Started 37.9s
⠿ Container airflow-airflow-worker-1 Started 37.9s
⠿ Container airflow-airflow-webserver-1 Started 37.5s
これは、dockerhubから関連するすべてのイメージを取得するか、ローカルでイメージを構築(Dockerfile.griddb)します。準備が整うと、すべてのコンテナがあなたのマシン上で直接実行されるようになります。
これは、process statusコマンドを実行して確認することができます。
$ docker psCONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
ad1511b22415 extending_airflow:latest "/usr/bin/dumb-init …" About a minute ago Up About a minute (healthy) 0.0.0.0:8080->8080/tcp, :::8080->8080/tcp 3_airflow_migration-airflow-webserver-1
68bdef86bf4f extending_airflow:latest "/usr/bin/dumb-init …" About a minute ago Up About a minute (healthy) 8080/tcp 3_airflow_migration-airflow-scheduler-1
b020473ce932 extending_airflow:latest "/usr/bin/dumb-init …" About a minute ago Up About a minute (healthy) 8080/tcp 3_airflow_migration-airflow-triggerer-1
69c99ea8ce87 extending_airflow:latest "/usr/bin/dumb-init …" About a minute ago Up About a minute (healthy) 8080/tcp 3_airflow_migration-airflow-worker-1
9c778c1f1d72 3_airflow_migration_griddb-server "/bin/bash /start-gr…" About a minute ago Up About a minute 10001/tcp, 10010/tcp, 10020/tcp, 10040/tcp, 20001/tcp, 41999/tcp griddb-airflow
921cc78b8c1b redis:latest "docker-entrypoint.s…" About a minute ago Up About a minute (healthy) 6379/tcp 3_airflow_migration-redis-1
0ba780dd6b99 postgres:13 "docker-entrypoint.s…" About a minute ago Up About a minute (healthy) 0.0.0.0:5432->5432/tcp, :::5432->5432/tcp postgres-airflow
Apache Airflowを使用する
さて、ツールを立ち上げて実行したところで、次にやりたいことはもちろん、ツールとのインターフェイスです。docker-compose ファイル内のコンテナ・サービスの 1 つは、ワークフローを管理するための優れた UI を備えた Web サーバーをホストしています。
ブラウザで http://localhost:8080/ にアクセスし、認証情報を入力します。(ユーザー名とパスワードはどちらも airflow です。)ここから、事前に作成されたDAGの大きなリストが表示されます。これらは、データフローをオーケストレーションするために管理されるワークフローです。今回のケースでは、Postgresqlの全データを1回で移行するためのDAGと、継続的に移行するためのDAGの2種類を作成したいと思います。
その前に、新しく作成したPostgreSQLデータベースに、移行したいデータがあることを確認しておきましょう。
Airflow UI を使用してデータベースと接続する
Pythonのコード(DAG)を書く前に、まずAirflowのスケジューラー・ワーカー・ウェブサーバーがGridDBサーバーやPostgreSQLデータベースと対話できることを確認しましょう。先に説明したように、これらのサービスはすべてdocker-composeファイルを共有しているため、自動的にすべて同じネットワーク空間を共有することになります。
まず、PostgreSQLに接続してみましょう。
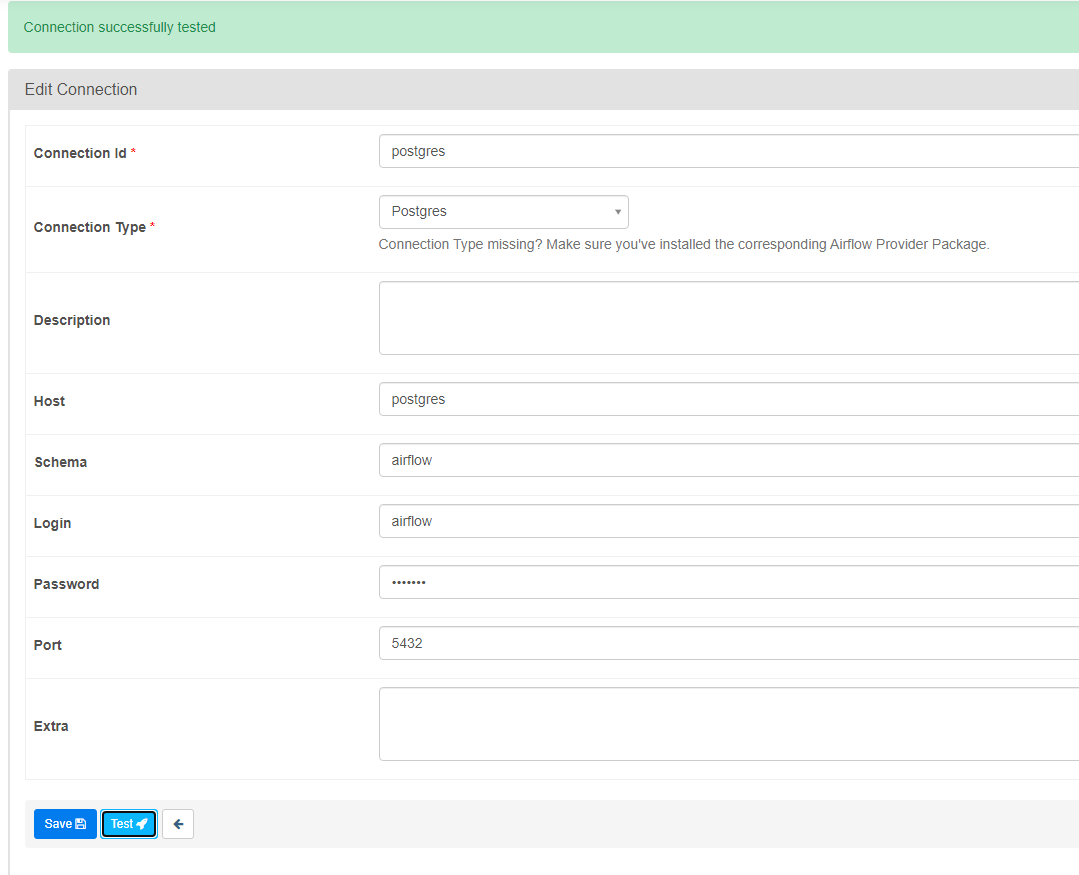
PostgreSQLに接続する
ではまず、PostgreSQLのデータベースに接続してみましょう。
ブラウザでAdmin –> Connectionsに移動します。
ここで、対象となるデータベースへの明示的な接続を行うことができます。PostgreSQLの場合は、接続の種類のドロップダウンから選択し、認証情報を入力します。
Host: postgres
Schema: airflow
Login: airflow
Password: airflow
Port: 5432testを押したら、成功したと表示されるはずです。hostはdocker-composeファイル内のサービス名です。(サービス名はホスト名で、共有ネットワークではIPアドレスに相当します。)
GridDBに接続する
GridDBに接続するには、上記の方法と同じようにJDBCで接続することができます。
Connection Type: JDBC Connection
Connection URL: jdbc:gs://griddb-server:20001/myCluster/public
Login: admin
Password: admin
Driver Path: /usr/share/java/gridstore-jdbc-5.1.0.jar
Driver Class: com.toshiba.mwcloud.gs.sql.Driver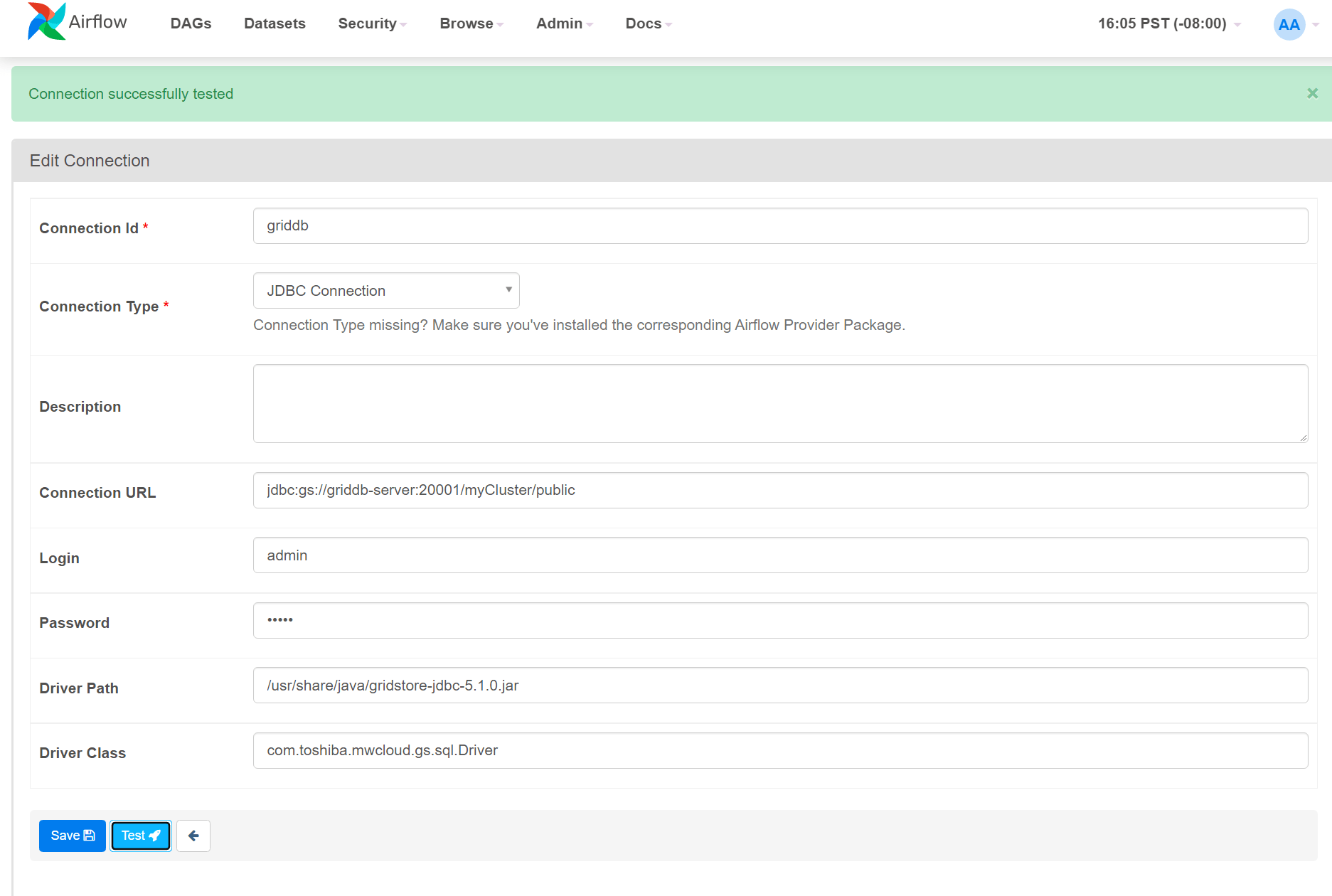
他に、Pythonクライアントで接続することも可能です。
import griddb_python as griddb
factory = griddb.StoreFactory.get_instance()
DB_HOST = "griddb-server:10001" #griddb-server is the hostname of the service
DB_CLUSTER = "myCluster"
DB_USER = "admin"
DB_PASS = "admin"
gridstore = factory.get_store(
notification_member=DB_HOST, cluster_name=DB_CLUSTER, username=DB_USER, password=DB_PASS
)上記のPythonコードは、GridDBを利用しようとするPython DAGの内部に挿入されるだけで、UIのConnectionsタブで明示されるわけではありません。
PostgreSQLコンテナデータベースにデータを取り込む
このデモでは、CSVをPostgreSQLコンテナにコピーし、COPYコマンドを使用して、必要な関連データをデータベースに取り込みます。
まず最初に、ローカルマシンからPostgreSQLコンテナへ.csvファイルをコピーします。これはdocker-composeファイルによって命名されたイメージ名(airflow-postgres-1)とdocker cpコマンドを使用することによって実現できます。コピーするファイルは、dags/data/device.csvの中にあります。
$ docker cp dags/data/device.csv postgres-airflow:/tmp/docker cp コマンドは、通常のCLI操作における scp や cp コマンドと同様に実行されます。
csvファイルをコピーしたら、PostgreSQLコンテナにsshします。
$ docker exec -it airflow-postgres-1 bashそこに入ったら、ユーザーairflowとしてpsql shellにドロップします。
# psql -U airflow
psql (13.9 (Debian 13.9-1.pgdg110+1))
Type "help" for help.
airflow=#ここから簡単にCSVデータをDBに取り込むことができます。まず、テーブルを作成し、CSVの行をそのテーブルにコピーするようにデータベースに指示します。
airflow=# CREATE TABLE if not exists device ( ts timestamp, device varchar(30), co float8, humidity float8, light bool, lpg float8, motion bool, smoke float8, temp float8 );CREATE TABLE
そして、すべてを COPY します。
airflow=# copy device(ts, device, co, humidity, light, lpg, motion, smoke, temp) from '/tmp/device.csv' DELIMITER ',' CSV HEADER;PostgreSQLからGridDBへ移行する
ここで、GridDBへの移行のための最初のDAGを作成します。AirflowはPythonで構築されているため、DAGは単純にPythonコードといくつかの簡単なAirflow定型文で構成されています。ファイルスニペットに入る前に、筆者はGridDB Pythonクライアントを使用しているので、筆者のAirflow DAGの中から直接GridDBデータベースと簡単にインターフェースできることを特筆しておきます。そのため、関係するコードを見ても、その多くは通常のPythonアプリケーションとあまり変わりません。
エアフロー専用Pythonコード
ここに筆者のGridDB Migration DAGのスニペットがあります。この最初の部分は、コードのAirflow固有の部分のみを紹介することに留めておきます。まず、Airflowのライブラリをインポートします。
from airflow import DAG
from airflow.providers.postgres.operators.postgres import PostgresOperator
from airflow.hooks.postgres_hook import PostgresHook
from airflow.operators.python import PythonOperator
default_args = {
'owner': 'israel',
'retries': 5,
'retry_delay': timedelta(minutes=5)
}
with DAG(
dag_id='dag_migrating_postgres_to_griddb_v04',
default_args=default_args,
start_date=datetime(2021, 12, 19),
schedule_interval='@once'
) as dag:
task1 = PythonOperator(
task_id='migrate_from_postgres_to_griddb',
python_callable=migrate_from_postgres_to_griddb
)
task1これが終わったら、DAGの設定オプション、つまりID(名前)と、このタスクを実行するための選択した間隔を入力します。このDAGについて一つ指摘しておくと、スケジュールされた間隔は単に@onceであり、つまりこのDAGを一度実行すると、再度実行するためのスケジュールは組まれないことに注意してください。
次に、ファイルの一番下で、どのようなタスクをどのような順序で実行するかを選択します。このワークフローでは、task1という1つのタスクを呼び出すだけで、pythonの関数 migrate_from_postgres_to_griddb が呼び出されます。
PostgreSQLに問い合わせ、関連するすべてのデータを取得し、必要に応じて変換して、GridDBサーバにputします。
DAG 内で PostgreSQL を接続、クエリする
ここでは、実際のマイグレーションを処理するPython関数を紹介します。
def migrate_from_postgres_to_griddb(**context):
"""
Queries Postgres and places all data into GridDB
"""
gridstore = factory.get_store(
notification_member=DB_HOST, cluster_name=DB_CLUSTER, username=DB_USER, password=DB_PASS
)
postgres = PostgresHook(postgres_conn_id="postgres")
conn = postgres.get_conn()
cursor = conn.cursor()
cursor.execute("SELECT * FROM device;")前回のブログと同様に、PostgreSQLのテーブルをそのままGridDBのデータベース内に配置するのではなく、よりIoTに特化したスキーマを採用しています。IoTに特化したスキーマで、データセットの各センサーがそれぞれコンテナ(テーブル)を持っています。まずは各データベースに必要な接続を行います。
PostgreSQLに接続するには、このブログで以前に確立した接続から直接引き出すことができます。DAG内でこれを行うには、Dockerfile.airflowファイルでコンテナに導入したPostgresHook pythonライブラリをインポートします。そして、Postgresの接続IDpostgres = PostgresHook(postgres_conn_id="postgres")を指定します。
接続が完了したら、カーソルを使ってクエリを実行することができます。この場合、 device テーブルからすべてのデータを取得します。
GridDBに接続する
GridDB サーバへの接続は、PostgreSQL と同様に JdbcHook を利用する方法と、GridDB Python クライアントを利用する方法があります。Pythonクライアントを利用することで、他のPythonアプリケーションと同様に利用することができ、使い勝手が良いので、この方法を利用することにします。接続の詳細については、これらのサービスは docker-compose 環境を共有しているため、単純にホスト名を使用します。
factory = griddb.StoreFactory.get_instance()
DB_HOST = "griddb-server:10001"
DB_CLUSTER = "myCluster"
DB_USER = "admin"
DB_PASS = "admin"
gridstore = factory.get_store(
notification_member=DB_HOST, cluster_name=DB_CLUSTER, username=DB_USER, password=DB_PASS
)残りの詳細は、FIXED_LISTモードのGridDBで使用されるデフォルトのものです。また、Dockerコンテナの外でGridDBを使ってPythonのコードを書く場合にも、DB_HOSTを適切なIPアドレスに置き換えるだけで同じように接続できます。(ポートはそのままです。)
接続が完了したら、PostgreSQLから行を変換して、その行をGridDBに配置してみましょう。
GridDBでコンテナを作成する
上記で説明したように、PostgreSQL からすべての行を取り出し、GridDB 側で 3 つの異なるコンテナに分割する必要があります。元のデータセットに含まれる一意のデバイス名が、新しい時系列コンテナのキーになるはずです。Pythonのコードを使って、DAGの中で実現できます。また、作成時にスキーマを設定することも可能です。
def create_container(gridstore, device_name):
gridstore.drop_container(device_name)
conInfo = griddb.ContainerInfo(name=device_name,
column_info_list=[["ts", griddb.Type.TIMESTAMP],
["co", griddb.Type.DOUBLE],
["humidity", griddb.Type.DOUBLE],
["light", griddb.Type.BOOL],
["lpg", griddb.Type.DOUBLE],
["motion", griddb.Type.BOOL],
["smoke", griddb.Type.DOUBLE],
["temperature", griddb.Type.DOUBLE]],
type=griddb.ContainerType.TIME_SERIES)
# Create the container
try:
gridstore.put_container(conInfo)
print(conInfo.name, "container successfully created")
except griddb.GSException as e:
for i in range(e.get_error_stack_size()):
print("[", i, "]")
print(e.get_error_code(i))
print(e.get_location(i))
print(e.get_message(i))ここでは、column_info_listにあるようなスキーマを持つコンテナを作成することにします。この関数は、センサーごとに3回実行する必要があるため、独立した関数に分割しています。
最終的には以下のようなシンプルなものを実行します。
container_name_list = ["device1", "device2", "device3"]
for container_name in container_name_list:
create_container(gridstore, container_name)GridDBへの取り込みのためにPostgreSQLからデータを変換する
では最後に、元のデータをdataframeに配置し、操作や分割がしやすいようにします。そこから、行を含む新しいオブジェクトをGridDBに入れます。
cursor.execute("SELECT * FROM device;")
import pandas as pd
rows = pd.DataFrame(cursor.fetchall())
dfs = dict(tuple(rows.groupby([1])))
device1 = dfs['b8:27:eb:bf:9d:51']
device1 = device1.drop([1], axis=1)
device1 = device1.values.tolist()
device2 = dfs['00:0f:00:70:91:0a']
device2 = device2.drop([1], axis=1)
device2 = device2.values.tolist()
device3 = dfs['1c:bf:ce:15:ec:4d']
device3 = device3.drop([1], axis=1)
device3 = device3.values.tolist()各 deviceX オブジェクトは multi_put で GridDB に直接配置できるすべての行を含みます。
try:
d1_cont = gridstore.get_container("device1")
d1_cont.multi_put(device1)
d2_cont = gridstore.get_container("device2")
d2_cont.multi_put(device1)
d3_cont = gridstore.get_container("device3")
d3_cont.multi_put(device1)
except griddb.GSException as e:
for i in range(e.get_error_stack_size()):
print("[", i, "]")
print(e.get_error_code(i))
print(e.get_location(i))
print(e.get_message(i))そこからGridDBのデータベースには、Kaggleのデータセットから関連するすべてのセンサー情報が入った3つの新しいコンテナが追加されるはずです。
継続的なマイグレーション
データベースが揃ったところで、次のステップに進みましょう。例えば、センサーのデータがPostgreSQLに送信され続けていて、それをGridDBに送信したいとします。定期的にスケジュールされたDAGを使えば、すべての新しい行がGridDBにプッシュされるようにすることができます。
各センサーのコンテナに問い合わせ、データの最新(MAX)のタイムスタンプを見つけ、それをPostgreSQLでクロスリファレンスします。PostgreSQLでデータが新しいか「大きい」場合、問題のある行をすべて取り出し、適切なコンテナにプッシュします。
GridDBでMAXタイムスタンプをクエリする
GridDBへの接続が完了したら、クエリを作成します。この場合、TQLはコンテナ単位で動作するため、クエリ自体にコンテナ名を指定する必要はありません。つまり、1つの文字列を作成するだけで、すべてのコンテナで再利用することができます。
try:
d1_cont = gridstore.get_container("device1")
d2_cont = gridstore.get_container("device2")
d3_cont = gridstore.get_container("device3")
sql = "SELECT MAX(ts)"
d1_query = d1_cont.query(sql)
d2_query = d2_cont.query(sql)
d3_query = d3_cont.query(sql)ここでは、コンテナ内の絶対的な最新のタイムスタンプ(ts)を見つけるMAXのTQL集計クエリを使用しています。
GridDB のタイムスタンプ値を使って PostgreSQL へクエリを実行する
その値が保存されたら、それを使ってPostgreSQLにクエリを実行します。
d1_rs = d1_query.fetch()
d2_rs = d2_query.fetch()
d3_rs = d3_query.fetch()
d1_row = d1_rs.next().get(griddb.Type.TIMESTAMP)
d1_latest_time = d1_row.replace(microsecond=999999) # adding in max microseconds as GridDB does not save these values
d2_row = d2_rs.next().get(griddb.Type.TIMESTAMP)
d2_latest_time = d2_row.replace(microsecond=999999)
d3_row = d3_rs.next().get(griddb.Type.TIMESTAMP)
d3_latest_time = d3_row.replace(microsecond=999999)
d1_sql = "SELECT DISTINCT ON (ts) * FROM device WHERE ts > '" + str(d1_latest_time)+ "' AND device = 'b8:27:eb:bf:9d:51' ORDER BY ts DESC;"
d2_sql = "SELECT DISTINCT ON (ts) * FROM device WHERE ts > '" + str(d2_latest_time)+ "' AND device = '00:0f:00:70:91:0a' ORDER BY ts DESC;"
d3_sql = "SELECT DISTINCT ON (ts) * FROM device WHERE ts > '" + str(d3_latest_time)+ "' AND device = '1c:bf:ce:15:ec:4d' ORDER BY ts DESC;"
cursor.execute(d1_sql)
d1_result = cursor.fetchall()
cursor.execute(d2_sql)
d2_result = cursor.fetchall()
cursor.execute(d3_sql)
d3_result = cursor.fetchall()これで、GridDBの対応するオブジェクトよりも後に行を格納する3つの異なるオブジェクトができました。次に、リストが空かどうかをチェックし、空でなければGridDBに行を配置します。
if not d1_result:
print("Device1 contains 0 new rows to add")
else:
print(d1_latest_time)
print(d1_sql)
print("Device1 contains " + str(len(d1_result)) + " new rows to add")
for row in d1_result:
print("putting row to device1 in GridDB")
row = list(row)
del row[1] #get rid of device name
print(row)
d1_cont.put(row)
if not d2_result:
print("Device2 contains 0 new rows to add")
else:
print(d2_latest_time)
print(d2_sql)
print("Device2 contains " + str(len(d2_result)) + " new rows to add")
for row in d2_result:
print("putting row to device2 in GridDB")
row = list(row)
del row[1] #get rid of device name
print(row)
d2_cont.put(list(row))
if not d3_result:
print("Device3 contains 0 new rows to add")
else:
print("Device3 contains " + str(len(d3_result)) + " new rows to add")
print(d3_latest_time)
print(d3_sql)
for row in d3_result:
print("putting row to device3 in GridDB")
row = list(row)
del row[1]
print(row)
d3_cont.put(list(row))DAGの準備ができたので、UIに向かいこれらをオンにして、実行され期待通りに動くかどうかを確認します。
DAGを起動し結果を確認する
Let’s head back over to the UI and activate these DAGs. Our DAG which simply does an initial bulk migration is scheduled to run only once. Let’s turn that one on and make sure it runs. Use the search bar search DAGs and search GridDB.
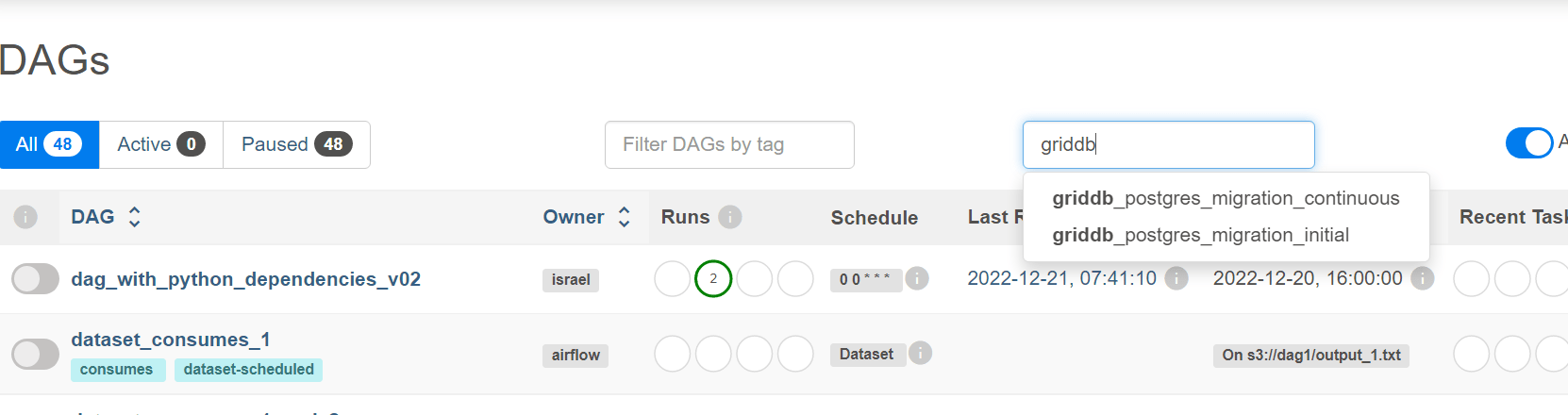
まず、griddb_postgres_migration_initialというIDのDAGをオンにしてみましょう。クリックすると、名前の横に小さなスイッチがあり、そこでオン・オフを切り替えることができます。
開始日を過去に設定し、スケジュール間隔を1回に設定したため、一度オンにすると、すぐに実行され、その後、停止します。ログを確認するには、グラフボタンをクリックし、DAGマップの中から自分のタスクを探します。タスクは1つだけなので、空間上にある小さな四角が1つあるだけです。
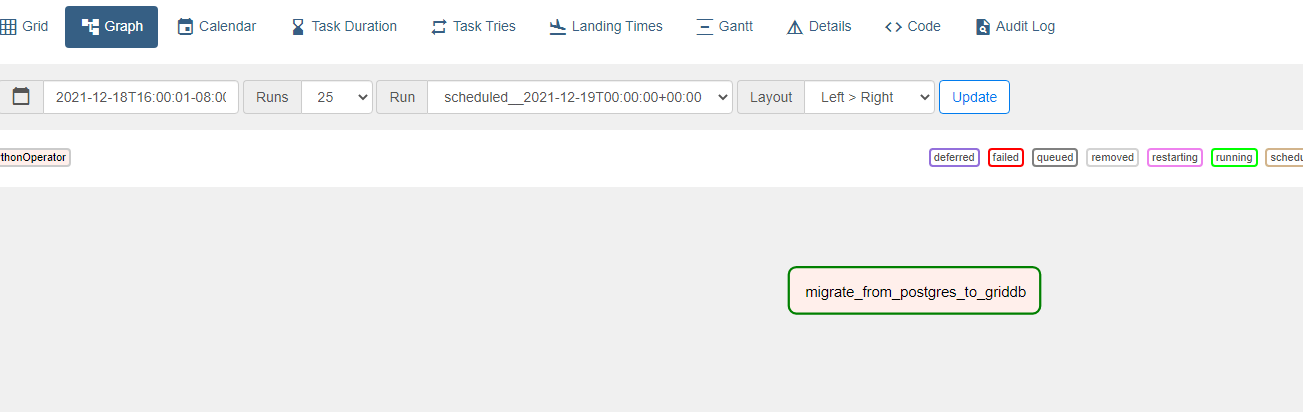
そこから、上部のログボタンをクリックします。もしDAGの結果が期待通りでない場合は、スケジューリングに時間を掛けたり再実行を待つ代わりに、クリアボタンをクリックすると、DAGが自動で再実行されます。
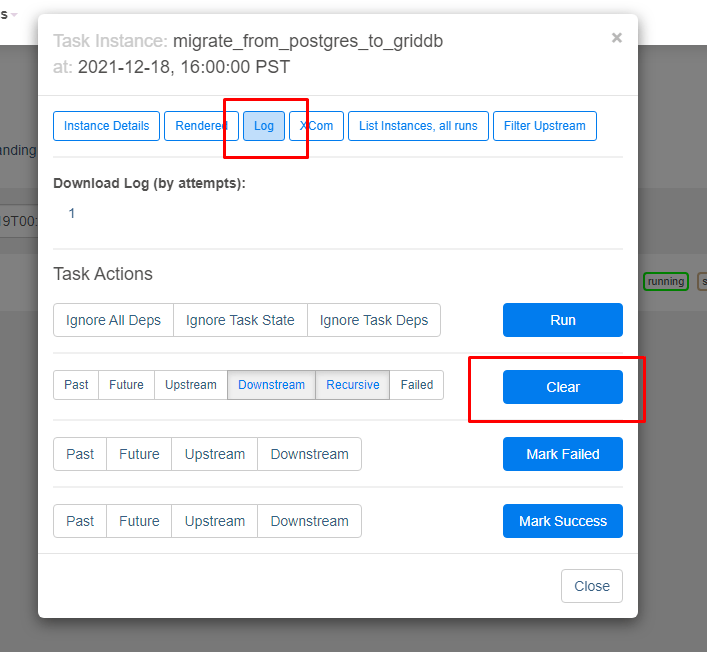
そして、今度はログを見て、タスクが正常に完了したかどうかを確認します。
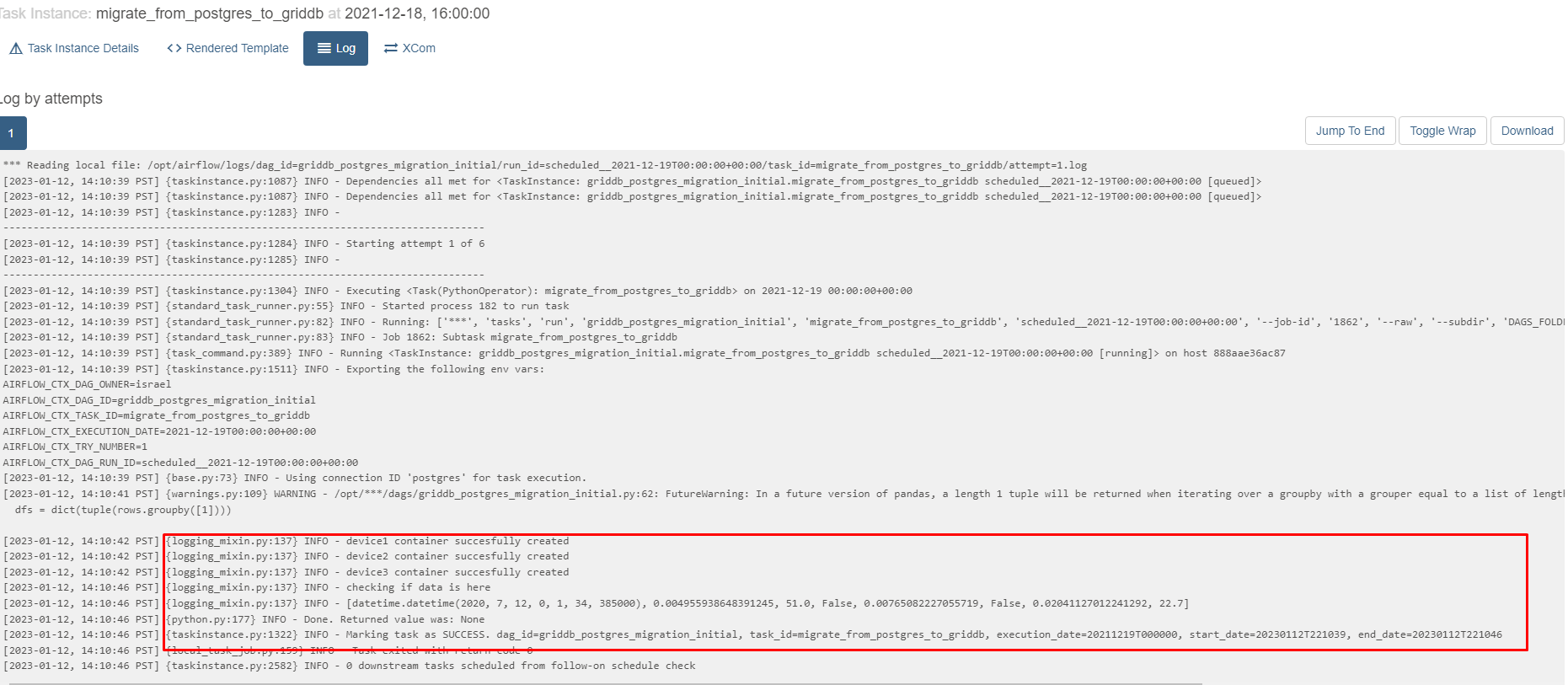
GridDBにクエリを実行する
これで、3つのコンテナが正常に作成されました。他に、GridDBコンテナにSSHで接続し、CLIシェルでクエリを実行することもできます。
以下のようにシェルに落とし込みます。
$ docker exec -it griddb-airflow gs_shThe connection attempt was successful(NoSQL).
The connection attempt was successful(NewSQL).
gs>
そこからコンテナ情報を確認することができます。
gs[public]> showcontainer device2
Database : public
Name : device2
Type : TIME_SERIES
Partition ID: 38
DataAffinity: -
Compression Method : NO
Compression Window : -
Row Expiration Time: -
Row Expiration Division Count: -
Columns:
No Name Type CSTR RowKey Compression
------------------------------------------------------------------------------
0 ts TIMESTAMP NN [RowKey]
1 co DOUBLE
2 humidity DOUBLE
3 light BOOL
4 lpg DOUBLE
5 motion BOOL
6 smoke DOUBLE
7 temperature DOUBLEそしてクエリーを実行します。
gs[public]> select * from device2;
111,817 results. (13 ms)
gs[public]> get 3
ts,co,humidity,light,lpg,motion,smoke,temperature
2020-07-12T00:01:34.735Z,0.00284008860710157,76.0,false,0.005114383400977071,false,0.013274836704851536,19.700000762939453
2020-07-12T00:01:46.869Z,0.002938115626660429,76.0,false,0.005241481841731117,false,0.013627521132019194,19.700000762939453
2020-07-12T00:02:02.785Z,0.0029050147565559607,75.80000305175781,false,0.0051986974792943095,false,0.013508733329556249,19.700000762939453
The 3 results had been acquired.継続的なマイグレーション
次に、1時間ごとのスケジュールで設定した次のDAGを開始します。
with DAG(
dag_id='griddb_postgres_migration_continuous',
default_args=default_args,
start_date=datetime(2022, 12, 19),
schedule_interval='0 * * * *'schedule_intervalのスタイルはcronですが、あまり慣れていない場合は、ショートカットも用意されています。例えば、’@hourly’と入力することも可能で、これも同様に有効です。
いずれの方法でも良いので手動でPostgreSQLデータベースにいくつかの行を追加して、継続的なマイグレーションが実際に行われているのを確認してみましょう。ひとまず今はこのままで、いくつかの行を追加します。
$ docker exec -it postgres-airflow bash
/# psql -U airflow
psql (13.9 (Debian 13.9-1.pgdg110+1))
Type "help" for help.そして今度は、いくつかの行を追加してみましょう。
postgres=# INSERT INTO device VALUES (now(), 'b8:27:eb:bf:9d:51', 0.003551, 50.0, false, 0.00754352, false, 0.0232432, 21.6);INSERT 0 1
テストとして何度でもできます。また、センサー名を変えて挿入することで、異なるコンテナへの挿入を試みることも可能です。
次に、DAGの電源を入れ、ログを確認してみましょう。
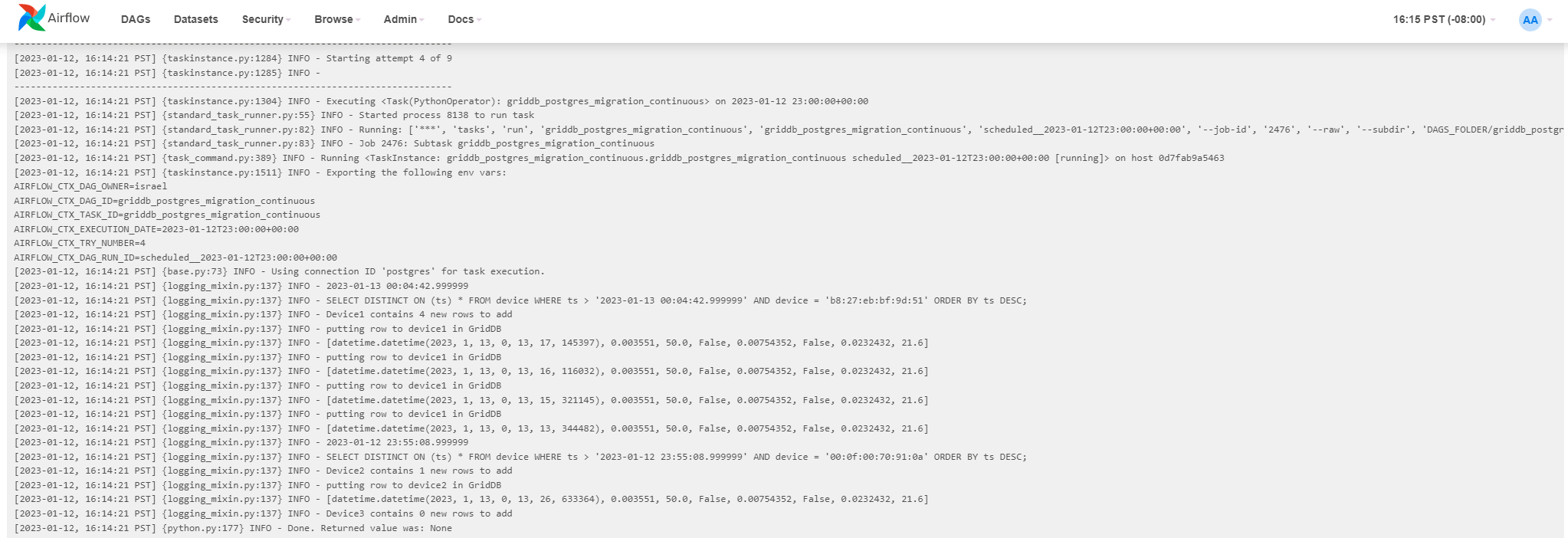
筆者のシェルでは、異なるコンテナの間に合計5つの新しい行を追加しました。その結果は以下の通りです。
[2023-01-12, 16:14:21 PST] {logging_mixin.py:137} INFO - SELECT DISTINCT ON (ts) * FROM device WHERE ts > '2023-01-13 00:04:42.999999' AND device = 'b8:27:eb:bf:9d:51' ORDER BY ts DESC;
[2023-01-12, 16:14:21 PST] {logging_mixin.py:137} INFO - Device1 contains 4 new rows to add
[2023-01-12, 16:14:21 PST] {logging_mixin.py:137} INFO - putting row to device1 in GridDB
[2023-01-12, 16:14:21 PST] {logging_mixin.py:137} INFO - [datetime.datetime(2023, 1, 13, 0, 13, 17, 145397), 0.003551, 50.0, False, 0.00754352, False, 0.0232432, 21.6]
[2023-01-12, 16:14:21 PST] {logging_mixin.py:137} INFO - putting row to device1 in GridDB
[2023-01-12, 16:14:21 PST] {logging_mixin.py:137} INFO - [datetime.datetime(2023, 1, 13, 0, 13, 16, 116032), 0.003551, 50.0, False, 0.00754352, False, 0.0232432, 21.6]
[2023-01-12, 16:14:21 PST] {logging_mixin.py:137} INFO - putting row to device1 in GridDB
[2023-01-12, 16:14:21 PST] {logging_mixin.py:137} INFO - [datetime.datetime(2023, 1, 13, 0, 13, 15, 321145), 0.003551, 50.0, False, 0.00754352, False, 0.0232432, 21.6]
[2023-01-12, 16:14:21 PST] {logging_mixin.py:137} INFO - putting row to device1 in GridDB
[2023-01-12, 16:14:21 PST] {logging_mixin.py:137} INFO - [datetime.datetime(2023, 1, 13, 0, 13, 13, 344482), 0.003551, 50.0, False, 0.00754352, False, 0.0232432, 21.6]
[2023-01-12, 16:14:21 PST] {logging_mixin.py:137} INFO - 2023-01-12 23:55:08.999999
[2023-01-12, 16:14:21 PST] {logging_mixin.py:137} INFO - SELECT DISTINCT ON (ts) * FROM device WHERE ts > '2023-01-12 23:55:08.999999' AND device = '00:0f:00:70:91:0a' ORDER BY ts DESC;
[2023-01-12, 16:14:21 PST] {logging_mixin.py:137} INFO - Device2 contains 1 new rows to add
[2023-01-12, 16:14:21 PST] {logging_mixin.py:137} INFO - putting row to device2 in GridDB
[2023-01-12, 16:14:21 PST] {logging_mixin.py:137} INFO - [datetime.datetime(2023, 1, 13, 0, 13, 26, 633364), 0.003551, 50.0, False, 0.00754352, False, 0.0232432, 21.6]
[2023-01-12, 16:14:21 PST] {logging_mixin.py:137} INFO - Device3 contains 0 new rows to add
[2023-01-12, 16:14:21 PST] {python.py:177} INFO - Done. Returned value was: None
[2023-01-12, 16:14:21 PST] {taskinstance.py:1322} INFO - Marking task as SUCCESS. dag_id=griddb_postgres_migration_continuous, task_id=griddb_postgres_migration_continuous, execution_date=20230112T230000, start_date=20230113T001421, end_date=20230113T001421
GridDBシェルに戻り、行が挿入されていることを確認します。
gs[public]> tql device1 select MAX(ts);
1 results. (15 ms)
gs[public]> get
Result
2023-01-13T00:13:17.145Z
The 1 results had been acquired.合っていることが確認できました。
まとめ
これで、Dockerを使ってApache Airflowをセットアップし、PostgreSQLからGridDBへ継続的にデータを移行することができるようになりました。ぜひ使ってみてください。
ブログの内容について疑問や質問がある場合は Q&A サイトである Stack Overflow に質問を投稿しましょう。 GridDB 開発者やエンジニアから速やかな回答が得られるようにするためにも "griddb" タグをつけることをお忘れなく。 https://stackoverflow.com/questions/ask?tags=griddb