
1.時系列データとは?
時系列データとは、時間情報(タイムスタンプ) を持った一連の値のことです。一般的には、タイムスタンプは一定間隔で連続的な値をとります。時系列データの具体例としては、 分刻みで記録された気温データや、取引日毎の終値を記載した株価データなどがあげられます。
IoT(Internet of Things) アプリケーションでは、温度センサー、電圧センサー、照度センサー、イメージセンサーなど、対象をとりまく様々なセンサーから、分刻み、秒刻み、あるいはそれ以下の周期で取得された、大量の時系列データを取り扱います。
このようなデータを保持するシステムとして、必ずしもデータベースは必要ありませんが、通常以下のような機能が求められます。
- 絶えず流れ込んでくる大量のデータを取りこぼさず記録する
- 頻繁に起こるデータ欠損や参照データの矛盾などに対処できる
- 時間をキーとした読み出し方法を提供する
- センサーをキーとした読み出し方法を提供する
これらの機能が提供されれば、横軸を時間としてリアルタイムにセンサーデータを描き出し、監視用途に使用したり、あるいは、オフラインで一定時間内の各種センサー値の相関を調べたり、時系列データに対して行われる、各種表示・分析が容易になります。

ソース: The Rossi X-ray Timing Explorer Learning Center, NASA
2. 時系列データの保持
上記のような時系列データを保持するための手法としては、大きく分けて
- 単純にファイルとして保存する(フラットファイル)
- Relational Database(RDB) を使う
- NoSQL Database を使う
という3つの手法が考えられます。
単純にファイルとしてデータを保存する場合の最大のメリットは書き込みスピードです。どんなデータベースを使うにしても、直接のファイル書き込みに比べれば、なんらかのオーバーヘッドが載っているため、書き込みスピードは若干遅くなります。そのため、時間あたりのデータの流量が非常に大きく、データベースを使う余裕がなければ、ファイルで保存するしかありません。その他のメリットとして、取り扱うデータに制限はなく、画像データでも、数値データでもファイルに落とせるものならなんでも取り扱える柔軟性があります。その反面、デメリットとしては、それらの多様なデータの管理方式を自分で決めなければいけないこと、そして保存後のデータの整理が煩雑となり、さらには検索性が非常に悪くなってしまうことがあげられます。
通常のRDBでデータを保存する場合の最大のメリットは、トランザクションでACID特性(Atomicity, Consistency, Isolation, Durability) が保証されていることです。また、 取得したデータの加工や、複雑な条件でのデータ抽出・集計なども、標準的なSQL 文を使って簡単にできます。RDBのデメリットは、処理の厳密さ故に、単位時間あたりの処理数をあまりあげることができないことがあげられます。また、取り扱うデータは構造化されたデータを前提としていて、スキーマ(データベースの構造) を事前に決めておく必要があり、柔軟性が低いこともデメリットの一つといえます。 つまり、多様なセンサーからの大量なデータを保持するには、不適切な場合が多いのです。
そこでNoSQL データベースの登場になります。NoSQL は、”Not only SQL” の略で、その名の通り、SQL をベースとするRDB の課題を克服するためのデータベースです。最もシンプルなNoSQL データベースは、キー・バリューストア型と呼ばれるもので、単に「値」と、「値」を取得するための「キー」だけを格納するものです。単純なファイル書き込みほどではありませんが、高速な書き込み・読み出しを特徴としています。また、RDBとは異なり、数値データだけでなく、音声や画像などいわゆる「非構造化データ」を取り扱うこともできます。もちろん、良い面ばかりでなく、性能や柔軟性が向上された一方で、RDB が持っていた一部の機能を失っています。まず、SQL がサポートされていないか、あるいは機能に制限があります。また、RDBのようなACID特性をもった厳密なトランザクションに関しても、通常サポートされていません(一部のデータベースでは、なんらかの制限付きでのサポートされているものもあります)。
以上のように、3つのデータ保存方法において、厳密なデータ管理と高速動作はトレードオフの関係といえますが、IoTアプリケーションからの時系列データの取得には、高速な書き込み・読み出し性能を持ち、機能はそれほど多くないとしても、ある程度のデータ検索・読み出し手法が提供されている、NoSQL データベースが最適といえるでしょう。
3. なぜGridDBか?
GridDB もNoSQL データベースの一種ですが、他のNoSQL データベースにはない、IoT アプリケーション・時系列データ向けに特化したユニークな特徴を持っています。以下ではその特徴について詳しく説明します。
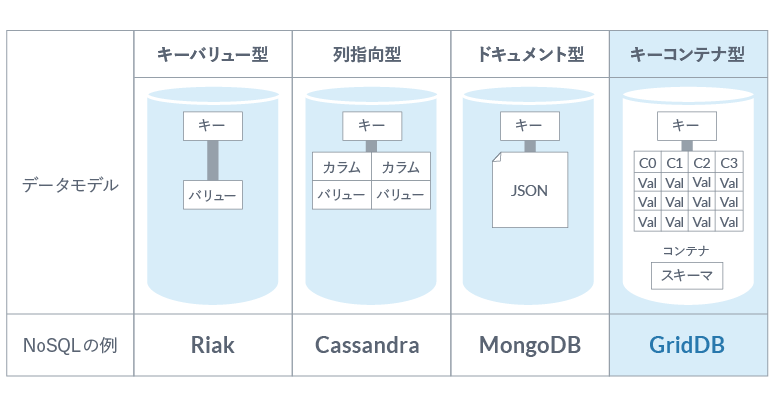
キーコンテナ型によるセンサ毎の一貫性の保持
NoSQL データベースは、キーバリュー型(代表例: Riak)、列指向型(代表例: Cassandra)、ドキュメント指向型(代表例: MongoDB)、などのデータモデルがあります。しかし、複数の機器の持つ多数のセンサーデータからの時系列データの取得、というユースケースを考えると、既存のデータモデルには不満が残ります。例えば、キーバリュー型では、単純すぎて、機器単位やセンサ単位など、ある管理グループで一貫性をもったデータを管理することは困難です。 GridDB では、新たなデータモデルとしてキーコンテナ型を採用しています。あるキーにより参照されるコンテナは、テーブル(表)表現でデータを管理します。コンテナではスキーマ定義が可能で、カラム(列)にインデックスを設定することもできます。つまり、コンテナ自体は一般的なRDBのように取り扱うことができ、ACID特性が保証されたトランザクション処理を行うことができます。 また、SQLライクなクエリ(TQL)を利用することもできます。
タイムスタンプをキーとした各種操作の提供
GridDBでは、時系列データを操作する上で便利な機能が標準で備わっています。例えば、前述のデータの保持単位「コンテナ」において、時系列データ専用の「時系列コンテナ」があります。これを使うことで、時間間隔を区切ったデータ抽出(サンプリング機能)や、一定の期間を過ぎたデータを自動的に削除 (期限開放機能)、などが利用できます。
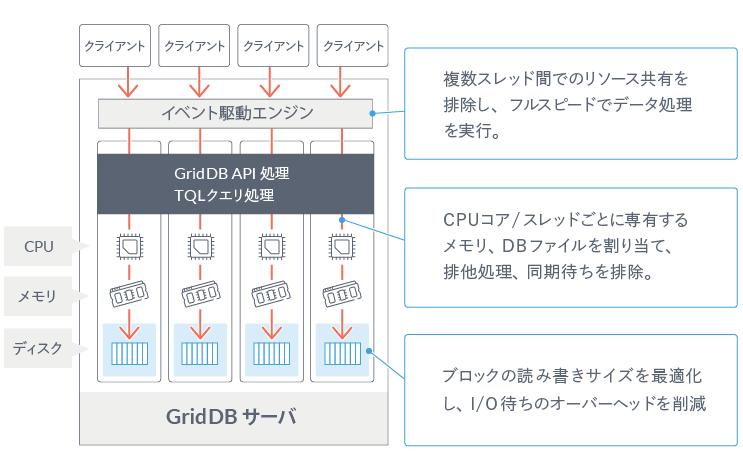
メモリ指向アーキテクチャーによる超高速動作
処理スピードはRDBに対するNoSQLデータベースの最大のアドバンテージですが、GridDB は、そのNoSQL の中でもトップクラスの処理能力を誇ります。高速動作の秘密は「できるだけメモリ上で処理をする」という設計思想です。全てのデータがメモリ上に配置されれば話は簡単ですが、 メモリ上に保持できないほどの大量のデータを処理するためには、アプリケーションのアクセスするデータを局所化し、ディスクに配置されたデータへのアクセスをできるだけ少なくする必要があります。GridDBではデータアクセスを局所化するために、関連のあるデータをできるだけ同じブロックに配置する機能を提供します。データにヒント情報を与えることで、ヒントに従ったデータブロックへのデータ集約が実現できるため、データアクセス時のメモリミスヒットを減らし、データアクセス処理を高速化します。
いかかでしょうか?センサーデータを想定したキー・コンテナ型データモデル。タイムスタンプをキーとした様々な便利機能。大量のデータ書き込みを問題なくこなせる処理能力。以上の機能は全て、「大量の時系列データを効率よく処理する」ために設計され、実装されたものなのです。
あなたのIoT アプリケーションが現在使っている、ファイル単位の保存、RDB、あるいは既存のNoSQL の代わりに、是非GridDB を使ってみてください。Community Edition なら、Apache License でいつでも無料で利用可能です。
If you have any questions about the blog, please create a Stack Overflow post here https://stackoverflow.com/questions/ask?tags=griddb .
Make sure that you use the “griddb” tag so our engineers can quickly reply to your questions.