
Originally published 2017 · Updated 2026
As IoT and sensor systems scale, time series data has become one of the most demanding workloads in modern data engineering — high write volume, relentless ingestion, and queries that span both the most recent reading and years of history. This post covers what time series data is, the practical ways to store it, and why GridDB is purpose-built for it.
1. What Is Time Series Data?
Time series data is a sequence of values, each tagged with a timestamp, generally recorded at regular intervals. Familiar examples include a temperature reading captured every few minutes, or the closing price of a stock at the end of each trading day.
In an Internet of Things (IoT) application, large volumes of time series data flow in from many kinds of sensors — temperature, voltage, illuminance, image sensors — recording at intervals of a minute, a second, or even sub-second. A database isn’t strictly required to store it, but in practice you need a system that can:
- Store large amounts of continuously streaming data
- Tolerate frequent data loss and reference inconsistencies gracefully
- Retrieve data by timestamp or by time range
- Query data using a sensor ID as a key
With those capabilities in place, sensor data can be plotted in real time — time on the horizontal axis — for monitoring, and you can examine correlations between sensor values over a given period using a range of analysis methods and visualizations.
2. How Do You Store Time Series Data?
Given the requirements above, there are three practical approaches, each with trade-offs.
Flat files. The main benefit of writing data straight to a file is raw write performance — any database adds overhead that reduces throughput compared to direct file writes. If your data rate is so high that a database can’t keep up, files can. Files also impose no restrictions on data shape: image data, numeric data, anything that can be written can be stored. The downsides are significant, though: you must manage records by hand, organizing the data is cumbersome, and building efficient complex queries is difficult.
Relational databases (RDB). The major advantage of an RDB is guaranteed ACID transactions (Atomicity, Consistency, Isolation, Durability), plus the ability to run complex queries easily in standard SQL. The classic disadvantage for this workload is that traditional RDBs are hard to scale out, and their rigid, predefined schema is difficult to change as requirements evolve — which makes holding large volumes of diverse sensor data over the long term awkward.
NoSQL databases. NoSQL (“Not only SQL”) emerged to overcome the limitations of SQL-based RDBs. The simplest form, a key-value store, holds one value per key with very fast reads and writes, and can handle unstructured data where different keys carry different types. The trade-off is that some RDB functionality is lost: SQL support may be limited or absent, and many NoSQL systems relax strict ACID guarantees to scale more easily — though some are ACID-compliant within certain bounds.
Across these three, strict data management and high-speed operation tend to be a trade-off. For ingesting time series data from IoT applications, where fast write/read performance matters more than a broad feature set, a NoSQL database that also provides solid data-retrieval capabilities is typically the best fit. GridDB is built to occupy exactly that sweet spot — without forcing you to give up ACID transactions or SQL.
3. Why GridDB?
GridDB is a NoSQL database, but it has features tailored to IoT and time series workloads that set it apart from other NoSQL systems.
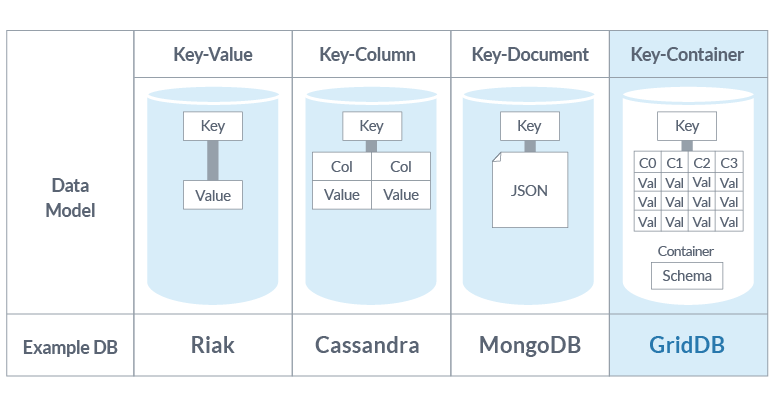
Key-Container Data Model
Different NoSQL databases use different data models: key-value (Riak), column-oriented (Cassandra), document-oriented (MongoDB). For the use case of collecting time series data from many sensor devices, each of these has shortcomings — a plain key-value model, for instance, is too simple to manage consistent data within a logical group like a device or sensor.
GridDB uses a Key-Container model. Containers, referenced by key, manage data in a table-like structure with a defined schema and indexable columns. In effect, a container behaves much like an RDB table: you get ACID-compliant transaction processing, and you can query it with TQL, GridDB’s time-series-aware query language.
Time Values as a Key
GridDB provides a dedicated TimeSeries container for time series data. With it, you can query by timestamp, slice by time interval, automatically expire data past a defined age (TTL), and use other time-specific operations through the API.
In-Memory-First Architecture
Speed is a defining advantage of NoSQL, and GridDB is among the fastest. The secret is a “memory first, storage second” design philosophy: process as many operations in memory as possible. A pure in-memory store is simple, but to handle datasets larger than RAM, GridDB also reaches efficiently to disk — localizing the data an application touches to minimize disk access. By placing related data together in the same block (guided by hints you provide), GridDB reduces memory-access misses and improves performance further.

Both NoSQL and SQL — on the Same Data
One thing that has changed substantially since this post first appeared: GridDB is no longer TQL-only. It offers two interfaces over the same data. The NoSQL interface (queried with TQL) is optimized for high-frequency collection and retrieval. The NewSQL interface exposes your data as relational tables accessible with standard SQL over JDBC, which is ideal for analytics, BI tools, and integrating with existing relational applications. A container created through the NoSQL interface can be queried as a table through SQL, and vice versa — both interfaces are available in the open source Community Edition.
GridDB’s Key-Container model, high performance, and specialized time functions are all designed to do one thing well: efficiently process large amounts of time series data.
4. GridDB Today: Editions, Cloud, and Ecosystem
GridDB comes in three editions. Community Edition (CE) is the free, open source edition — the server is licensed under AGPL v3 and the client libraries under Apache 2.0 — and runs as a single node. Enterprise Edition adds multi-node clustering, high availability, security features, and commercial support. GridDB Cloud is the fully-managed service, available on the Azure Marketplace, for teams that would rather not operate the database themselves.
GridDB also fits into a modern data stack: official client libraries for Java, Python, C, Go, Node.js, and PHP, a RESTful Web API, an Apache Kafka connector for streaming pipelines, and a Grafana plugin for dashboards.
If you’re evaluating GridDB against other time series databases, see our honest comparisons of GridDB vs. TimescaleDB and GridDB vs. InfluxDB, and our cloud benchmark of GridDB Cloud vs. InfluxDB Cloud vs. MongoDB Atlas.
Give it a try and see how it handles your workload. GridDB Community Edition is free and open source — download it from GitHub or get started with the docs. Prefer a managed option? GridDB Cloud gets you running without provisioning infrastructure.