こちらの冗談のようなサイトを見てみてください。http://www.iscaliforniaonfire.com/ このページを見ると、カリフォルニア州が常に直面している脅威、つまり、州全体で発生する山火事が数え切れないほどの破壊をもたらすということが、よくわかります。このブログでは、カリフォルニア州で山火事が発生したときに一酸化炭素(CO)や二酸化窒素(NO2)の排出量が増加するかどうか、またその量はどのくらいなのかをGridDBとTableauを使って調べてみましょう。
このプロジェクトの完全なソースコードは、このページの下部の ソースコード にあります。
データセット
まず、EPAの大気環境システムAPIから取得したデータセットを見てみましょう。できれば、2020年8月から9月までの間にカリフォルニア州で記録的な火災が発生した時のデータを使いたかったのですが、残念ながら、そのデータはまだ共有されていないので、2019年のデータセットを使うことにします。また、このブログの途中で、単に一酸化炭素のデータを見るだけでは十分ではないことに気付き、後から2019年のNO2(二酸化窒素)のデータも取得することにしました。
メールアドレスを登録してAPIキーを受け取ったら、このサービスを使って以下のようなクエリを作成しました。
https://aqs.epa.gov/data/api/sampleData/byCounty?email=yourEmailAddress&key=yourAPIKey¶m=42101&bdate=20190101&edate=202190131&state=06&county=037
上記のリクエストは、特定の場所、特定の範囲の時間、特定のデータパラメータ(CO)に対するクエリを送信しています。これらのAPIコールで返されるデータはかなりの量になるため、一度にリクエストできる時間範囲は約6週間分のデータ(〜25MBのJSONファイル)に制限されています。それ以上の期間のデータが必要な場合は、関連するデータを何度かに分けてGridDBに取り込む必要があります。
GridDBへのデータの挿入
すでにGridDBがインストールされていることを前提としています。インストールされていない場合は、クイックスタートガイドを参照してインストールしてください。https://docs.griddb.net/gettingstarted/introduction/ このブログでは、簡単にできるようPythonを使用しています。このAPIが返すJSONは以下のようになっています。
{
"state_code": "06",
"county_code": "037",
"site_number": "1602",
"parameter_code": "42101",
"poc": 1,
"latitude": 34.01029,
"longitude": -118.0685,
"datum": "NAD83",
"parameter": "Carbon monoxide",
"date_local": "2020-06-21",
"time_local": "00:00",
"date_gmt": "2020-06-21",
"time_gmt": "08:00",
"sample_measurement": 0.2,
"units_of_measure": "Parts per million",
"units_of_measure_code": "007",
"sample_duration": "1 HOUR",
"sample_duration_code": "1",
"sample_frequency": "HOURLY",
"detection_limit": 0.5,
"uncertainty": null,
"qualifier": null,
"method_type": "FRM",
"method": "INSTRUMENTAL - NONDISPERSIVE INFRARED PHOTOMETRY",
"method_code": "158",
"state": "California",
"county": "Los Angeles",
"date_of_last_change": "2020-09-22",
"cbsa_code": "31080"
}このデータのほとんどは、私たちの今回の調査のためには不要なものなので、私は単純にサンプルの測定と時間を取る時系列コンテナを作りました。
conInfo = griddb.ContainerInfo("LosAngelesCO",
[["timestamp", griddb.Type.TIMESTAMP],
["CO", griddb.Type.DOUBLE]],
griddb.ContainerType.TIME_SERIES, True)conInfo = griddb.ContainerInfo("LosAngelesNO2",
[["timestamp", griddb.Type.TIMESTAMP],
["NOtwo", griddb.Type.DOUBLE]],
griddb.ContainerType.TIME_SERIES, True)Pythonを使うことで、非常に簡単にこれらの特定のデータポイントをデータベースに挿入することができます。まず、JSONライブラリを使ってHTTPリクエストを実行し、関連情報を取得します。
def getJSON(bdate, edate):
url = "https://aqs.epa.gov/data/api/sampleData/byCounty?email=EMAILADDRESS&key=APIKEY¶m=42602&bdate="+bdate+"&edate="+edate+"&state=06&county=037"
payload={}
headers = {}
response = requests.request("GET", url, headers=headers, data=payload)
return (response.text)
次に、実際にデータをデータベースに挿入していきます。私はマニュアルで一つずつ開始日と終了日を変更して、2019年以降のすべての関連するデータを挿入するために、月ごとに変更しました。私は、重複させることなく各月の範囲にforループを設定していきましたが、これは単純で退屈な作業に感じる方もいるかもしれません。
def writeContainer():
factory = griddb.StoreFactory.get_instance()
gridstore = factory.get_store(host='239.0.0.1', port=31999, cluster_name='defaultCluster', username='admin', password='admin')
#Create Collection
conInfo = griddb.ContainerInfo("LosAngelesNO2",
[["timestamp", griddb.Type.TIMESTAMP],
["notwo", griddb.Type.DOUBLE]],
griddb.ContainerType.TIME_SERIES, True)
rows = []
data = getJSON('20191201', '20191231')
data = json.loads(data)
for p in data['Data']:
date_time_str = p['date_local'] + ' '+ p['time_local']
date_time_obj = datetime.datetime.strptime(date_time_str, '%Y-%m-%d %H:%M')
row = [None, None]
row[0] = date_time_obj.timestamp()
row[1] = p['sample_measurement']
rows.append(row)
con = gridstore.put_container(conInfo);
con.set_auto_commit(False)
con.multi_put(rows)
length = str(len(rows))
con.commit()
print("Wrote "+ length + " records")
これでロサンゼルス郡のCO(一酸化炭素)とNO2(二酸化窒素)の1時間ごとのデータが得られました。次にいよいよ、Tableauを使って可視化していきましょう。
Tableau
インストールと基本的な使い方
GridDB コネクタと一緒にTableauをインストールするには、こちらのブログGridDB JDBC Tableau コネクタ プラグイン入門を参考にしてください。このブログでは、貴重なデータをTableauに読み込ませるための基本的な使い方を学ぶことができます。
データの可視化
月ごとのCO(一酸化炭素)の排出量
このブログの最初にTableauを使って調べたデータセットは、ロサンゼルスの一酸化炭素の排出量を月ごとにで表したものでした。山火事が多いのは例年8月以降なので、この時期に一酸化炭素の排出量の大きな上昇が見られると予想していました。そこで、この2つの指標(Avg COとTime)をビューページの上部に入力しました。
そして、出来上がったチャートはこのようになりました。
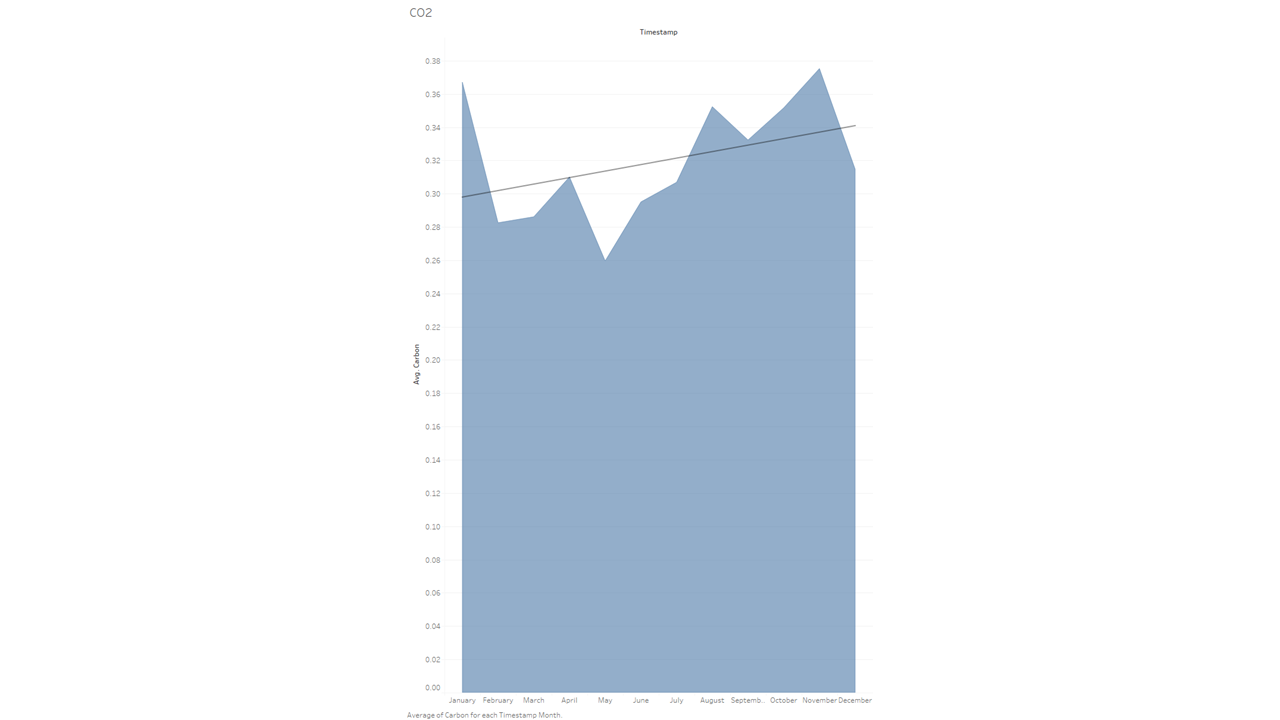
データを見ると、確かにこの時期にCO(一酸化炭素)排出量が平均よりも増加していることがわかりますが、それが予想していたほど高くないことに少し驚きました。ここでは、線形のトレンドライン(水平方向に交差する大きな線)と呼ばれるものを示しています。これは、経年でのデータの一般的な方向性を示すのに役立ちます。
月ごとのNO2(二酸化窒素)の排出量
このブログのためにデータを集めているうちに、山火事は確かにCO(一酸化炭素)を排出するものの、本当に影響が大きいのはNO2(二酸化窒素)であることを知りました。そこで、NO2(二酸化窒素)のグラフも作ってみることにしました。
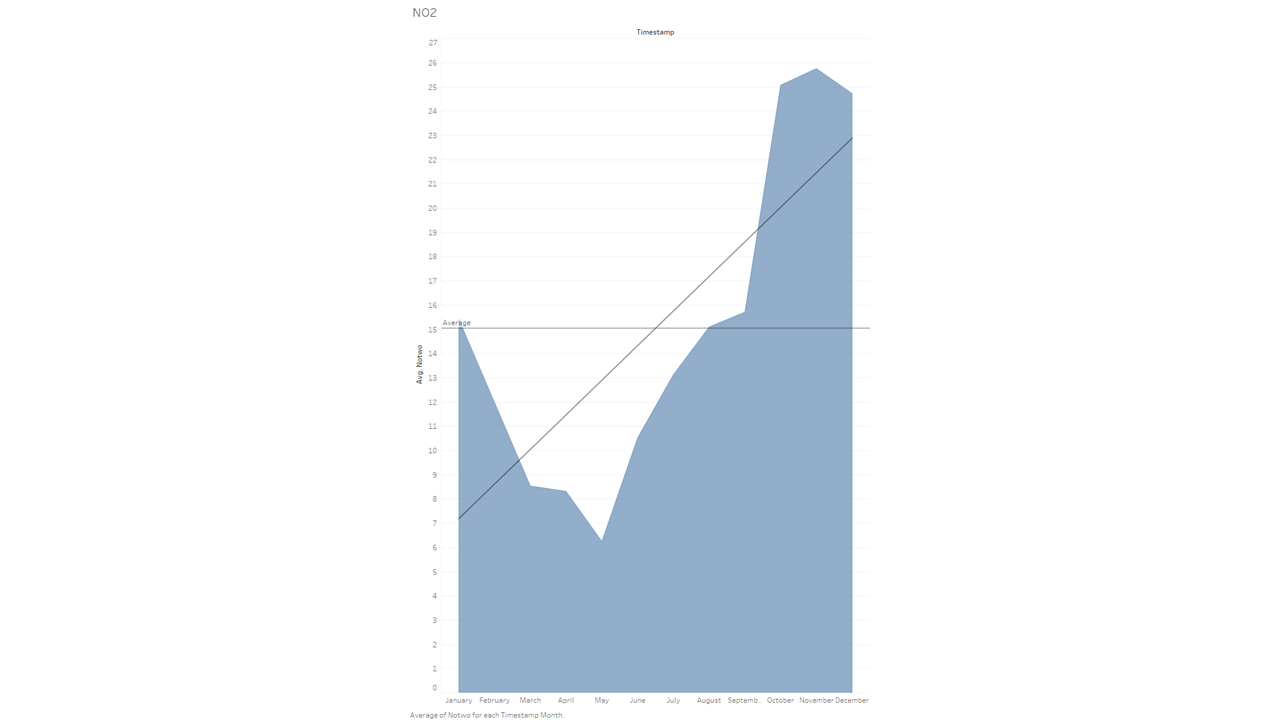
春と火事の多い季節の間に大きな差があることは予想していましたが、実際にそのデータを目の当たりにすると、やはり驚異的な差があり怖いほどです。
一つ補足しておくと、このチャートには、チャート全体に「平均」の線が入っています。後半の月が基準値をどれだけ上回っているかを示すのに役立つでしょう。トレンドラインと似たような場所にその設定機能があります。
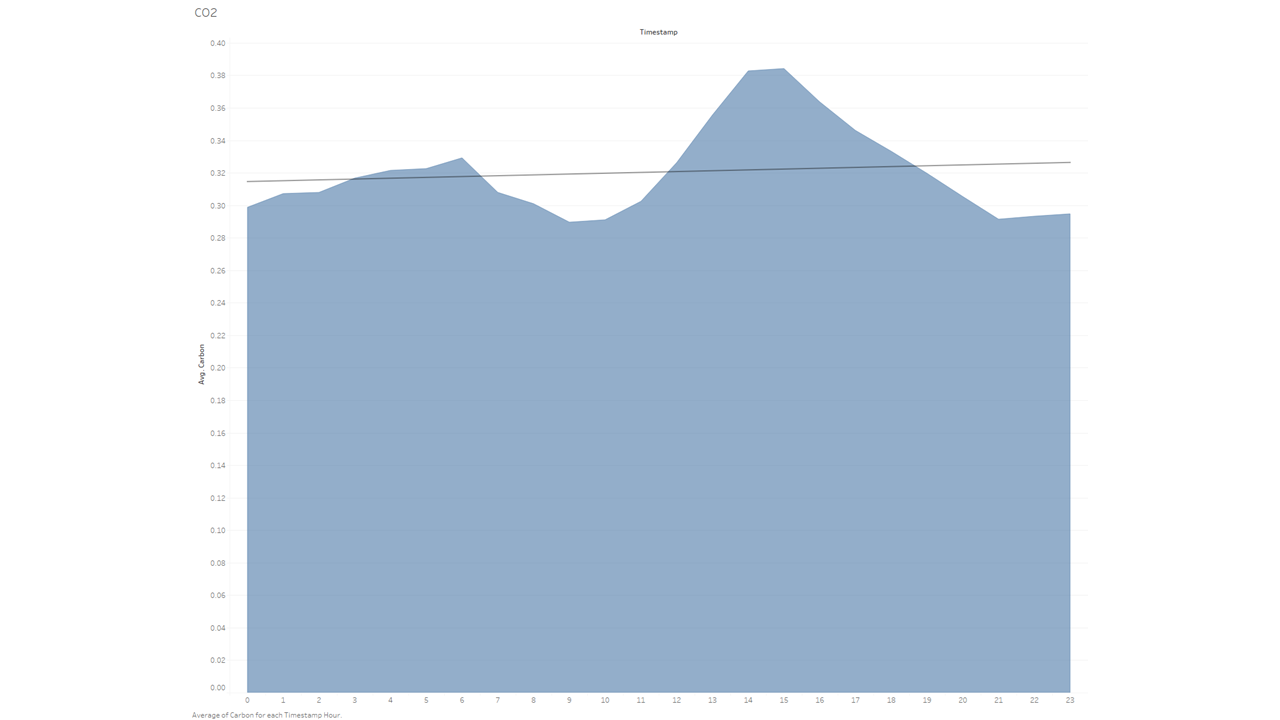
その他のCO(一酸化炭素)データ
ここからは、CO(一酸化炭素)の排出量が多い自動車のデータを用いて、1時間ごとの平均CO(一酸化炭素)とNO2(二酸化窒素)のデータを月別に抽出したものを見てみましょう。
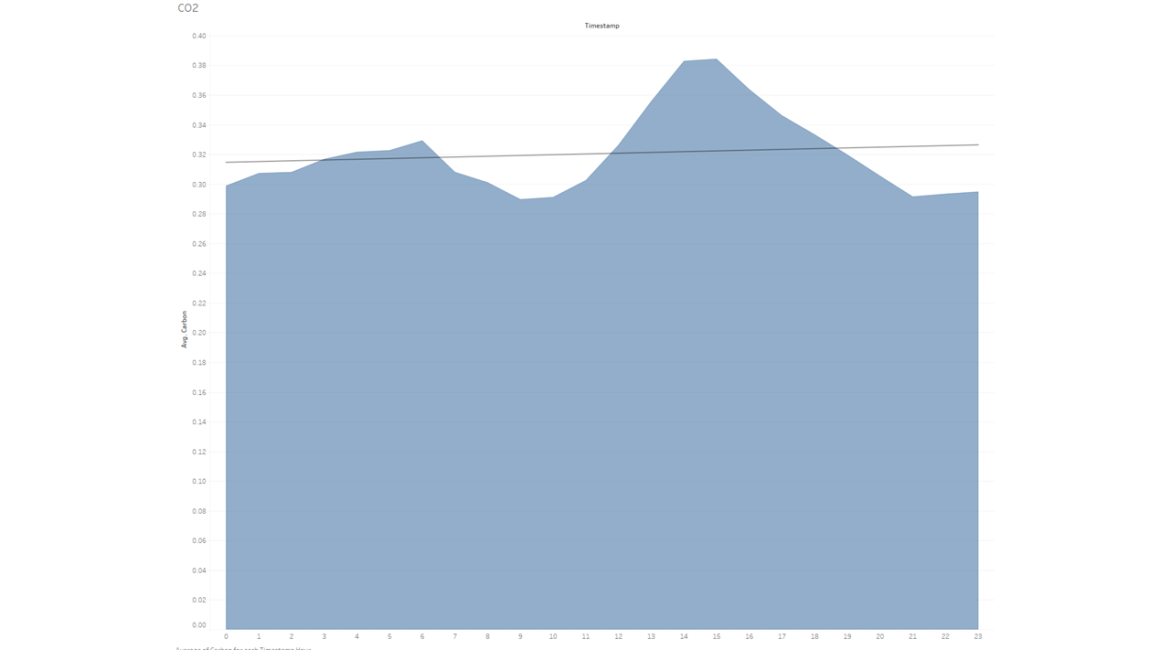
これは同じデータセットを別の方法で可視化したものです。
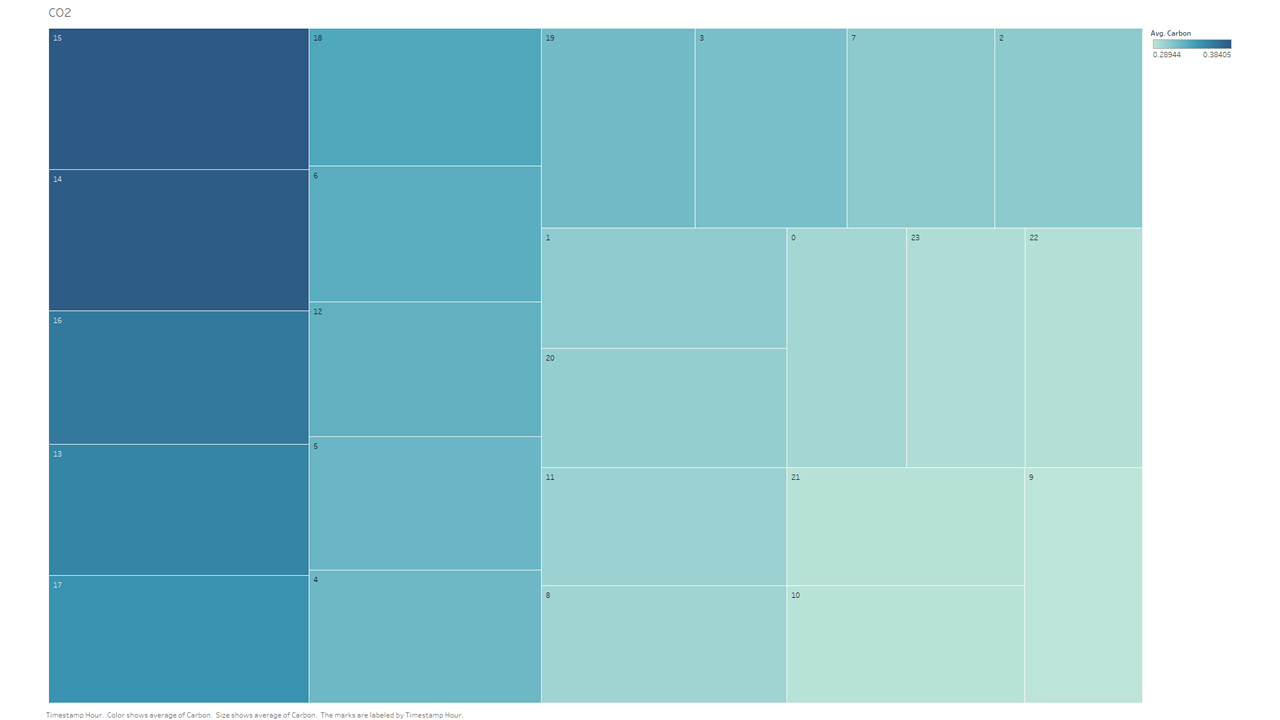
このデータセットを見ると、2019年の1年間の全てのデータポイントを取ると、平均して、14時間目(午後2時)と15時間目(午後3時)が、一酸化炭素の排出量が最も多い(=最も悪い)ということが分かります。これは私の予想とほぼ一致していますが、予想していたよりも少し前にずれています。しかし、これはデータセットに週末が含まれていることを理解することで説明できるかもしれませんし、このデータは交通渋滞が帰宅ラッシュの夕方に起こりやすいという一般的なイメージを少し変えてしまうかもしれません。
GridDBコネクタがJOINを追加できるようになったら、2020年4月~7月と2019年の一酸化炭素排出量を比較してみると、とても興味深い結果が得られると思います。
結論
以上のように、EPAを使って収集、分析されたCO(一酸化炭素)とNO2(二酸化窒素)のデータについて見ていきました。他にも分析したデータをご覧になりたい方は、お気軽にお問い合わせください。
ソースコード
If you have any questions about the blog, please create a Stack Overflow post here https://stackoverflow.com/questions/ask?tags=griddb .
Make sure that you use the “griddb” tag so our engineers can quickly reply to your questions.