スキーマの概要
このサンプル・アプリケーションにはそれぞれ独自の機能を持つ2つのコンポーネントがあります。 データ生成クライアントは、3つのコーヒーストアを含む1つのコーヒーチェーンを作成します。 それぞれの店は5台のコーヒーマシンを持っています。 次に、洗浄率や故障率、ショット率や標準偏差などの機械設定を生成します。 クライアントは、生成されたマシン設定に基づいて、3日分のデータをGridDBにプリロードします。 次に、ショットレートを使用して各レコード間の時間間隔を決定し、それらをGridDBに挿入して、徐々にレコードを生成し始めます。
データ視覚化コンポーネントは、Webフロントエンド上にプロットを作成し更新する、無限に動作するWebサーバーとして機能します。 これは、定期的なコールバックを使用して最近のレコードを取得し、ユーザーのイベントに応答します。 さらに、TQLクエリを使用して、過去または最近のデータを取得し、それに応じてウェブページ上の時系列プロットを更新します。
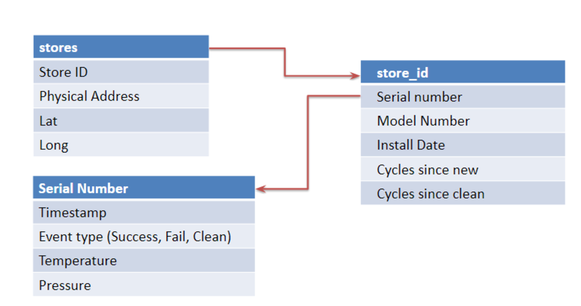
データの流れは、コーヒーチェーンコンテナから始まります。このコレクションは、フランチャイズ内のすべてのコーヒーストアを保持するコンテナと考えることができます。各店舗は店舗IDで識別されます。コーヒーストアには、住所やその地理的な容器などの他の情報も含まれています。
すべてのコーヒーストアは、複数のコーヒーマシンを持つことができます。コーヒーマシンのユニークな店舗IDは、コーヒーマシンに関する情報を保持するコンテナの名前にもなります。各コーヒーマシンには固有のシリアル番号があります。また、モデル番号とインストール日付もあります。また、最後のクリーンサイクル以降、かつインストールされて以降、いくつのサイクルがあったかのカウントがあります。
すべてのコーヒーマシンは、GridDB Cクライアントが組み込まれたマシンと考えることができます。ショットを発行するかサイクルを通過するたびに、タイムスタンプレコードがGridDBに送信されます。コーヒーマシンは、サイクルの状態(成功ショット、失敗ショット、クリーンサイクル)およびショットの温度および圧力を記録するコーヒーマシンコンテナとして考えることができます。
ソースコード
以下のリンクから、データ生成クライアントおよびデータ視覚化コンポーネントのアプリケーションおよびそのソースコードをダウンロードできます。
Download: datavisualisation_application.tar.gz