The understanding of climate change impacts and the associated climate extreme events at regional and local scales is of critical importance for planning and development of feasible adaptation strategies.
Climate change is without a doubt the most serious threat to humanity in the modern era. To have any hope of mitigating the harmful effects of climate change, the global mean temperature should be limited to 1.5 degrees Celsius above pre-industrial levels, according to the IPCC.
In this article, I am going to analyse how to create map charts and animations of temperature variability, by using Python and the power of GridDB.
A link to the full source code and jupyter file: https://github.com/griddbnet/Blogs/tree/analyzing-global-climate-change
The outline of the tutorial is as follows:
- Dataset overview
- Importing required libraries
- Loading the dataset
- Data Cleaning and Preprocessing
- Analysing with data visualization
- Conclusion
Prerequisites and Environment setup
This tutorial is carried out in Anaconda Navigator (Python version – 3.8.5) on Windows Operating System. The following packages need to be installed before you continue with the tutorial –
-
Pandas
-
NumPy
-
plotly
-
Matplotlib
-
Seaborn
-
griddb_python
You can install these packages in Conda’s virtual environment using conda install package-name. In case you are using Python directly via terminal/command prompt, pip install package-name will do the work.
GridDB installation
While loading the dataset, this tutorial will cover two methods – Using GridDB as well as Using Pandas. To access GridDB using Python, the following packages also need to be installed beforehand:
- GridDB C-client
- SWIG (Simplified Wrapper and Interface Generator)
- GridDB Python Client
Dataset Overview
The dataset contains information about visits to GStore (Google swag online store), each row is a unique visit and each user has a unique ‘fullVisitorId’.
Global Land and Ocean-and-Land Temperatures (GlobalTemperatures.csv):
Date: starts in 1750 for average land temperature and 1850 for max and min land temperatures and global ocean and land temperatures LandAverageTemperature: global average land temperature in celsius
https://www.kaggle.com/datasets/berkeleyearth/climate-change-earth-surface-temperature-data
Importing Required Libraries
# import griddb_python as griddb
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import plotly
import plotly.graph_objs as go
import plotly.tools as tls
import plotly.express as px
import plotly.graph_objs as go
import seaborn as sns
import time
import warnings
warnings.filterwarnings('ignore')
%matplotlib inlineLoading the Dataset
Let’s proceed and load the dataset into our notebook.
Using GridDB
Toshiba GridDB™ is a highly scalable NoSQL database best suited for IoT and Big Data. The foundation of GridDB’s principles is based upon offering a versatile data store that is optimized for IoT, provides high scalability, tuned for high performance, and ensures high reliability.
To store large amounts of data, a CSV file can be cumbersome. GridDB serves as a perfect alternative as it in open-source and a highly scalable database. GridDB is a scalable, in-memory, No SQL database which makes it easier for you to store large amounts of data. If you are new to GridDB, a tutorial on reading and writing to GridDB can be useful.
Assuming that you have already set up your database, we will now write the SQL query in python to load our dataset.
factory = griddb.StoreFactory.get_instance()
Initialize the GridDB container (enter your database credentials)
try:
gridstore = factory.get_store(host=host_name, port=your_port,
cluster_name=cluster_name, username=admin,
password=admin)
info = griddb.ContainerInfo("GlobalTemperatures",
[["dt", griddb.Type.TIMESTAMP],["LandAverageTemperature", griddb.Type.DOUBLE],
["LandAverageTemperatureUncertainty", griddb.Type.DOUBLE],
["LandMaxTemperature", griddb.Type.DOUBLE],
["LandMaxTemperatureUncertainty", griddb.Type.DOUBLE],
["LandMinTemperature", griddb.Type.DOUBLE],
["LandMinTemperatureUncertainty", griddb.Type.DOUBLE],
["LandAndOceanAverageTemperature", griddb.Type.DOUBLE],
["LandAndOceanAverageTemperatureUncertainty", griddb.Type.DOUBLE],
, True)
cont = gridstore.put_container(info)
data = pd.read_csv("GlobalTemperatures.csv")
#Add data
for i in range(len(data)):
ret = cont.put(data.iloc[i, :])
print("Data added successfully")
try:
gridstore = factory.get_store(host=host_name, port=your_port,
cluster_name=cluster_name, username=admin,
password=admin)
info = griddb.ContainerInfo("GlobalLandTemperaturesByCity",
[["dt", griddb.Type.TIMESTAMP],["AverageTemperature", griddb.Type.DOUBLE],
["AverageTemperatureUncertainty", griddb.Type.DOUBLE],
["City", griddb.Type.STRING],["Country", griddb.Type.STRING],
["Latitude", griddb.Type.STRING], ["Longitude", griddb.Type.STRING],True)
cont = gridstore.put_container(info)
data = pd.read_csv("GlobalLandTemperaturesByCity.csv")
#Add data
for i in range(len(data)):
ret = cont.put(data.iloc[i, :])
print("Data added successfully")
try:
gridstore = factory.get_store(host=host_name, port=your_port,
cluster_name=cluster_name, username=admin,
password=admin)
info = griddb.ContainerInfo("GlobalLandTemperaturesByState",
[["dt", griddb.Type.TIMESTAMP],["AverageTemperature", griddb.Type.DOUBLE],["AverageTemperatureUncertainty", griddb.Type.DOUBLE],
["State", griddb.Type.STRING],["Country", griddb.Type.STRING], True)
cont = gridstore.put_container(info)
data = pd.read_csv("GlobalLandTemperaturesByState.csv")
#Add data
for i in range(len(data)):
ret = cont.put(data.iloc[i, :])
print("Data added successfully")Data added successfully
The read_sql_query function offered by the pandas library converts the data fetched into a panda data frame to make it easy for the user to work.
sql_statement1 = ('SELECT * FROM GlobalTemperatures.csv')
df1 = pd.read_sql_query(sql_statement1, cont)
sql_statement2 = ('SELECT * FROM GlobalLandTemperaturesByCity.csv')
df2 = pd.read_sql_query(sql_statement2, cont)
sql_statement3 = ('SELECT * FROM GlobalLandTemperaturesByState.csv')
df3 = pd.read_sql_query(sql_statement3, cont)Note that the cont variable has the container information where our data is stored. Replace the credit_card_dataset with the name of your container. More info can be found in this tutorial reading and writing to GridDB.
When it comes to IoT and Big Data use cases, GridDB clearly stands out among other databases in the Relational and NoSQL space. Overall, GridDB offers multiple reliability features for mission-critical applications that require high availability and data retention.
Using pandas read_csv
We can also use Pandas’ read_csv function to load our data. Both of the above methods will lead to the same output as the data is loaded in the form of a pandas dataframe using either of the methods.
global_temp_country = pd.read_csv('GlobalLandTemperaturesByCity.csv')global_temp_country.head()global_temp=pd.read_csv('GlobalTemperatures.csv')global_temp.head()GlobalTempState = pd.read_csv('GlobalLandTemperaturesByState.csv') GlobalTempState.head()Data Cleaning and Preprocessing
global_temp_country.isna().sum()dt 0
AverageTemperature 364130
AverageTemperatureUncertainty 364130
City 0
Country 0
Latitude 0
Longitude 0
dtype: int64
global_temp_country.dropna(axis='index',how='any',subset=['AverageTemperature'],inplace=True)def fetch_year(date):
return date.split('-')[0]
global_temp['years']=global_temp['dt'].apply(fetch_year)
global_temp.head()Analyzing with Data Visualization
Let’s calculate the average temperature for each country
avg_temp=global_temp_country.groupby(['Country'])['AverageTemperature'].mean().to_frame().reset_index()
avg_tempfig=px.choropleth(avg_temp,locations='Country',locationmode='country names',color='AverageTemperature')
fig.update_layout(title='Choropleth map of average temperature')
fig.show()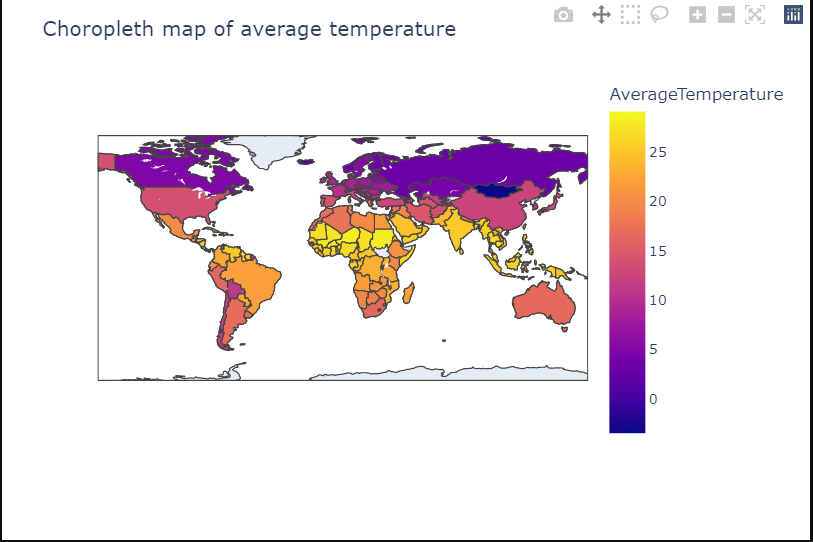
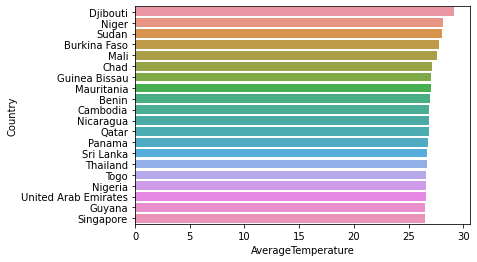
# The average temperature and Horizontal Bar sort by countries
sns.barplot(x=avg_temp.sort_values(by='AverageTemperature',ascending=False)['AverageTemperature'][0:20],y=avg_temp.sort_values(by='AverageTemperature',ascending=False)['Country'][0:20])<AxesSubplot:xlabel='AverageTemperature', ylabel='Country'>
Is there global warming?
data=global_temp.groupby('years').agg({'LandAverageTemperature':'mean','LandAverageTemperatureUncertainty':'mean'}).reset_index()
data.head()data['Uncertainty top']=data['LandAverageTemperature']+data['LandAverageTemperatureUncertainty']
data['Uncertainty bottom']=data['LandAverageTemperature']-data['LandAverageTemperatureUncertainty']fig=px.line(data,x='years',y=['LandAverageTemperature',
'Uncertainty top', 'Uncertainty bottom'],title='Average Land Tmeperature in World')
fig.show()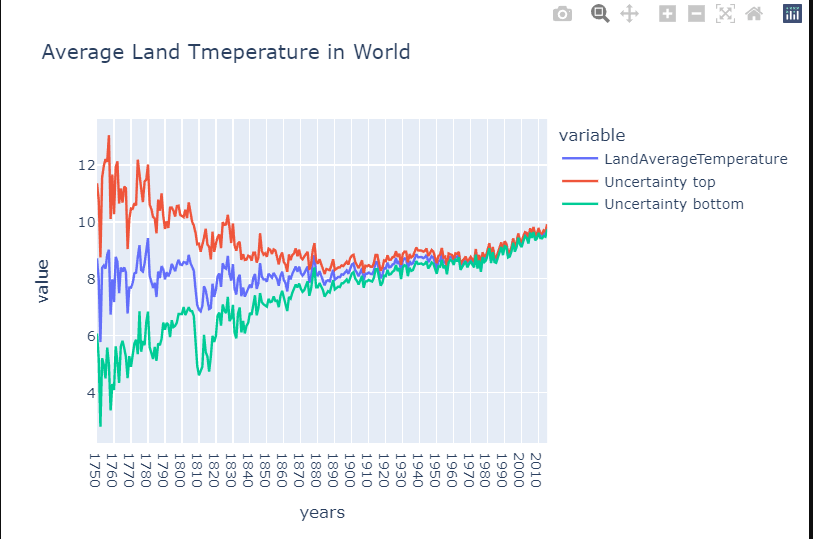
The charts show that there is currently global warming. The average temperature of the Earth’s surface has reached its highest level in three centuries. Temperatures have risen at the fastest rate in the last 30 years. This concerns me; I hope that humanity will soon fully transition to ecological energy sources, which will reduce CO2. We will be in trouble if it does not happen. This chart also includes confidence intervals, indicating that temperature measurement has become more accurate in recent years.
Average temperature in each season
global_temp = global_temp[['dt', 'LandAverageTemperature']]
global_temp['dt'] = pd.to_datetime(global_temp['dt'])
global_temp['year'] = global_temp['dt'].map(lambda x: x.year)
global_temp['month'] = global_temp['dt'].map(lambda x: x.month)
def get_season(month):
if month >= 3 and month <= 5:
return 'spring'
elif month >= 6 and month <= 8:
return 'summer'
elif month >= 9 and month <= 11:
return 'autumn'
else:
return 'winter'
min_year = global_temp['year'].min()
max_year = global_temp['year'].max()
years = range(min_year, max_year + 1)
global_temp['season'] = global_temp['month'].apply(get_season)
spring_temps = []
summer_temps = []
autumn_temps = []
winter_temps = []
for year in years:
curr_years_data = global_temp[global_temp['year'] == year]
spring_temps.append(curr_years_data[curr_years_data['season'] == 'spring']['LandAverageTemperature'].mean())
summer_temps.append(curr_years_data[curr_years_data['season'] == 'summer']['LandAverageTemperature'].mean())
autumn_temps.append(curr_years_data[curr_years_data['season'] == 'autumn']['LandAverageTemperature'].mean())
winter_temps.append(curr_years_data[curr_years_data['season'] == 'winter']['LandAverageTemperature'].mean())sns.set(style="whitegrid")
sns.set_color_codes("pastel")
f, ax = plt.subplots(figsize=(10, 6))
plt.plot(years, summer_temps, label='Summers average temperature', color='orange')
plt.plot(years, autumn_temps, label='Autumns average temperature', color='r')
plt.plot(years, spring_temps, label='Springs average temperature', color='g')
plt.plot(years, winter_temps, label='Winters average temperature', color='b')
plt.xlim(min_year, max_year)
ax.set_ylabel('Average temperature')
ax.set_xlabel('Year')
ax.set_title('Average temperature in each season')
legend = plt.legend(loc='center left', bbox_to_anchor=(1, 0.5), frameon=True, borderpad=1, borderaxespad=1)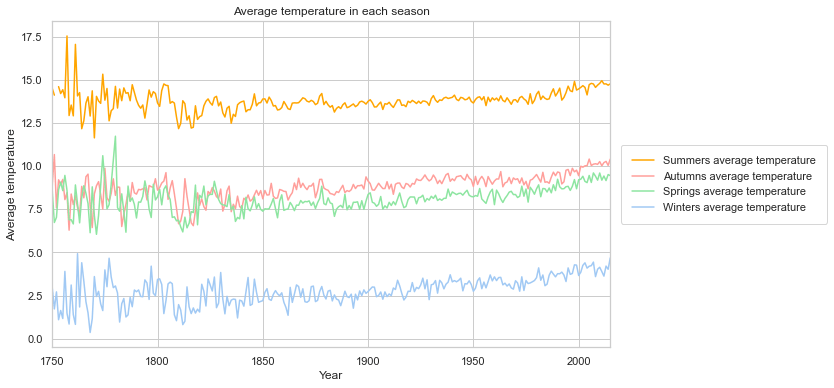
# Statewise scenario of average temperature.
country_state_temp = GlobalTempState.groupby(by = ['Country','State']).mean().reset_index().sort_values('AverageTemperature',ascending=False).reset_index()
country_state_temp
country_state_temp["world"] = "world"
fig = px.treemap(country_state_temp.head(200), path=['world', 'Country','State'], values='AverageTemperature',
color='State',color_continuous_scale='RdGr')
fig.show()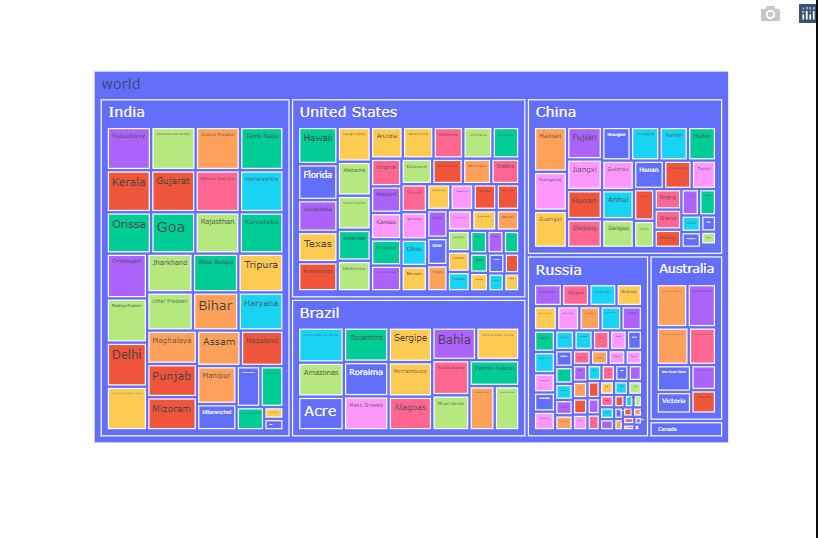
Conclusion
In this tutorial we analysed the global climate using Python and GridDB. We examined two ways to import our data, using (1) GridDB and (2) Pandas. For large datasets, GridDB provides an excellent alternative to import data in your notebook as it is open-source and highly scalable.