
The Autonomous Data Distribution Algorithm — or ADDA — is what makes GridDB both scalable and reliable. When a node fails or a user adds a new node to the cluster, ADDA transfers data between nodes ensuring nodes are balanced and that the configured number of data replicas are stored.
Node Failure
When a node fails, the cluster’s Master detects the failure and promotes all of the backup partitions to become partition owners. At this point, ADDA kicks in and instructs nodes to make replicas of partitions to ensure that the configured number of replicas are being stored.
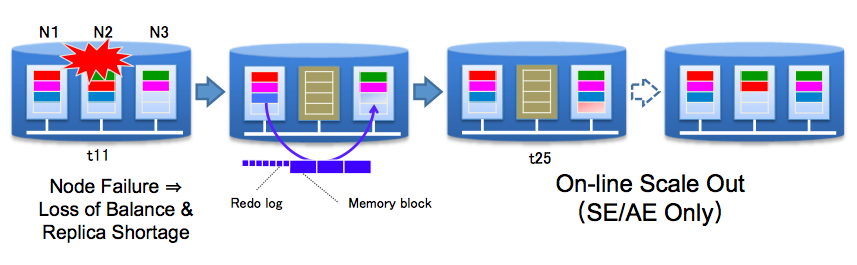
Adding a Node
When a new node is added, it enters the cluster as a catch up node for a certain partition. ADDA transfers data to it and it is promoted to backup node. Should the primary node holding that partition fail, it will be promoted again to the master node for a partition. With this mechanism, all the nodes in the cluster will have the same load allowing GridDB to be highly scalable.
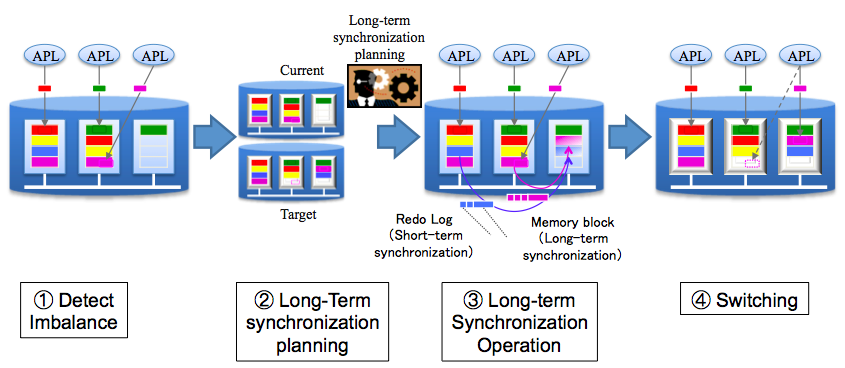
Two Phase Data Transfer To efficiently transfer data between hosts and not lose updates to the data transferred, ADDA transfers in two stages. First a high speed block transfer and then it applies Redo Logs.
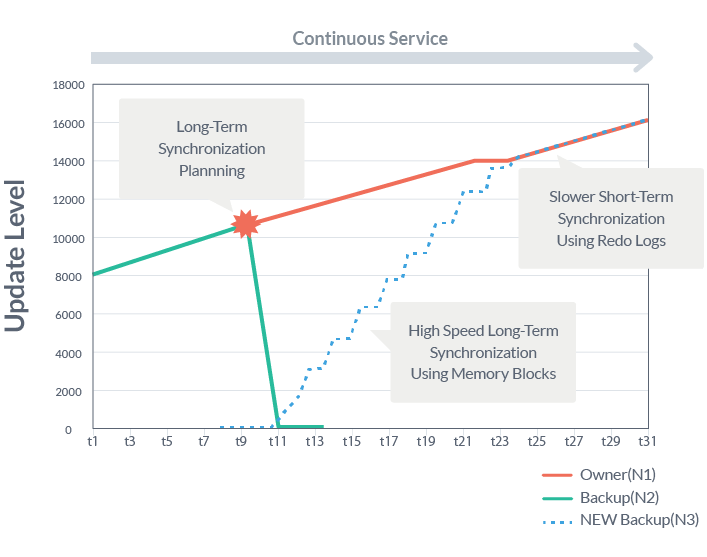
GridDB’s utilization of ADDA helps keep its large clusters operating reliably and help with on-the-fly scalability. If you would like to learn more about ADDA and the other features which maintain GridDB’s reliability, please take a look at our white paper linked below.
More Resources
![]() The full report can be downloaded here: https://griddb.net/en/docs/GridDB_Reliability_and_Robustness_1.0.7.pdf
The full report can be downloaded here: https://griddb.net/en/docs/GridDB_Reliability_and_Robustness_1.0.7.pdf
![]() The GridDB Community Edition (v3.0.0) can be downloaded from GitHub.
The GridDB Community Edition (v3.0.0) can be downloaded from GitHub.