1. What is CAP Theory?
When describing the characteristics of a particular database, the CAP theorem is often referred to, even including some of the materials found on this website. In this blog post, we will briefly review this fundamental theorem.
The CAP theorem was first proposed by Dr. Eric A. Brewer of the University of California, Berkeley in 2000. CAP, stands for:
Consistency:
For any read request, it returns a single latest data, otherwise an error is returned.
Availability:
The database always returns some value whenever there is a request — as long as the particular node is running.
Partition-tolerance:
Even if communication is temporarily interrupted, the system continues to function.
The CAP theorem says that no distributed computer system can simultaneously satisfy all three of these properties. Many NoSQL databases which feature scale-out, including GridDB, are distributed computer systems with multiple nodes, so partitioning tolerance is mandatory. As a result, a database on a distributed computer system can only achieve one of the following:
1. Guarantee Consistency and Partition-tolerance (CP), and give up Availability (A)
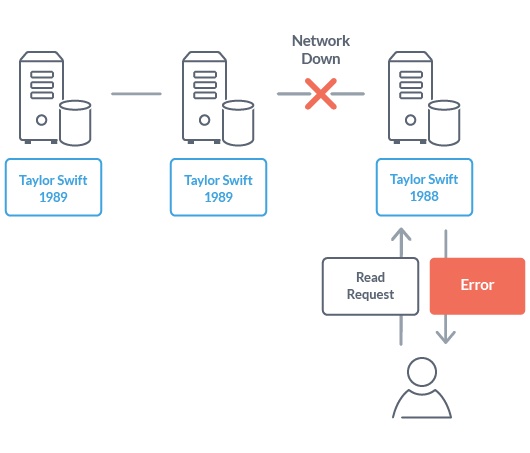
Suppose that the network on a distributed computer system building a database is blocked for some reason. In the case of a database that guarantees consistency (C), when a read request is received from the user, an error will be returned. This is because there is a possibility that the data on each node does not match while the network is shut down. In order to guarantee consistency, the database can not be used while the network is blocked, in other words, there is no availability.
Typical examples of NoSQL databases that guarantee CP are MongoDB, HBase, Redis.
2. Guarantee Availability and Partition-tolerance (AP), and give up consistency (C)
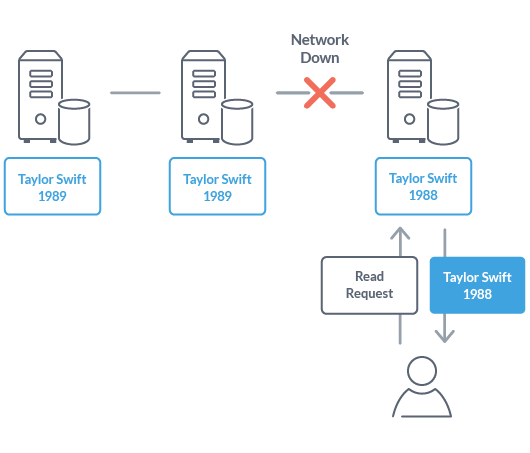
Now, imagine that same situation where the network is shut down again. For the database that guarantees availability (A), when a read request is received from the user in this situation, the information held by the inquired node is returned. This information may be different from the latest information held by other nodes, but it returns the best answer to maintain availability.
Typical examples of such a NoSQL database that guarantees APs include Cassandra and CouchDB.
2. CAP Theorem in real world
As mentioned above, the CAP theorem states that there are no databases that satisfy with “all” of C, A, and P properties “simultaneously”. Whether to adopt CP type or AP type is to be judged by the target application, but in the real world, consistency (C) and availability (A) are not all-or-nothing properties, but instead have several different levels of compliance. Most databases have some flexibility for each property in order to avoid the trade-off issue of C, A, and P.
For example, let’s assume that the network of the AP guaranteed database system is suddenly disconnected. Even if there is some time in which the data that each node houses temporarily does not match, we can still design a database that the entirety of data “eventually” matches. This is called eventual consistency, and is adopted in several NoSQL databases. A familiar example is DNS (Domain Name System) on the internet. When you modify a DNS recode due to a replacement of web server, it may take some time for the information to be added to DNS servers around the world, but everybody can continue to use DNS during the update. The consistency having a somewhat relaxed condition, like eventual consistency, is called “weak consistency”.
On the other hand, there are many ways to increase availability even in CP-type databases which have strict consistency (called “strong consistency”). For example, duplicating the communication path between each node consisting of a cluster is a very effective method that can increase availability without much time and cost.
3. GridDB is a “CP” Database
For GridDB, how is the trade-off of CAP theorem managed? GridDB is a CP type database with strong consistency.
Consistency is one of the most important properties for IoT applications. Please refer to Three Examples of GridDB in the IoT Industry blog.
In such use cases, there is a major problem if sensor values that should be the same are different depending on timing, no matter how high availability it has. If you use an AP type database, such sensor value inconsistency must be considered at the application level. It is necessary to deeply understand the process of value matching in the database in order to design an abnormal case of the application, and it should be a large burden on the developer.
In addition, although GridDB is CP type, it has various functions to ensure availability. Let’s introduce some distinctive features of GridDB to improve availability.
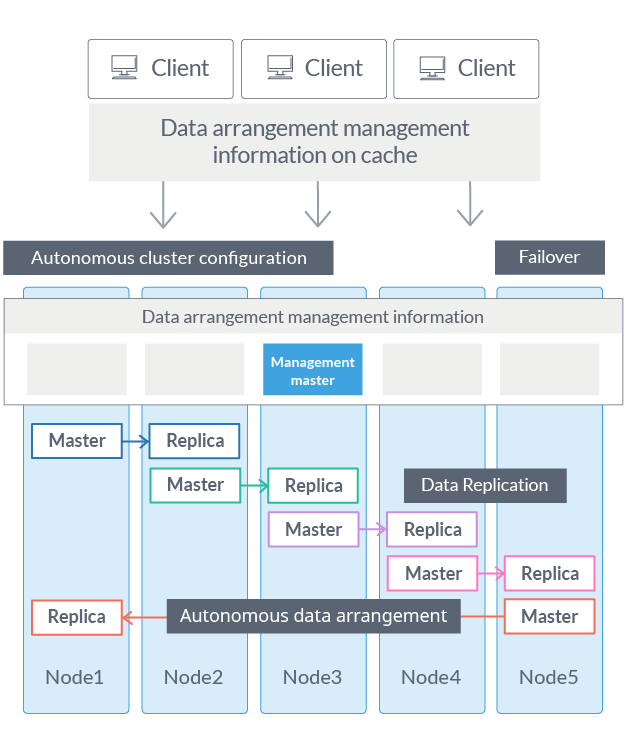
1. Automatic election of master node
GridDB’s cluster system is a so-called master-slave distributed database system with one master node and one slave node.
For a general master-slave system, there is a weak point where the master node becomes a single point of failure (SPOF), but in the case of GridDB, even if failure occurs in the master node, the system keeps working because one node is autonomously and dynamically selected from the slave nodes and promoted to a new master node. In addition, the new master node also automatically restores metadata that is essential for ensuring consistency, such as data placement status and update status. In other words, consistency will not be harmed even during recovery from failure, and service can always be continued as a CP type database.
2. Autonomous Data Distribution Algorithm (ADDA)
GridDB creates a replica of data in the cluster. If a node in the system is down, GridDB can continue processing by using the replica.
Although there are similar functions in a general distributed processing database, if a node constituting the system becomes unusable due to some kind of failure, the balance of the data of the remaining nodes temporarily collapses and the performance drops or the level of availability may drop due to lack of replica count.
GridDB monitors the data placement status of each node and has the function of redistributing data so that it automatically becomes the optimum state for the system when there is bias in placement. This minimizes the performance degradation time due to failures and maintains high availability levels. You can learn more details about ADDA in this blog post.
3. Client Failover
A failover function, which automatically switches to the standby node when a failure occurs, is adopted in many databases.
GridDB has failover functions not just on the server side, but it also has a cache of data placement management information on the client. As a result, when a client detects a node failure, it can automatically fail over and continue data access using the replica.