
Introduction
In a recent blog, we covered querying geospatial data with manual bounding boxes. In this blog, we’ll take the same dataset/query but perform the query using GeoHashes instead.
GeoHashes are alpha numeric encodings of areas on earth. The more bits in the encoding, the more precise the area is prescribing. A 1-digit long Geohash covers approximately 2500km while an 8-digit long Geohash covers approximately 20m. For example, the 9q geohash covers most of California and the Western United States while San Francisco / San Jose bay area is spread over several geohashes, 9qb, 9qc, 9q8, and 9q9.
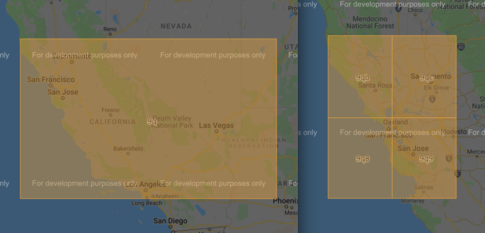
Geohashes are easily vizualized with several different tools such as this.
Java spatial4j GeoHashUtils
The ingest portion of our Geospatial app uses Java to read a New York Open Data’s Crime Complaint CSV file and load it into to GridDB. While there are several Geohash implementations for Java, we chose to demonstrate spatial4j’s GeoHashUtils as it appears to be the most popular with the largest developer community. The modifications to the previous Ingest tool are simple, instead of manipulating the latitude and longitude into a container name, we’ll use a 6-digit Geohash:
String cName = "geo_"+GeohashUtils.encodeLatLon(c.Latitude, c.Longitude, 6);A GEOHASH column is also added to the colum schema where a full 12-digit geohash is stored.
c.GEOHASH=GeohashUtils.encodeLatLon(c.Latitude, c.Longitude);Querying with Python and Proximity Hashes
There are many libraries that implement/utilize geohashes to allow developers to implement more featureful applications. One of these is Proximityhash which builds a list of geohashes that cover a circle around the provided point with the given radius. Proximityhash accepts a precision argument as well, denoting how many digits of a geohash should be created as well as a compression argument where it return fewer, less precise geohashes if they are completely within the radius of the search point.
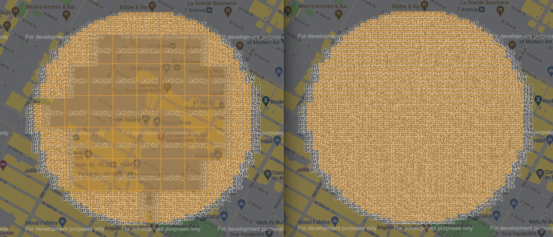
Using Proximityhash, we’ll now query the data we just loaded, first by getting a list of 6-digit geohashes to figure out which containers to query and then a list of geohashes that we’ll query in each container.
radius_hashes = proximityhash.create_geohash(lat, lon, distance, 8, georaptor_flag=True).split(',')
container_hashes = proximityhash.create_geohash(lat, lon, distance, 6, georaptor_flag=False).split(',')Now iterate through all of the containers building a TQL statement: SELECT * where geohash LIKE 'XXXXXXXX%' or geohash LIKE 'YYYYYYYY%' ....
There is some query optimization as well, only geohashes that are within the queried container are added to the TQL statement.
retval=[]
for container in container_hashes:
ts = gridstore.get_container("geo_"+container)
tql = "SELECT * WHERE "
orstmt=""
for geohash in radius_hashes:
if geohash.startswith(container):
tql = tql + orstmt + "geohash LIKE '"+geohash+"%'"
orstmt=" OR "
if orstmt != "":
try:
query = ts.query(tql)
rs = query.fetch(False)
while rs.has_next():
data = rs.next()
retval.append(data)
except:
passPerformance
We compared the performance of querying with varying precision geohashes against the manual bounding box method from our previous blog on geospatial querying.
| Description | Number of Geohashes | Duration (Seconds) |
|---|---|---|
| Manual Bounding Box | 0.005 | |
| 7-digit Geohash | 59 | 0.007 |
| 8-digit Geohash | 1522 | 0.15 |
| 8-digit Compressed Geohash | 468 | 0.030 |
With similar levels of precision, Geohashing is only slightly slower.
Conclusion
Geohashing is an easy implement method to use for querying geospatial data that does not require manual manipulation of data with minimal performance loss compared to other methods. The complete source code for this blog can be found on GridDB.net’s GitHub
I want to learn more about it