
1. What is Time Series data?
Time series data is a series of values ‹‹with time information (time stamp) that are generally recorded ‹‹at regular intervals. Specific examples of time series data include temperature recorded every set number of minutes or the closing price of a stock at the end of each trading day.
In an Internet of Things (IoT) application, a large amount of time series data is acquired from a variety of sensors such as a temperature sensor, a voltage sensor, an illuminance sensor, or an image sensor that records at intervals of a minute, a second, or even sub-second. A database is not absolutely necessary, but the following functions are usually required:
-
Store large amounts of streaming data.
-
Handle frequent data loss and reference data inconsistencies.
-
Data can be retrieved using either a time stamp or range.
-
Able to query the data using the sensor ID as a key. If these functions are provided the sensor data can be plotted in real time with the horizontal axis as time and used for monitoring purposes. The correlation of various sensor values ‹‹within a certain time period can also be examined with various analysis methods or visualizations.

Source: The Rossi X-ray Timing Explorer Learning Center, NASA
2. Storing Time Series Data With the requirements for storing Time series as described above, there are three practical methods one could use:
-
Flat file
-
Relational Database (RDB)
-
NoSQL Database
The primary benefit when simply saving data as a file is write performance. With any database you use, there is overhead that results in less throughput as compared with direct file writing. Therefore, if the data rate is large enough that a database is not able to keep up you can write the data directly as a file. Other advantages include no restrictions on how the data is to be handled; there is flexibility to handle anything that can be dropped into a file, either image data or numeric data. On the other hand there are disadvantages: it is necessary to manually manage the data records, it is complicated to organize the data and it is difficult to efficiently create complex queries.
The maximum benefit when saving data with a Relational Database is that ACID characteristics (Atomicity, Consistency, Isolation, Durability) are guaranteed in transactions. In addition, when processing acquired data, complicated queries can be easily performed using a standard SQL statement. The disadvantage of a RDB is that it is difficult for the database to scale out due to rigorous processing and indexing and consistency issues. Since the internal indexing of data is based on previous definitions it is necessary to decide the schema (the structure of the database) in advance which is then difficult to change if requirements evolve. In other words, it is often inappropriate to hold a large amount of data from various sensors over the long term.
NoSQL stands for “Not only SQL”, as its name implies, it is a database to overcome the limitations of RDBs based on SQL. The simplest NoSQL database is called a key / value store that stores one “value” per “key”. It is not as simple as writing a file but it features fast writing and reading. Unlike an RDB, it is possible to handle “unstructured data” where different keys have different types of data. Performance and flexibility have been improved but some of the functionality of RDB is lost. Depending on the database, SQL like statements are either not supported or there are restrictions on functions. NoSQL do not usually have support for strict transactions with ACID characteristics. This is to allow the database to scale out easier, but some NoSQL databases are ACID compliant with some restrictions.
Although the relationship between strict data management and high-speed operation is a trade-off in the three data storage methods, acquisition of time-series data from the IoT application has high-speed write / read performance, even if the function is not so large, a NoSQL database which is provided with a certain degree of data retrieval / retrieval method is best.
3. Why GridDB?
GridDB is a type of NoSQL database, but it has unique features that make it ideal for IoT applications and Time Series data not found in other NoSQL databases. The features will be explained in detail below.
Key-Container Type
Different NoSQL databases have different data models such as the key-value type (Riak), column-oriented type (Cassandra), and document-oriented type (MongoDB). However, considering the use case of acquiring time-series data from a large number of sensor devices, there is dissatisfaction with the existing data models. For example, key-value type is too simple and it is difficult to manage consistent data in a management group such as device unit or sensor unit. GridDB adopts a key-container type as a new data model. Containers referenced by a key manage data in-table which can define a schema and you can set an index on a column. In other words, the container itself can be handled like a general RDB and you can perform transaction processing with guaranteed ACID characteristics as well using SQL-like queries (TQL).
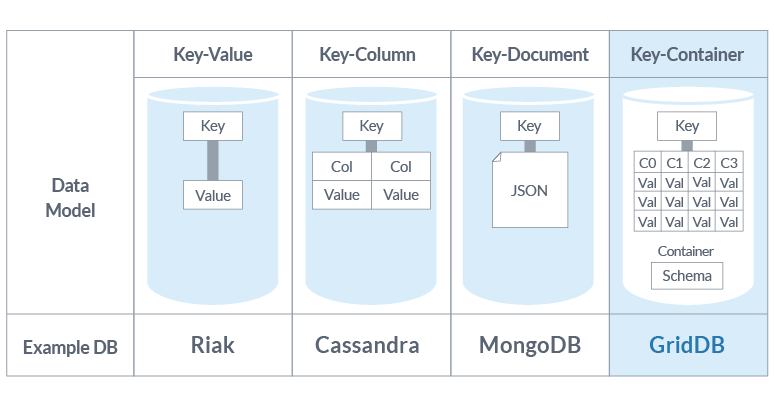
Time Values as a Key
GridDB has a special “Time Series Container” dedicated to storing time series data. Using this container, you can run queries with the keys, delimit time intervals, or automatically delete data past a certain age, among other special API calls.
Ultra High Speed In-Memory Architecture
Processing speed is the greatest advantage of a NoSQL database and GridDB is one of the fastest NoSQL databases. The secret to GridDB’s high performance is the design philosophy of “processing as many operations in memory as possible”. In-memory databases are simple if data is only stored in memory, but in order to process a large amount of data they must also be able to access data on disk as well. The data accessed by the application is localized to reduce disk access as much as possible. In order to localize data access, GridDB provides the function of placing related data together in the same block. By giving hint information about the data, GridDB will aggregate data blocks based on the hints so memory access misses are reduced which further improves performance.
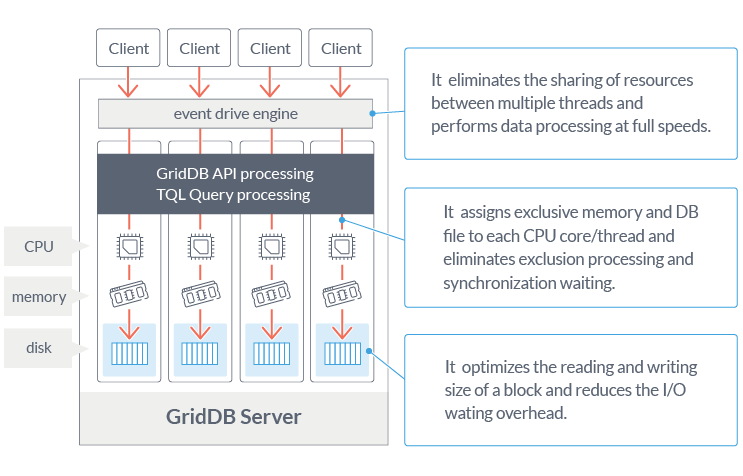
GridDB’s key-container type data model, high performance and specialized time functions are designed and implemented to “efficiently process large amounts of time series data”. In future blog posts, we’ll provide more background on how to effectively use GridDB’s TimeSeries, but until then, please try using GridDB and see how it can improve an existing or new application. Community Edition is Apache licensed making it ready for all projects, small or large.
If you have any questions about the blog, please create a Stack Overflow post here https://stackoverflow.com/questions/ask?tags=griddb .
Make sure that you use the “griddb” tag so our engineers can quickly reply to your questions.