
There are two methods for improving the performance of a database: “Scale Up” and “Scale Out”. “Scale up” is to improve the standalone performance of the server on which the database is running. Specifically, it is possible to add memory, add a CPU, or use an SSD. On the other hand, “scale out” is intended to improve performance by increasing the number of servers.
Each method has advantages and disadvantages, but there are physical limits to the performance improvement via scaling-up. In the case of scale-out, you can keep adding servers as necessary. Even if the data volume increases exponentially, a scale-out database can continue to scale with it, but the performance of the database must be proportional to the number of servers. A system improving the overall throughput in proportion to the amount of hardware resources is called a system with scalability. Scalability is a very important factor in IoT applications where the amount of data or the number of clients increases everyday.
For conventional relational databases, it is difficult to improve performance by scaling-out, which essentially means they are not scalable. There are so many NoSQL databases on the market, but a common feature among most NoSQL databases is very high scalability due to simplicity of processing and the data structure. (eg. Performance evaluation of NoSQL databases, A . Gandini, et. al., RDBMS vs NoSQL: Performance and Scaling Comparison, Christoforos Hadjigeorgiou )
GridDB boasts particularly high scalability, even when compared to other NoSQL databases. As shown in the figure below, we have confirmed that the performance is linearly improved with an addition of servers — up to 32 nodes. For complete details on how GridDB was tested, please refer to this white paper.
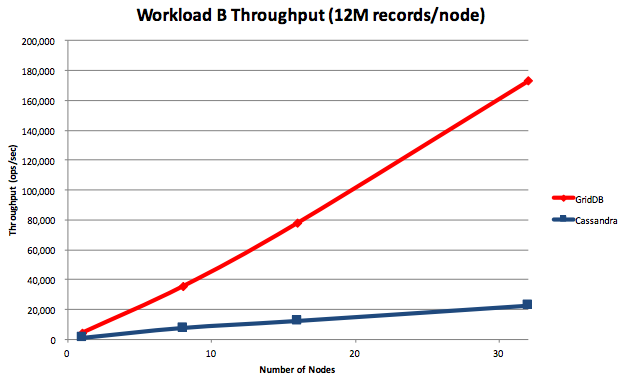
Another consideration when improving database performance or capacity by scaling-out is the availability when adding a server. Regardless of how scalable the database is, if the service needs to stop when expanding the cluster, careful planning becomes necessary. With GridDB, system expansion can be handled without any suspension of the system(*). Data is automatically distributed to the new node(s) according to the load of the system with the Autonomous Data Distribution Algorithm (ADDA). Since ADDA performs the load balance, it is unnecessary for administrators to be concerned about data allocation.
* This function is supported by GridDB Enterprise Edition. 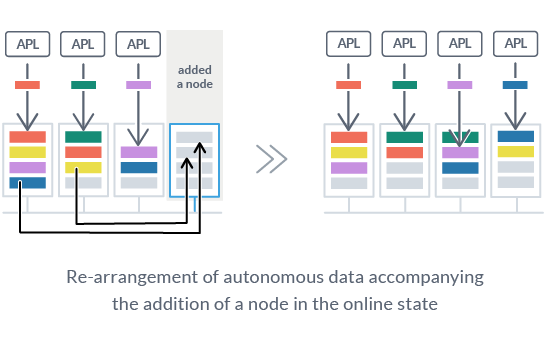
Being able to improve performance at any time without stopping service makes scalability one of GridDB’s best features. You can start with a small configuration and expand quickly, easily, and predictably, as required. Multi-node clustering is available in the commercial version of GridDB; please visit the GridDB commercial site for more details.