
概要
このチュートリアルでは、Pythonを使って、機械学習モデルをWeb APIにしてリアルタイム予測を行う方法を紹介します。概要は以下の通りです。
- 前提条件と環境設定
- 機械学習モデルを作成する
- 機械学習モデルのシリアル化と非シリアル化
- PythonのFlaskを使ってAPIを開発する
- リアルタイム予測を作成する
前提条件と環境設定
このチュートリアルは、Windows オペレーティングシステム上の Anaconda Navigator (Python version – 3.8.3) を使います。チュートリアルを進める前に、以下のパッケージをインストールしてください。
- Pandas
- NumPy
- Scikit-learn
- Flask
- Joblib
これらのパッケージをCondaの仮想環境にインストールするには、conda install package-nameを使用します。ターミナルやコマンドプロンプトで直接Pythonを使用する場合は、pip install package-nameでインストールできます。
なお、PythonでGridDBのデータベースにアクセスするためには、以下のパッケージが必要となります。
- GridDB C-client
- SWIG (Simplified Wrapper and Interface Generator)
- GridDB Python-client
これで、環境がすべて整い、使える準備ができました。それでは、機械学習モデルを作成してみましょう。
機械学習モデルを作成する
ここでは、過去のブログで紹介したMachine Learning using GridDBのLinear Regressionモデルを使用します。完全なソースコードはGithubにあります。新しい変更点を反映させるために、コードを修正していきます。ソースコードをダウンロードしてフォローすることもできます。このチュートリアルの最後にpythonファイルを添付しています。
CalCOFIデータセットの線形回帰モデルは以下のようになります。
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
import joblib
dataset = pd.read_csv("bottle.csv")
dataset=dataset[["Salnty","T_degC"]]
dataset = dataset[:500]
dataset=dataset.dropna(axis=0)
dataset.reset_index(drop=True,inplace=True)
x_label=np.array(dataset['Salnty']).reshape(493,1)
y_label=np.array(dataset['T_degC']).reshape(493,1)
x_train, x_test, y_train, y_test = train_test_split(x_label, y_label, test_size = 0.2, random_state = 100)
regression_model=LinearRegression()
regression_model.fit(x_train,y_train)なお、テストデータセットの予測を行っている最後の数行は、ここでは必要ないので削除しています。前のブログで説明したように、モデルの精度は 87% です。得られたモデルをプロットすると、以下のようになります。
plt.figure(figsize=(12,10))
plt.scatter(x_label, y_label, color='aqua')
plt.plot(x_train, regression_model.predict(x_train),linewidth="4")
plt.xlabel("Temperature",fontsize=22)
plt.ylabel("Salinity",fontsize=22)
plt.title("Linear Regression",fontsize=22)
機械学習モデルのシリアル化と非シリアル化
これでモデルが予測できるようになりましたが、サーバーからリクエストを受けるたびに同じ手順を実行しなくて済むように、学習したモデルを保存しておく必要があります。このようにPythonオブジェクトをバイトストリームに格納し、後で利用できるようにするプロセスをシリアル化といいます。非シリアル化は、その名の通り、シリアル化の逆で、バイトストリームをPythonオブジェクトに戻すことを言います。Pythonのシリアル化と非シリアル化はjoblib, pickleなどのパッケージを介して行うことができます。
それでは、モデルを保存してみましょう。
joblib.dump(regression_model, 'regression_model.pkl')
print('Model dumped')
regression_model = joblib.load('regression_model.pkl')
regression_model_columns = list(x_train)
joblib.dump(regression_model_columns, 'regression_model_columns.pkl')これらのコードスニペットを追加した後のファイルは、最終的に以下のようになります。
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
import joblib
dataset = pd.read_csv("bottle.csv")
dataset=dataset[["Salnty","T_degC"]]
dataset = dataset[:500]
dataset=dataset.dropna(axis=0)
dataset.reset_index(drop=True,inplace=True)
x_label=np.array(dataset['Salnty']).reshape(493,1)
y_label=np.array(dataset['T_degC']).reshape(493,1)
x_train, x_test, y_train, y_test = train_test_split(x_label, y_label, test_size = 0.2, random_state = 100)
regression_model=LinearRegression()
regression_model.fit(x_train,y_train)
joblib.dump(regression_model, 'regression_model.pkl')
print('Model dumped')
regression_model = joblib.load('regression_model.pkl')
regression_model_columns = list(x_train)
joblib.dump(regression_model_columns, 'regression_model_columns.pkl')次に、同じディレクトリに regression_model.py を保存しましょう。このコードをコマンドラインで実行するには、python regression_model.pyと入力します。実行後のディレクトリ構造は以下のようになります。
ターミナルやコマンドプロンプトでファイルを実行する場合は、ipynbファイルはオプションです。 これでモデルが保存され、リアルタイム予測を行うためのAPIを作成する準備が整いました。
PythonのFlaskを使ってAPIを開発する
まず、モデルをインポートして、アプリケーションの起動時にpythonオブジェクトに変換します。それには、次のようなコードが必要です。
lr = joblib.load("regression_model.pkl")
print ('Model loaded')
model_columns = joblib.load("regression_model_columns.pkl")
print ('Model columns loaded')次に、リクエストを積極的に受け付けるAPIエンドポイントを作成し、リクエストをPythonオブジェクトで処理して、予測を行うモデルに渡す必要があります。また、入力が望ましいJSONフォーマットでない場合のランタイム例外にも対応する必要があります。以下のスクリプトでそれを行います。
@app.route('/predict', methods=['POST'])
def predict():
if lr:
try:
json_ = request.json
query = pd.DataFrame(json_)
print(query)
prediction = list(lr.predict(query))
return jsonify({'prediction': str(prediction)})
except:
return jsonify({'trace': traceback.format_exc()})
else:
print ('Train the model first')
return ('No model here to use')デフォルトでは、flaskアプリケーションは http://127.0.0.1:5000 で実行されます。実行時にユーザーが特定のポート番号を提供したい場合は、この設定をカスタマイズしましょう。コンパイルされたファイルは次のようになります。
from flask import Flask, request, jsonify
import joblib
import traceback
import pandas as pd
import numpy as np
import sklearn
# Your API definition
app = Flask(__name__)
@app.route('/predict', methods=['POST'])
def predict():
if lr:
try:
json_ = request.json
query = pd.DataFrame(json_)
print(query)
prediction = list(lr.predict(query))
return jsonify({'prediction': str(prediction)})
except:
return jsonify({'trace': traceback.format_exc()})
else:
print ('Train the model first')
return ('No model here to use')
if __name__ == '__main__':
try:
port = int(sys.argv[1])
except:
port = 12345
lr = joblib.load("regression_model.pkl")
print ('Model loaded')
model_columns = joblib.load("regression_model_columns.pkl")
print ('Model columns loaded')
app.run(port=port, debug=True)load()関数では,すべてを同じディレクトリに保存しているため,ファイル名だけを指定していることに注意してください。コンパイル時に FileNotFoundError が発生した場合には,代わりにフルパスを指定してください。
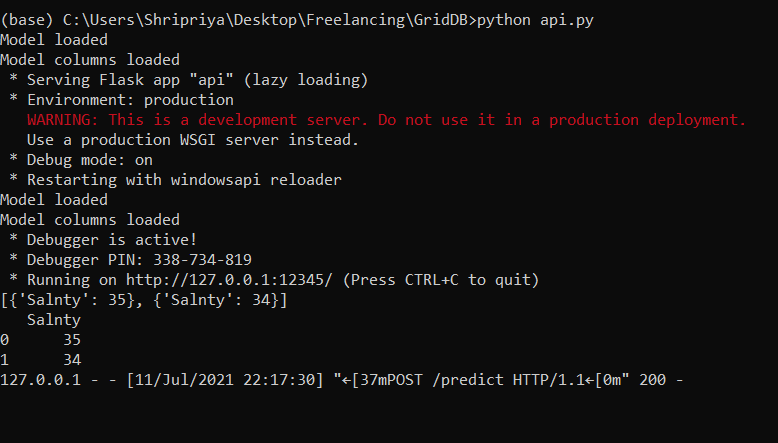
このファイルをコンパイルして、すべてが正しく動作しているかどうかを確認してみましょう。次のような出力が得られました。
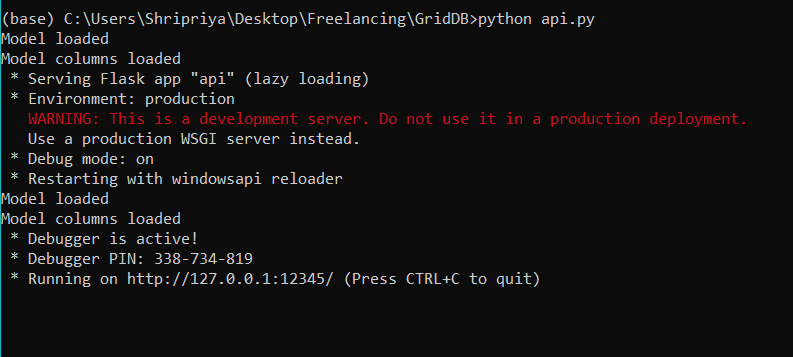
これは、このサーバーが http://127.0.0.1:12345 でアクティブになったことを意味します。次に、サードパーティのアプリケーションで、サーバーにリクエストを送り、どのような出力が得られるかを確認します。
リアルタイム予測を作成する
サーバーへのリクエスト送信には、Postman’s Desktop applicationを使用します。APIテスト用のツールはいくつかあるので、好きなものを使ってください。コンソールは通常以下のようになります。
以下のように変更してみましょう。
- メソッドを
POSTに変更する Bodyタブで、リクエストフォーマットとしてrawとJSONを選択する。- 入力を
[{"Salnty":34}, {...}]のようなリストとして渡す。 Sendを押す。
注意点
api.pyは、バックグラウンドで実行される必要があります。そうしないと、サーバーがアクティブにならず、コンソールにエラーが表示されます。- 今回送る入力は、リストと辞書を組み合わせて使うJSON形式です。そのため、入力は
{key: value}のペアで渡すことが重要です。複数の属性がある場合には、入力は{"attribute1": value1, "attribute2": value2, ...}のようになります。
次のような出力がコンソールに表示されます。
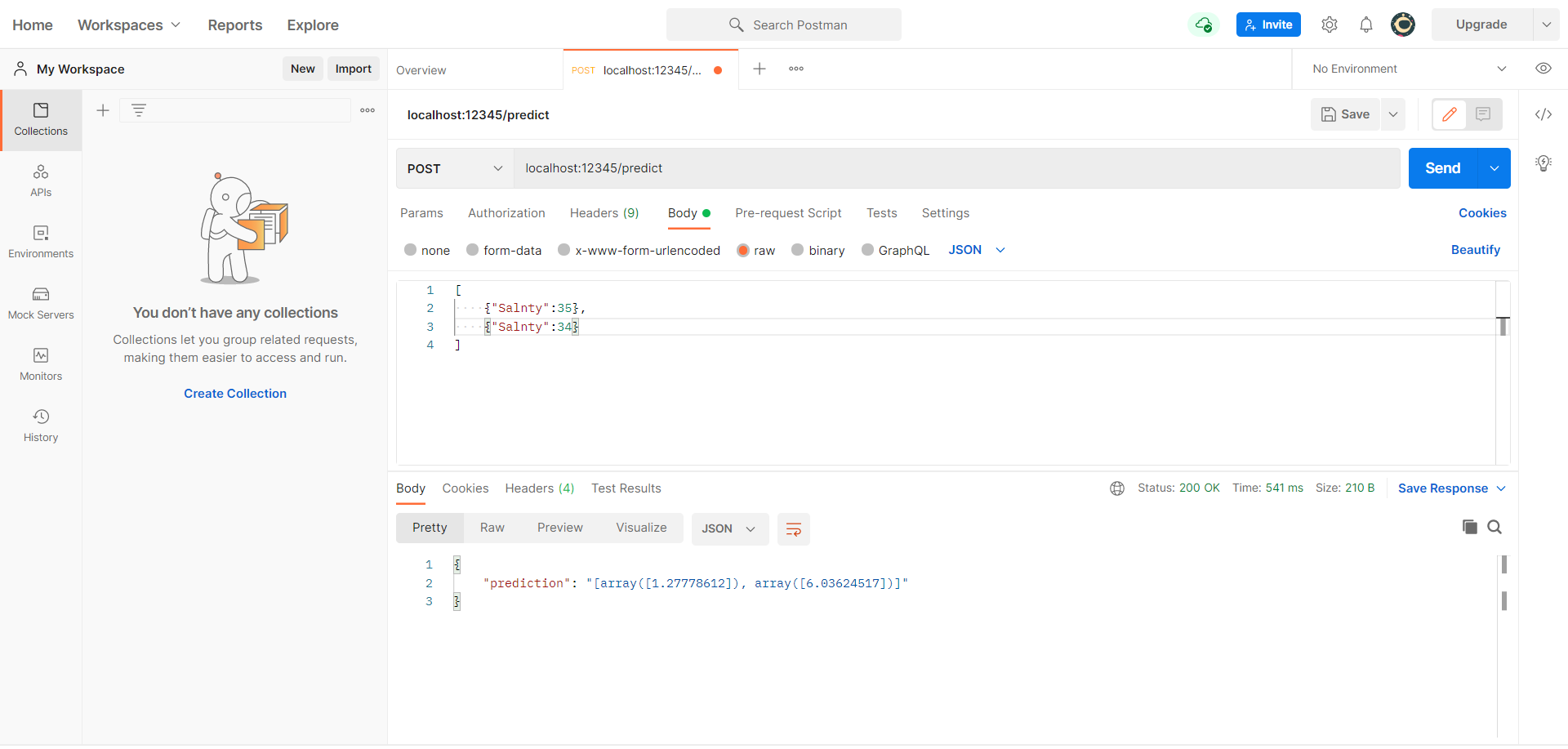
Postmanコンソールから得られた入力を再確認するために、ターミナルをチェックしてみましょう。以下のようなJSONクエリが出力されているはずです。
これで、機械学習モデルを展開して、リアルタイムで予測を行うことができました。私たちのウェブページの関連記事についてもご覧ください。