Introduction
Fixstars recently performed benchmarks that compared time series databases GridDB and InfluxDB using one AWS instance with a CentOS 6.9 image. The tests were done using YCSB-TS framework, a fork of YCSB benchmarking tool meant for testing Time Series databases. The tests were ran with two datasets: one which could be held primarily in-memory (100M records) and one that would require performing disk I/O (400M records).
Benchmark Results
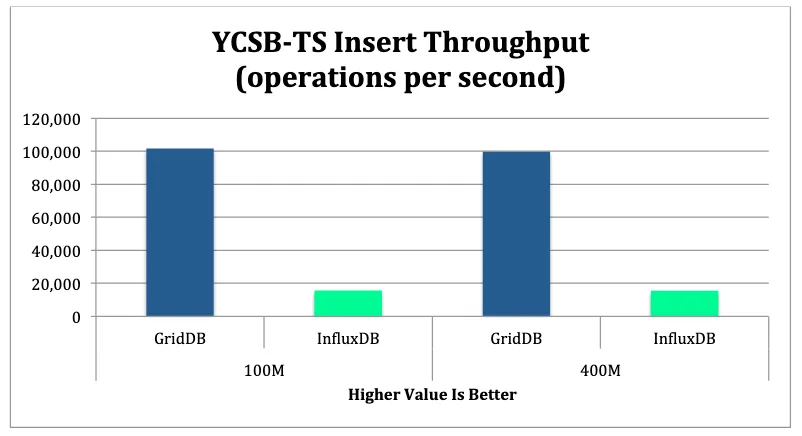
GridDB’s in-memory oriented architecture outperformed InfluxDB by a noticeable margin. The results provide strong evidence of GridDB being the stronger Time Series database. GridDB provided superior performance in both in-memory and out-of-memory operations. Results are shown below.
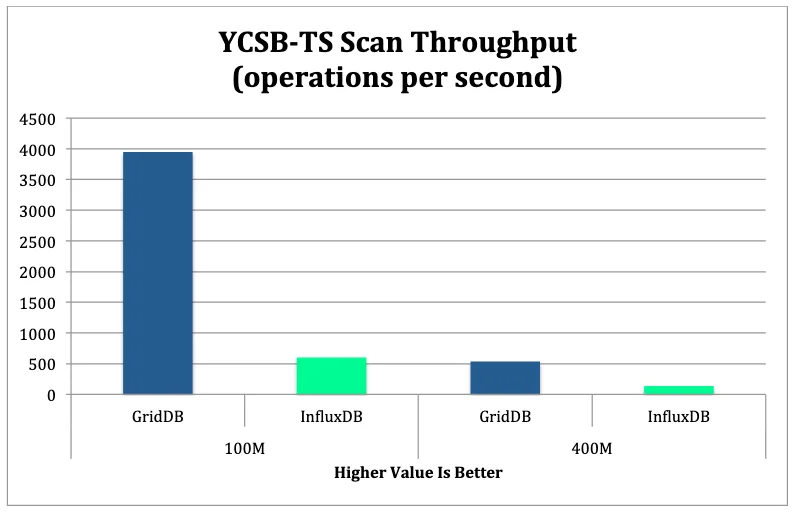
GridDB proved to be much more scalable than InfluxDB when the size of the database rose from 100M to 400M records. GridDB was able to maintain the same relative LOAD throughput through this increase. As the size of the database grew, GridDB’s LOAD throughput was also over 6 times higher than InfluxDB. GridDB’s read throughput dropped by around 74% while InfluxDB’s throughput dropped by over 81%. When comparing scan performance, GridDB’s throughput dropped by 60% while InfluxDB’s throughput dropped by over 75%.
It is also important to note that on average GridDB used less CPU resources than InfluxDB while still managing to provide higher throughput and lower latencies in query (read and scan queries) operations.
Read Performance
The read phase of our testing on YCSB-TS performed a series of read queries that would search for rows with a specific TIMESTAMP key. These timestamp keys would be generated by YCSB-TS.
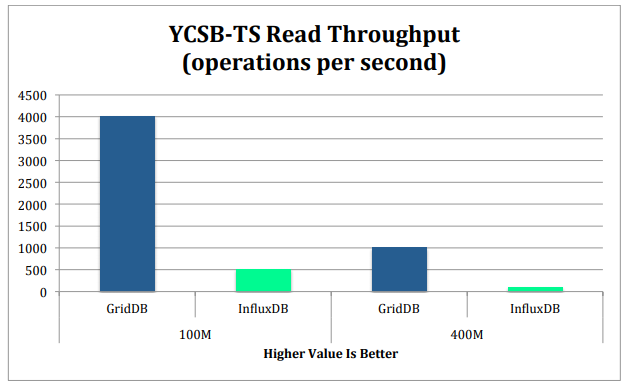
When comparing read operations using the 100M record dataset, GridDB had over 8 times the throughput than that InfluxDB. For the 400M record dataset, GridDB had up to 10 times the throughput of InfluxDB. It should also be noted that GridDB had around 10-11% the latency of InfluxDB for read operations.
Scan Performance
The scan workload would perform a series of general Scan queries or aggregation queries such as AVERAGE, SUM, and COUNT. All scan operations would use a random time-range generated by YCSB-TS.